Transformer系列:1. 从RNN到Transformer
场景:
- 图像信息:任务为理解图像内容,采用卷积神经网络;
- 序列信息:任务为理解语音/文字/视频,采用循环神经网络。
对于序列信息,由于按时序输入的数据之间非独立,前后数据之间具备相关性,因此网络需要存储信息的能力。
RNN
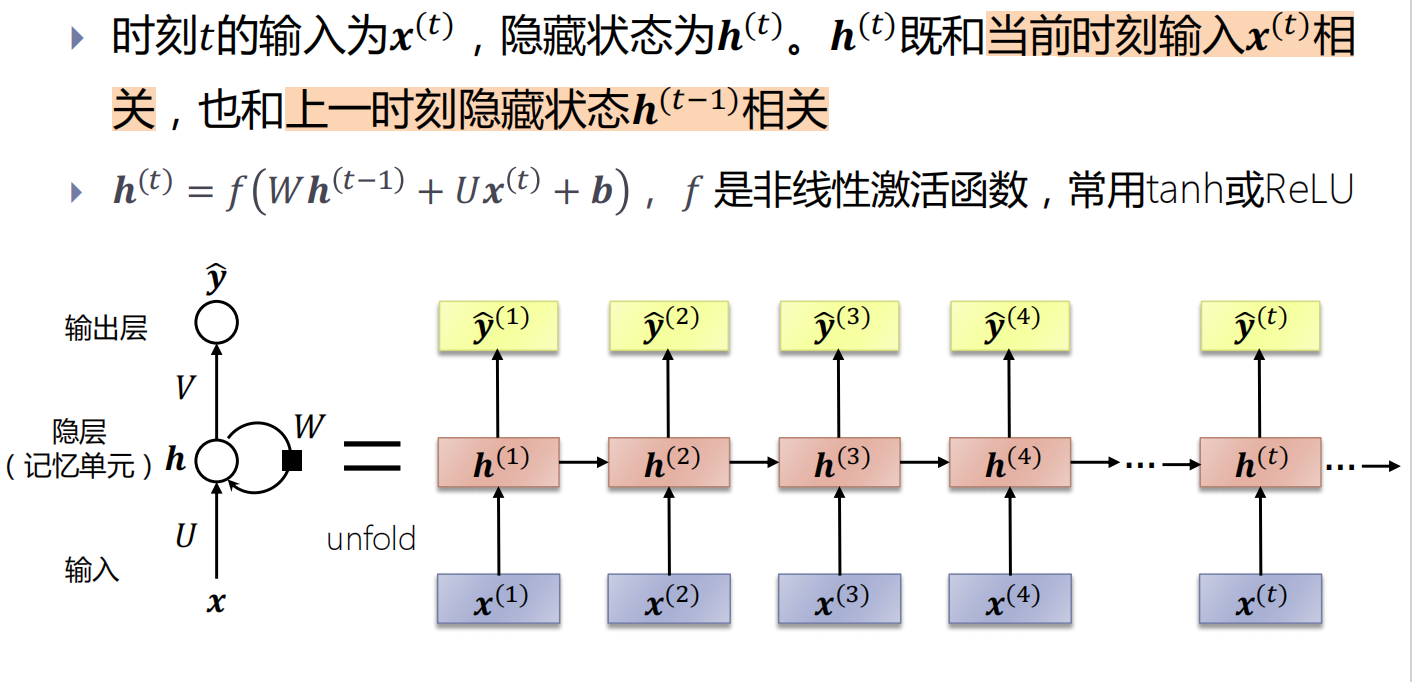
网络结构
RNN通过使用带自反馈的神经元,能够处理任意长度的序列

时序sequence:RNN能建模序列数据,序列指的是前、后输入数据\((x^{(t)}, x^{(t+1)})\)不独立,相互影响;
循环recurrent:对每个输入的操作都是一样的,循环往复地重复这些相同操作,每时刻有相同参数W和U(参数共享);
记忆memory: 隐藏层\(h_{(t)}\)中捕捉了所有时刻t之前的信息,理论上\(h_{(t)}\)记忆的内容可以无限长,然而实际上记忆还是有限的;
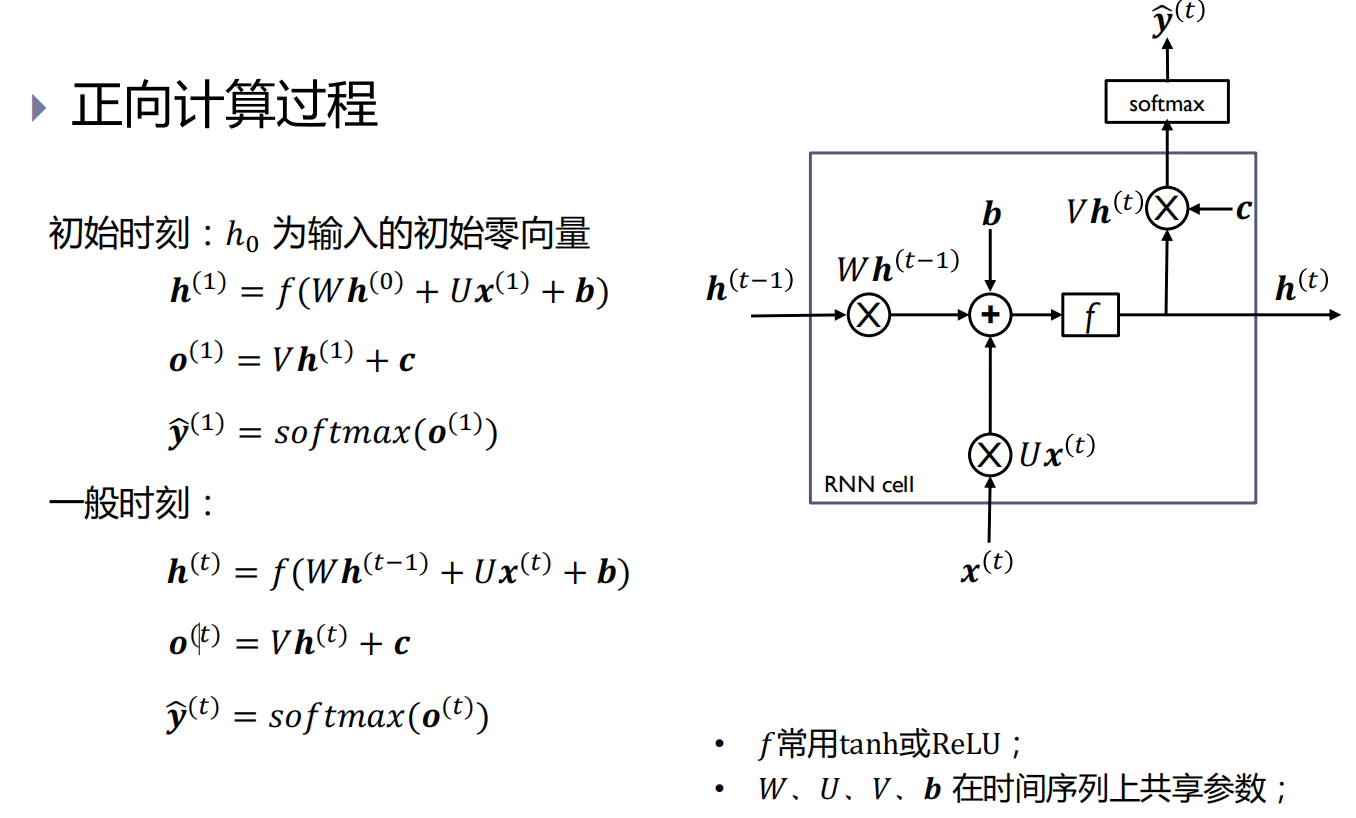
正向计算
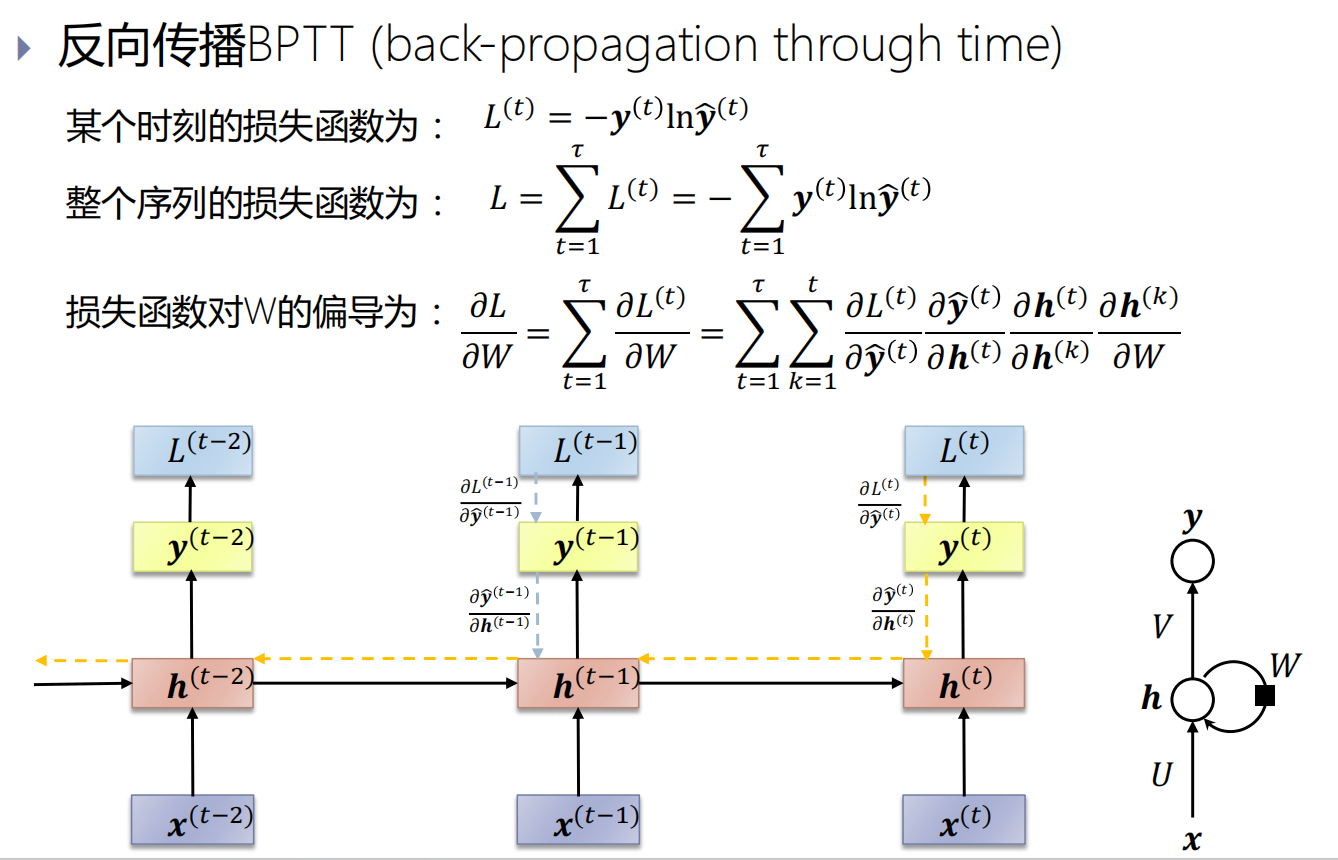
反向传播BPTT
梯度消失 / 梯度爆炸
循环神经网络的递归结构,导致梯度消失/梯度爆炸现象更明显
梯度爆炸:可采用梯度截断解决
由于梯度消失,RNN无法处理长期依赖关系。
比如,考虑一个语言模型,试图根据之前单词预测下一个;
如果要预测“The clouds are in the sky”中最后一个单词,不需要更多的上下文即可知道下一个单词会是“sky”。在这种情况下,相关信息与预测位置的间隔比较小,RNNs可以学会使用之前的信息;
考虑试图预测“I grew up in Italy… I speak fluent Italian.”中最后一个,则需要用到包含“Italy”的上下文,从前面的信息推断后面的单词。相关信息与预测位置的间隔可能会很大。随着这种间隔的拉长,RNNs就会无法学习连接信息。
发展历程
Simple RNN -> Contextualize RNN -> Contextualized RNN with attention -> Transformer(2017)
Simple RNN
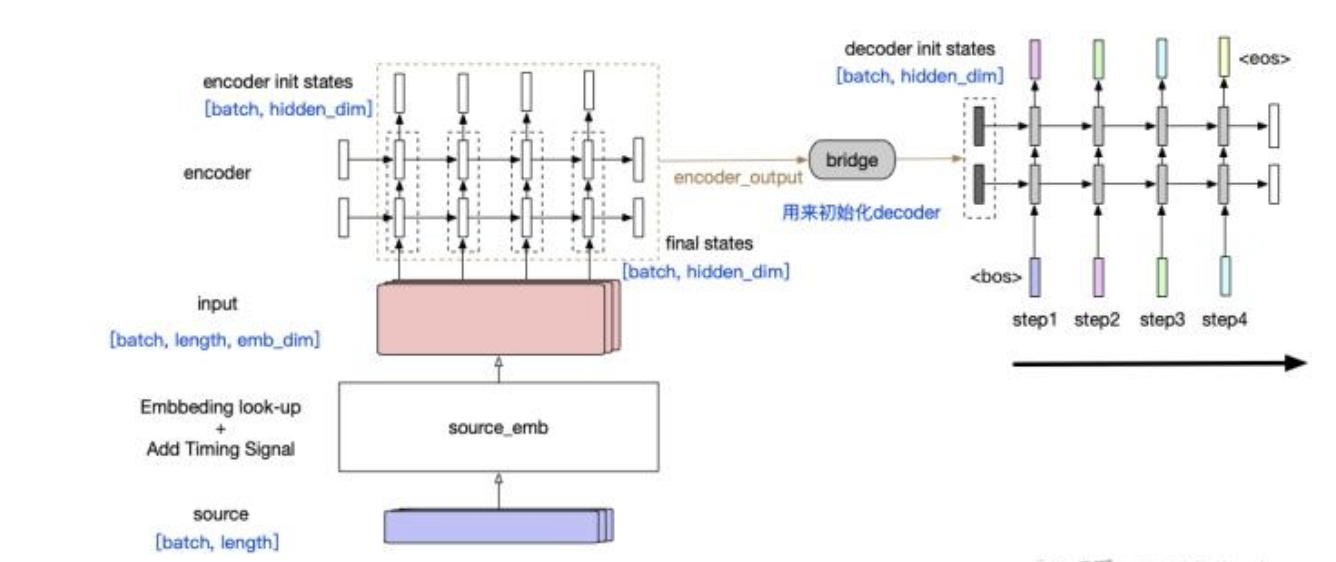
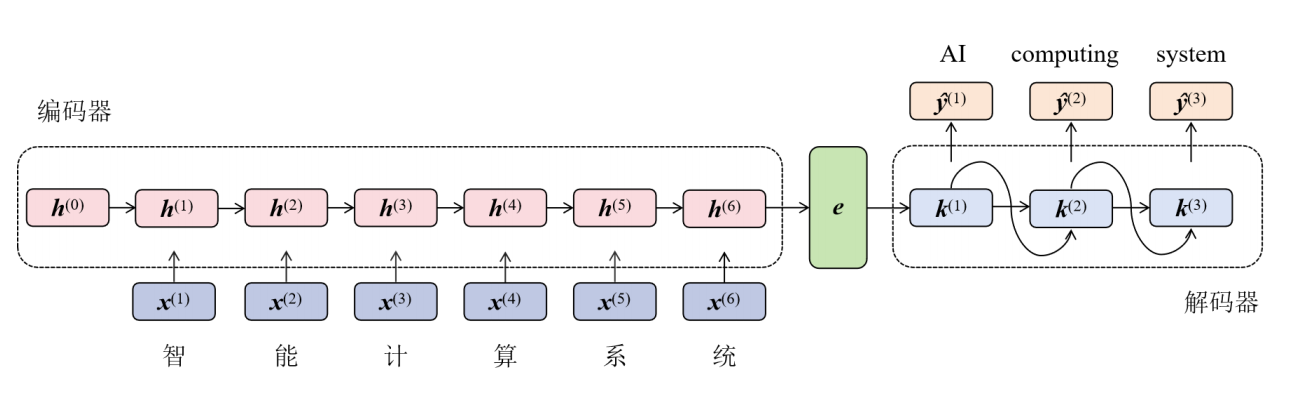
RNN Encoder-Decoder:
出现背景:传统RNN架构仅适用于输入输出等长的任务;RNN Encoder-Decoder使用一个定长状态机作为输入输出桥梁,以实现对输入输出都是变长序列的处理。
处理过程:
- Encoder:
- 逐个读取输入序列的token,计算隐状态:
\[ h_{<t>}=f(h_{<t-1>}, x_t) \]
- 从输入序列的第二个token开始,Encoder每个时刻的输入包括:上一个时刻的隐状态+当前token
- Encoder最后一个时刻的隐状态为:一个固定长度的高维特征向量\(C=(z_1, ..., z_T)\),编码了整个输入序列的语义上下文。
- Decoder:通过给定的隐状态\(h_{<t>}\),预测下一个token \(y_t\),最后生成输出序列。
计算当前时间\(t\)时的隐状态: \[ h_{<t>}=f(h_{<t-1>}, y_{t-1}, c) \]
下一个token的条件概率分布为: \[ P(y_t|y_{t-1}, y_{t-2}, ..., y_1, c)=g(h_{<t-1>}, y_{t-1}, c) \]
Encoder-Decoder联合训练,最大化条件对数似然函数: \[ \max\limits_{\theta} \frac{1}{N}\sum_{n=1}^{N}\log p_{\theta}(y_n|x_n) \] 其中,\(\theta\)为模型参数的集合,每个\((x_n, y_n)\)是训练集中的(输入序列,输出序列)对。
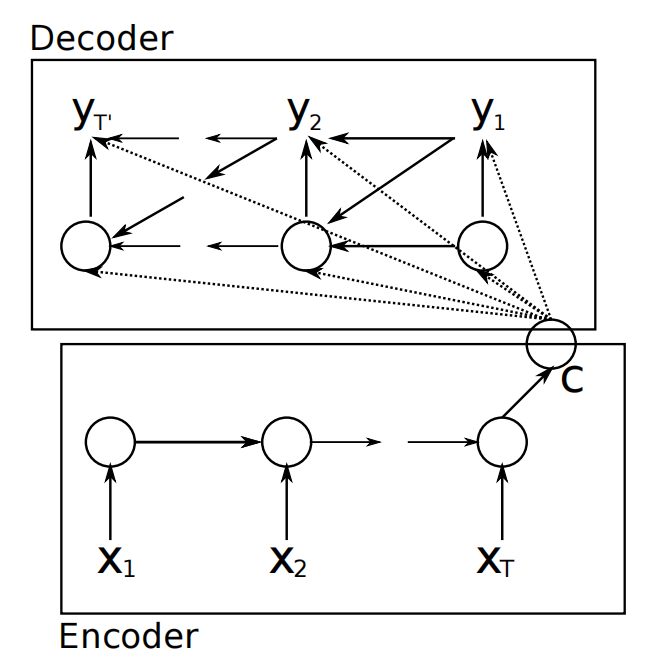
思想:将长序列的上下文,压缩到一个较小的状态中
有两个问题:
- encoder将整个源端序列(不论长度)压缩为一个固定维度的向量(encoder output):并且这个向量中包含的信息中,关于源端序列末尾的token的信息更多,因此如果序列很长,最终可能基本上“遗忘”了序列开头的token的信息;
- 随着decoder timestep的信息的增加,initial hidden states中包含的encoder output相关信息也会衰减:decoder会逐渐“遗忘”源端序列的信息,而更多地关注目标序列中在该timestep之前的token的信息。
Contextualized RNN
为了解决上述第2个问题:encoder output随着decoder timestep增加而信息衰减。提出以下模型:
decoder在每个timestep的input上都会加上一个context:在decoder的每一步,都把源端的整个句子的信息和target端当前的token一起输入到RNN中,防止源端的context信息随着timestep的增长而衰减。
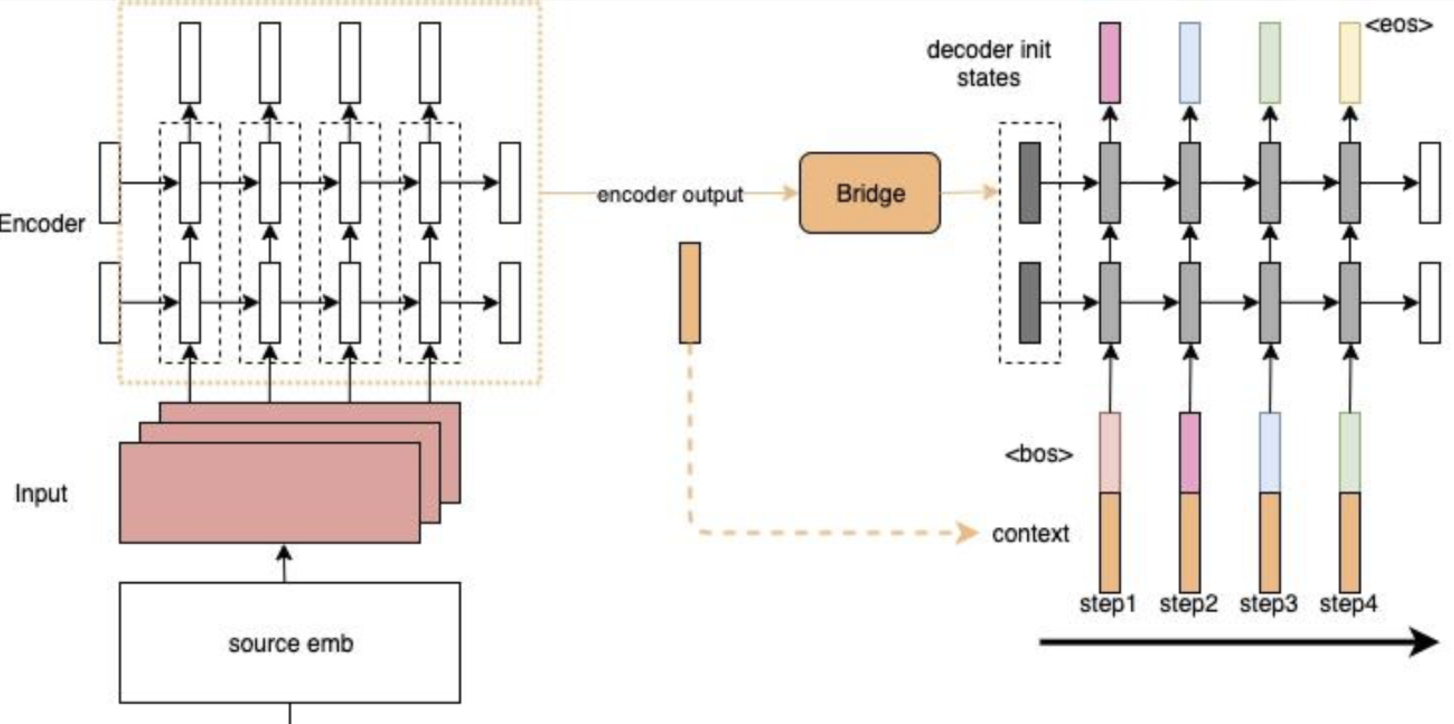
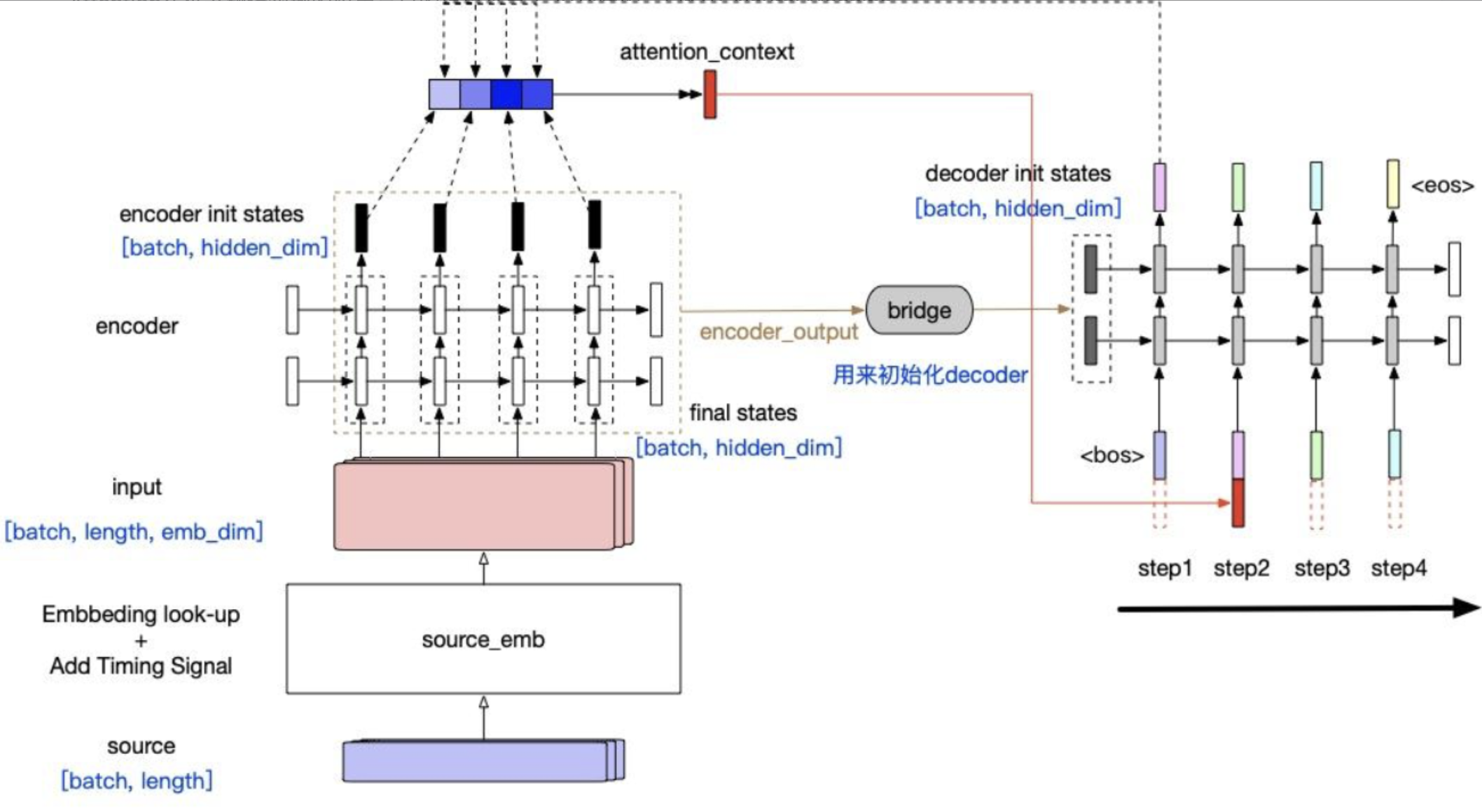
但是还有一个问题:context对于每个timestep都是静态的(encoder端的final hidden states,或者是所有timestep的output的平均值)。但是每个decoder端的token在解码时,用到的context真的应该是一样的吗?
Contextualized RNN with soft align (Attention)
RNN的优缺点
RNN优点如下:
- 权重共享:不同的timestep采用相同的权重,可以减少模型参数量,降低过拟合风险;
- 速度快:Encoder每个时刻的输入仅依赖于上一个隐状态和当前token,Decoder通过给定的隐状态预测下一个token,因此所有token推理消耗基本相同;整体推理速度和context长度线形相关。
RNN缺点如下:
表达能力缺失:
- 有损压缩,隐状态长度固定:隐向量保存context能力有限;
- RNN偏序:整个语序并不完全满足偏序结构,通常有定语后置、补语和各种从句等附加方式,因此RNN处理长距离关联复杂语法结构的能力有限;
- Decoder解码时,每个timestep的隐状态来源于Encoder生成的同一个隐向量:不同位置的单词可能需要不同程度和不同方面的信息;
- 权重共享:对输入中的每个单词赋予同样权重,无法对单词的重要程度进行区分。
信息遗失:
- 序列早期部分的记忆,随着距离的增加产生传播衰减;
- 难以捕捉过长距离依赖关系
难以并行:RNN需要对序列内容进行逐步处理, 每一步的输出取决于先前的隐状态和当前输入。RNN的串行计算阻碍了训练时的并行计算,导致训练效率较低,训练时间过长。
难以训练:RNN 用于信息传输通路只有一条,并且该通路上的计算包含多次非线性激活操作;当 RNN 处理长序列时,因为timestep增加带来的多层激活函数的嵌套,将导致梯度反传时指数级地消失或爆炸。
- 梯度消失:前面的梯度信息无法有效地传递到后面,所以RNN网络难以学习远距离依赖关系;
- 梯度爆炸:网络的权重会变得极大,导致网络不稳定;
当面对长序列时,RNN需要大量内存来维持长序列的隐状态,比如需要完整理解整个句子乃至整篇文章才能做出判断,这些内存负担对训练也造成了很大挑战。
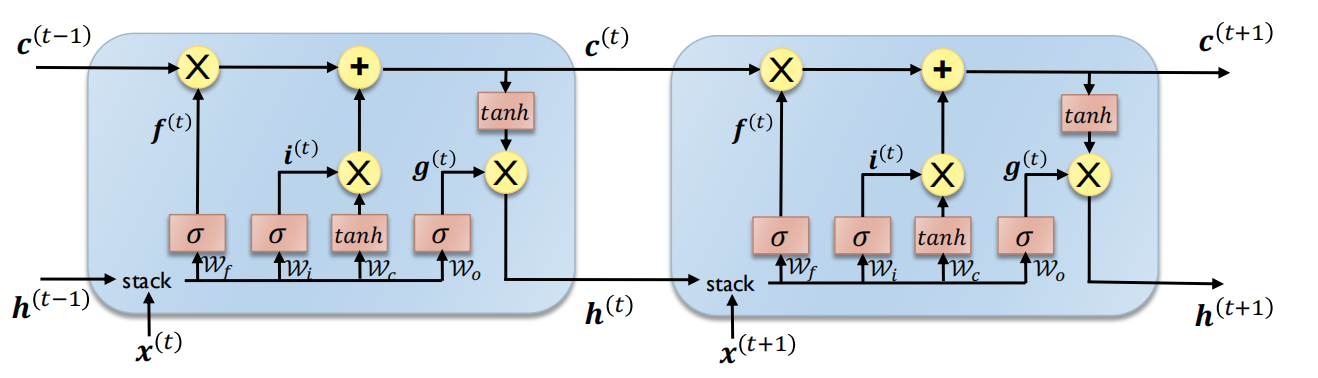
长短期记忆模型(LSTM)
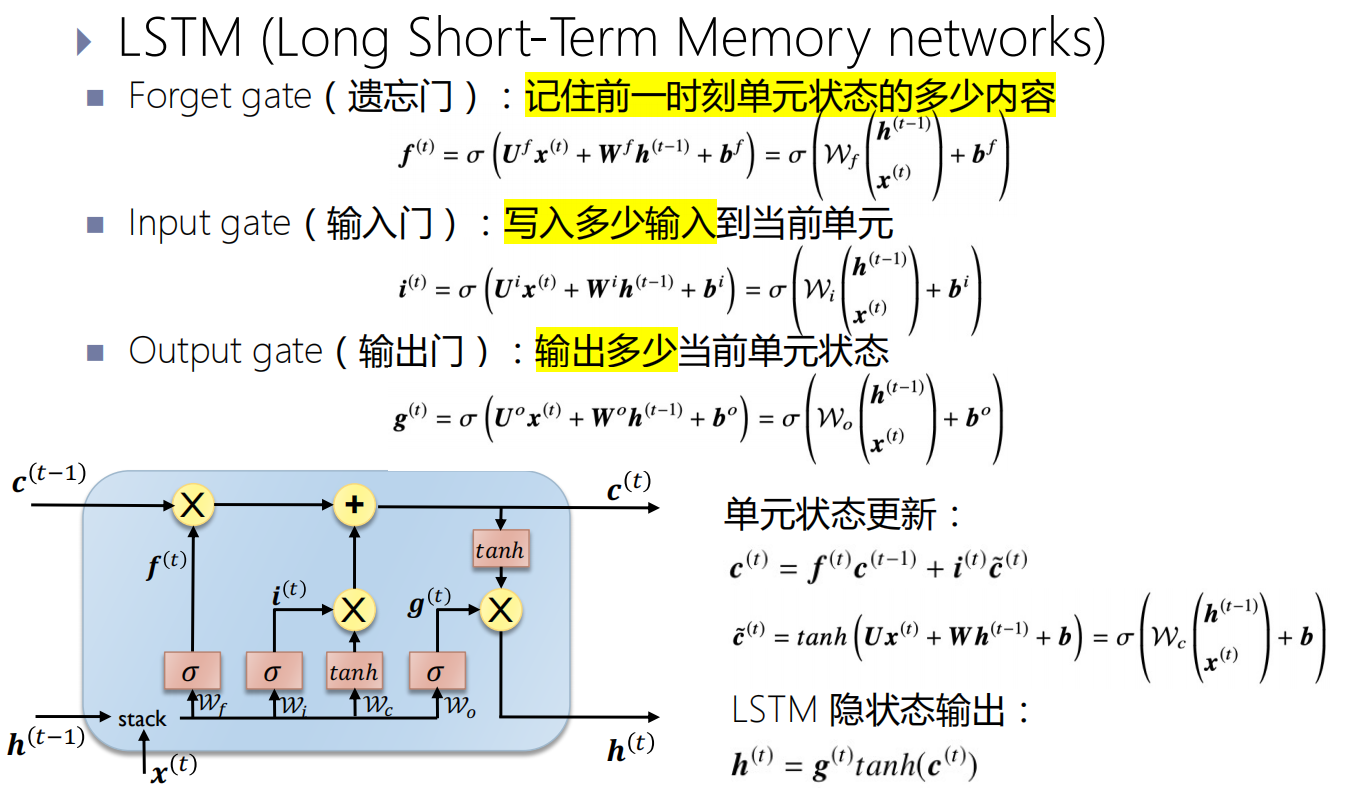
Transformer
通用结构
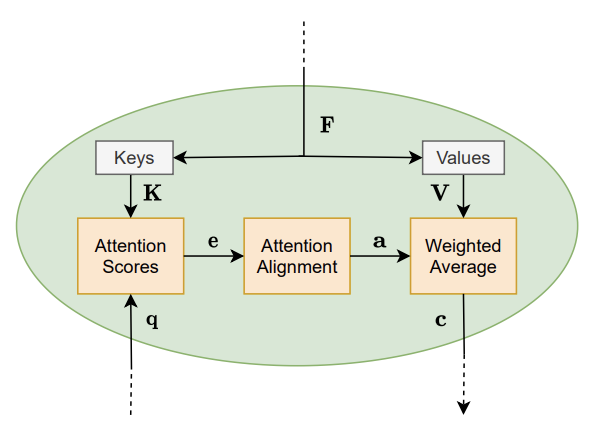
特征模型:假设矩阵X为任务模型的输入,矩阵的列可能是句子之中的单词。任务模型使用特征模型把X转换为特征向量F。特征模型可能是RNN、CNN、嵌入层或者其他模型;
查询模型:q是查询向量,用来确定任务模型需要关注X中的哪些向量、提取哪些信息。或者说,q可以被解释为一个一般问题:哪个特征向量包含对q最重要的信息?
注意力模型:输入为特征向量F和查询向量q,输出是上下文向量c;
输出模型:使用上下文向量c,将各个部分组合成最终的高级特征向量y(例如输出模型可以是softmax层,输出一个预测)
注意力模型
- 从输入生成的特征向量F开始:生成键矩阵K,值矩阵V;
- 使用矩阵K和查询向量q作为输入:计算注意力得分向量e;q表示对信息的请求,\(e_l\)表示矩阵K的第\(l\)列对于q的重要性;
- 通过对齐层(比如softmax函数)进一步处理注意力分数,进而得到注意力权重a;
- 利用注意力权重a和值矩阵V进行计算:得到上下文向量c。
QKV的形象理解:
- Q:目标序列的每个token将自己关注的信息总结到一个向量query之中,向其它token发出询问。目标序列所有token的query构成了查询矩阵Q;
- K:源序列的每个token将自己的特征总结到一个向量key之中,根据该特征回答其他token的询问。目标序列所有token的key构成了键矩阵K;
- V:源序列的每个token的实际值(最终提供的信息)是向量value。源序列所有token的value构成了值矩阵V。
在查找中,目标序列中每个token用自己的query,去和源序列每个token的key计算得到对齐系数,代表token之间的相似度或者相关性:query和key越相似,就代表value对query的影响力越大,query越需要吸收value的信息。随后query会根据两个词之间的亲密关系,来决定从V中提取出多少信息出来融入到自身。
计算流程
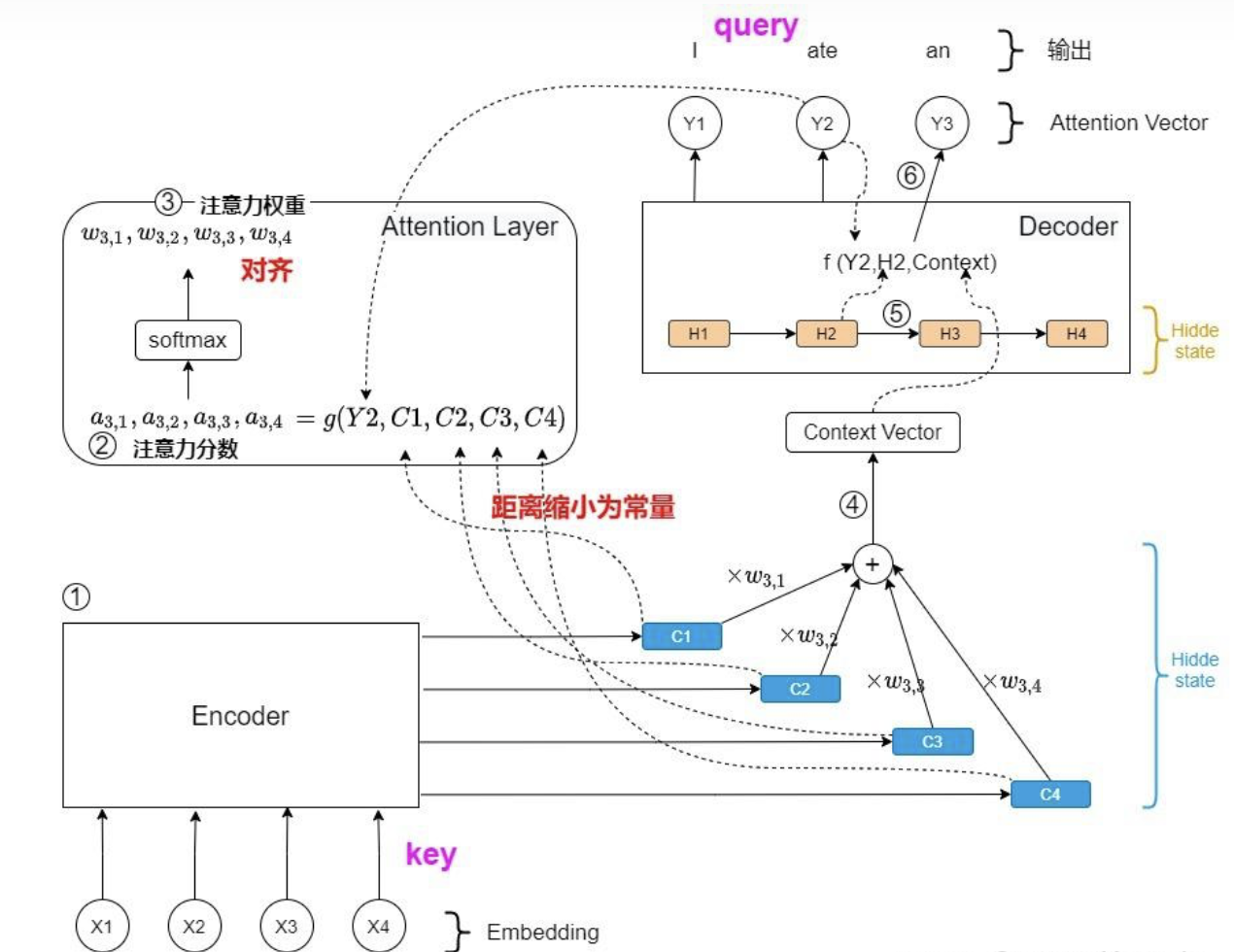
- 生成隐状态向量:源序列依次输入Encoder,对于每个输入token,Encoder输出一个对应的隐状态向量,表示当前token及其context;
- 计算对齐系数a:在Decoder输出每一个预测值\(y\)之前,运用Encoder输出的所有隐状态向量计算注意力分数a;(反映:源序列的所有token,和目标序列当前token的相关性大小)
- 计算概率分布:注意力分数a进行softmax归一化,得到注意力权重w,表示:每个输入token对当前输出token的重要程度(softmax:放大高分隐藏状态,抑制低分隐藏状态)
- 计算当前时刻的context:使用注意力权重w对Encoder所有隐状态向量加权求和,得到Decoder当前时刻的上下文语义向量Context,表示:当前输出token所需的源语言信息;
- 更新Decoder的隐状态;
- Decoder计算输出预测token:输入为Decoder前一次的输出、Decoder当前状态和Decoder当前时刻的Context,输出为一个概率分布,表示:每个可能的token作为当前输出的概率。
思想
增大信息含量:
- RNN:Decoder将所有context压缩到一个固定大小隐向量,不同阶段均使用相同的隐向量。上下文较长时,表达能力有限;
- TTT:context压缩到模型权重中,增强了表达能力;
- self-attention:使用一个列表(KV Cache)存储所有context,无压缩。不像RNN只传递一个Decoder最终的隐状态,而是传入所新token就可以和过去所有context进行交互。
缩短token间距:任意两个token之间建立了distance = 1的平行关系,从而解决RNN的长路径依赖问题(distance = N),平等地看待每一个token,无前后偏好;取消RNN的递归限制,支持并行。
动态生成权重:CNN/全连接层使用静态权重,在训练时候固定,在推理时注意力机制使用动态权重,由输入的query、key通过相似度计算而得,是一种自适应操作。
对齐:注意力机制应用在序列转换的源序列和目标序列之间。
双向context融合:可以同时从左到右和从右到左读取输入序列,并将每个时间步的隐状态拼接起来作为输出;允许Encoder同时考虑输入序列中,每个单词的前后上下文信息。(在此之前只有BiLSTM,但是其本质只是两个单向建模的叠加,而不是Transformer这种彻底的context融合)

不足
- 算力需求大:需要计算序列中每个token对其他每个token的关系,因此计算量随输入序列长度的增加,呈平方级增长。这限制了LLM的最大序列长度N的大小;RNN只要考虑之前的隐状态和当前输入。
- 内存消耗大:KV Cache
参考
Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
A General Survey on Attention Mechanisms in Deep Learning
Learning to (Learn at Test Time): RNNs with Expressive Hidden States
