Transformer 的 KV Cache
Problems
对于LLMs,每次矩阵乘法都由若干个浮点运算组成,因此其性能受限于GPU的FLOPS;随着输入的token长度增加,Transformer的自注意力机制与输入序列长度呈平方关系增长,产生最大的延迟开销。
为了解决推理延迟和吞吐量问题,当前的大模型服务系统通常采用KV Cache:通过缓存已计算的Key和Value矩阵,以避免在解码阶段重复计算键和值的投影(空间换时间)。然而在以下场景中KV Cache占用内存较大,影响推理性能:
- 处理长序列或多轮对话;
- 对于多个客户端请求,每个请求分别保留各自的KV Cache。
KV Cache的核心问题在于:占用大量内存和访存带宽;在生成阶段引入大量重复计算。本篇博客探讨KV Cache压缩技术。
Backgrounds
推理加速的衡量指标如下:
- 吞吐量:每生成一个token,服务商需要支付的算力成本。可以通过tokens per second(tps)衡量,即推理服务器单位时间内能处理针对所有用户和请求生成的输出token数。
- 延迟:包括两个指标:
- TTFT(Time To First Token):在用户输入查询的内容后,模型生成第一个输出token所需的时间。
- TPOT(Time Per Output Token):单个输出token的生成时间,即:总生成时间/总生成token数。
- 额外:TBT(Token之间的时间):两个token生成间的延迟。
prefill阶段:负责处理输入prompt的完整内容,计算量大、并行性高,生成第一个token,因此主要使用TTFT衡量;
decode阶段:通过自回归方式,逐个生成后续的token,尽管单步计算量小,但生成每个新token都需要反复访问之前生成的所有token对应的KV Cache。主要使用TBT/TPOT衡量。
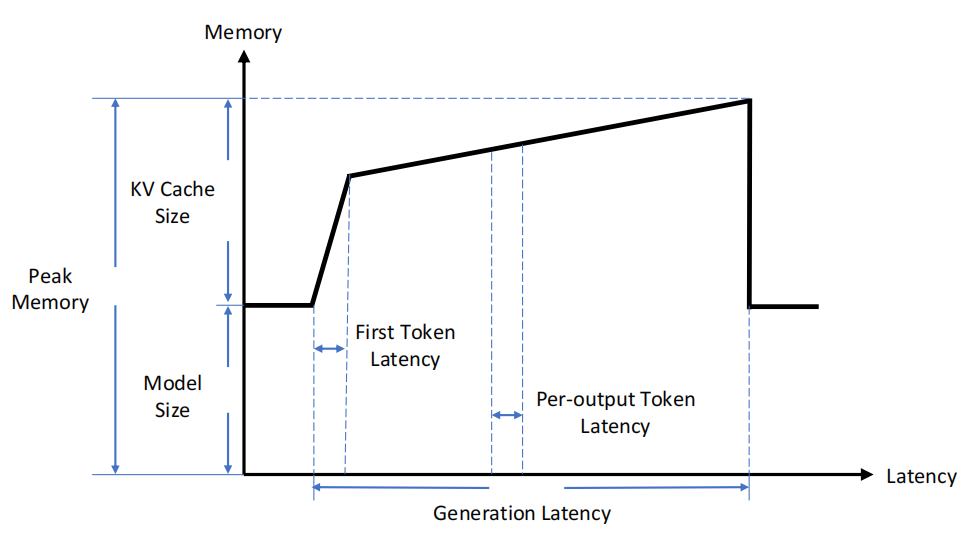
下图展示了推理过程中,KV Cache对显存的占用情况:
Parameter Analysis of Transformer
当前主流的LLMs均基于transformer模型,按模型结构可划分为两大类:encoder-decoder和decoder-only。decoder-only结构又可以分为Causal LM(代表模型是GPT系列)和Prefix LM(代表模型是GLM)。这里分析decoder-only框架transformer模型的模型参数量、计算量、中间激活值、KV cache。
为什么现在的LLMs基本采用Decoder-Only结构呢?
- 相同参数量的训练效率:Decoder-Only > Encoder-Only > Encoder-Decoder
- 现行分布式并行策略下,可扩展的参数量上限和分布式集群规模上限:Decoder-Only, Encoder-Only >> Encoder-Decoder
Pipeline Parallelism是模型参数达到千亿、集群扩展到千卡以上时最重要的特性。为什么呢?
流水并行的核心优势是:用较少的 Pipeline Bubble 代价 (当 gradient accumulation step 很大时可以忽略不计),较少的 Tensor Buffer 显存代价,以及非常低的通信开销,将大模型的不同层拆分到不同节点上。 大幅减少了单张 GPU 上的 weight tensor 大小(数量) 和 Activation tensor 大小(数量)。
- 与TP相比:对于大型模型(如70B+),仅仅模型权重的大小就足以超出单节点上4-8个GPU的限制;然而当尝试将TP扩展到超出单节点内GPU数量(通常为4或8)时,性能会受到一个低带宽网络——“节点间连接”的强烈影响。即极高的通信频率和通信量使得TP只能在机器内 8 张卡用 NVLink 等高速互联来实现,跨机的 TP 会严重拖慢速度。
- 与DP相比:DP 所需的 AllReduce 通信会随着机器数量增多而变慢; 但PP将DP的模型更新限定在一个很小的范围内(比如六台机器), 同时PP 也让 DP 所需同步的模型梯度大小变小了,大大减缓了模型更新对于训练速度的影响。
然而,PP有一个重要约束条件:需要一个 规整对称的、线性顺序的网络结构。
- GPT 就是这样一个典型的网络结构: 完全一样的 Transformer Layer 顺序堆叠,没有分叉和不对称情况,当均匀切分 Layer 时,各个 Stage 的前向/反向计算时间均一致。
- T5 是 Encoder-Decoder 架构:整个网络分为两大块,且 Encoder 和 Decoder 的 Transformer Layer 参数大小、Attention 计算量、Context Length 等均不一致;另外, T5 Encoder 的输出要发给每个 Decoder Layer,导致流水并行中,各个 Stage 之间会产生大量的、非对称的、间隔跨多个 Stage 的数据依赖,更加剧了流水并行的 load balance 问题。
假设:Transformer模型层数为\(l\),隐藏层维度为\(h\),注意力头数为\(a\);词表大小为\(V\),训练数据的批次大小为\(b\),序列长度为\(s\)。
参数量估计
Transformer模型由\(l\)个相同的层组成,每个层分为两个部分:self-attention模块和MLP模块。
- self-attention模块:模型参数包括\(Q, K, V\)的权重矩阵\(W_Q, W_K, W_V\)和偏置,以及输出矩阵\(W_O\)和偏置。其中,4个权重矩阵形状为\([h, h]\),4个偏置形状为\([h]\)。self-attention块的参数量为:\(4h^2+4h\).
- MLP模块:包含2个线性层,第一个先将维度从\(h\)映射到\(4h\),权重矩阵\(W_1\)形状为\([h, 4h]\),偏置形状为\([4h]\);第二个将维度从\(4h\)映射到\(h\),权重矩阵\(W_2\)形状为\([4h, h]\),偏置形状为\([h]\)。MLP块的参数量为:\(8h^2+5h\).
self-attention块和MLP块各有1个Layer Norm,包含2个可训练模型参数:缩放参数\(\gamma\)和平移参数\(\beta\),形状都是\([h]\);参数量共为\(4h\).
因此,每个transformer层的参数量为\(12h^2+13h\).
词向量维度通常等于隐藏层维度\(h\),因此词嵌入矩阵的参数量为\(Vh\).
Training显存占用
显存占用主要包括4个部分:模型参数,前向计算产生的激活值,反向传播计算得到的梯度,优化器状态。训练时常常采用Adam优化器。
传统FP32训练中,每个参数对应1个梯度(4字节)和2个优化器状态(动量和方差,各4字节)。因此共\(4*N+4*N+(4+4)*N=16*N\).
若使用高低混合精度训练,则:使用BF16进行大部分计算(每个参数、梯度分别需要2字节),额外复制一份模型权重和梯度为 FP32;因此每个参数总共需要 12 字节。总参数量为\(2*N+2*N+4*N+4*N+(4+4)*N=20*N\).
Inference显存占用
推理阶段没有梯度和优化器状态,也无需保存中间激活值。因此显存占用主要来源是模型参数。
如果使用BF16推理,显存占用为\(2N\);如果采用KV Cache加速推理,需要额外占用显存,下文详细分析。
计算量FLOPs估计
假设输入数据的形状为\([b, s]\).
- self-attention模块: \[ Q=xW_Q, K=xW_K, V=xW_V \\ x_{out}=softmax(\frac{QK^T}{\sqrt{h}})·V·W_{o}+x \]
- 计算\(Q, K, V\):矩阵乘法为\([b,s,h]\times[h,h]\rightarrow[b,s,h]\),计算量为\(2*2bsh^2=6bsh^2\).
- \(QK^T\):矩阵乘法为\([b,headnum,s,perheadhiddensize]\times[b,headnum,perheadhiddensize,s]\rightarrow[b,headnum,s,s]\),计算量为:\(2bs^2h\).
- 计算在\(V\)上的加权\(score·V\):矩阵乘法为\([b,headnum,s,s]\times[b,headnum,s,perheadhiddensize]\rightarrow[b,headnum,s,perheadhiddensize]\),计算量为:\(2bs^2h\).
- attention后的线形映射:矩阵乘法为\([b,s,h]\times[h,h]\rightarrow[b,s,h]\),计算量为\(2bsh^2\).
- MLP模块: \[ s=f_{gelu}(x_{out}W_1)W_2+x_{out} \]
- 第一个线形层:\([b,s,h]\times[h,4h]\rightarrow[b,s,4h]\),计算量为\(8bsh^2\).
- 第二个线形层:\([b,s,4h]\times[4h,h]\rightarrow[b,s,h]\),计算量为\(8bsh^2\).
将上述计算量累加,得到:**每个transformer层的计算量为\(24bsh^2+4bs^2h\).
logits计算:将隐藏向量映射为词表大小,矩阵乘法为:\([b,s,h]\times[h,V]\rightarrow[b,s,V]\),计算量为\(2bshV\).
综上,对于一个\(l\)层的Transformer模型,若输入形状为\([b,s]\),一次训练迭代的计算量为\(l*(24bsh^2+4bs^2h)+2bshV\).
计算量与参数量的关联
当隐藏层维度\(h\)>>序列长度\(s\)时:计算量近似为\(24bsh^2*l\)(模型参数量为12lh^2\(,输入tokens数为\)b*s$)。可近似认为:在一次前向计算中,对于每个token,每个模型参数需要进行2次浮点数运算(1次加法+1次乘法);
反向传播的计算量是前向传播的2倍,也即:1次训练迭代中,对于每个token,每个模型参数需要\(2*3=6\)次浮点数计算。
如果采用激活值重计算以减小中间激活显存,需要一次额外的前向传递,那么:在一次训练迭代中,对于每个token,每个模型参数需要\(2*4=8\)次浮点数计算。
训练时间估计
给定训练tokens数、模型参数、训练硬件配置的情况下,训练transformer模型的计算时间为: \[ 训练时间=\frac{8\times tokens数\times 模型参数量}{GPU数\times GPU峰值FLOPs\times GPU利用率} \]
中间激活值估计
激活值:前向传播过程中计算,在后向传播中需要使用的全部张量。不包括模型参数和优化器状态,包括dropout所需的mask矩阵。
假设:中间激活值采用F16或BF16格式保存,每个元素占用2个字节。(dropout的mask矩阵例外,每个元素只占用1个字节)
self-attention模块:

- \(Q, K, V\):需要保存共同输入\(x\),\(x\)的形状为\([b,s,h]\),显存占用为\(2bsh\).
- \(QK^T\):需要保存中间激活\(Q,K\),\(Q,K\)的形状均为\([b,s,h]\),显存占用为\(4bsh\).
- \(softmax\)函数:保存输入\(QK^T\),若注意力头数为\(a\),\(QK^T\)形状为\([b,a,s,s]\),显存占用为\(2bs^2a\).
- 计算完\(softmax\)函数后,进行dropout:需要保存一个mask矩阵,形状与\(QK^T\)相同,显存占用为\(bs^2a\).
- 计算在\(V\)上的加权\(score·V\):需要保存\(score\),显存占用为\(2bs^2a\);需要保存\(V\),显存占用为\(2bsh\)。合计显存占用为\(2bs^2a+2bsh\).
- 计算输出映射,进行dropout:保存输入映射\(2bsh\);dropout保存mask矩阵\(bsh\)。合计显存占用为\(3bsh\).
综上,self-attention模块中间激活值显存占用为:\(11bsh+5bs^2a\).
MLP模块:
- 第一个线形层:保存输入,显存占用为\(2bsh\);
- GELU 函数:保存输入,显存占用为\(8bsh\);
- 第二个线形层:保存输入,显存占用为\(8bsh\);
- dropout操作:保存mask矩阵,显存占用为\(bsh\)(记录第二个线性层B的输出结果中,hidden_size 维度上有哪些元素被随机mask掉;0/1矩阵,元素使用1byte即可保存)
综上,MLP模块中间激活值显存占用为:\(19bsh\).
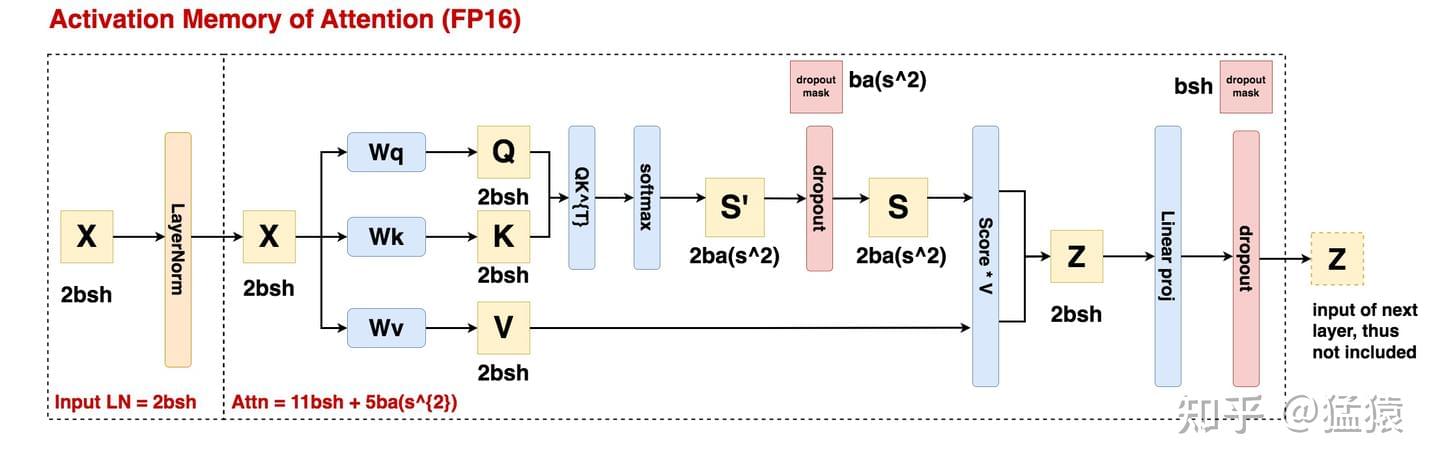
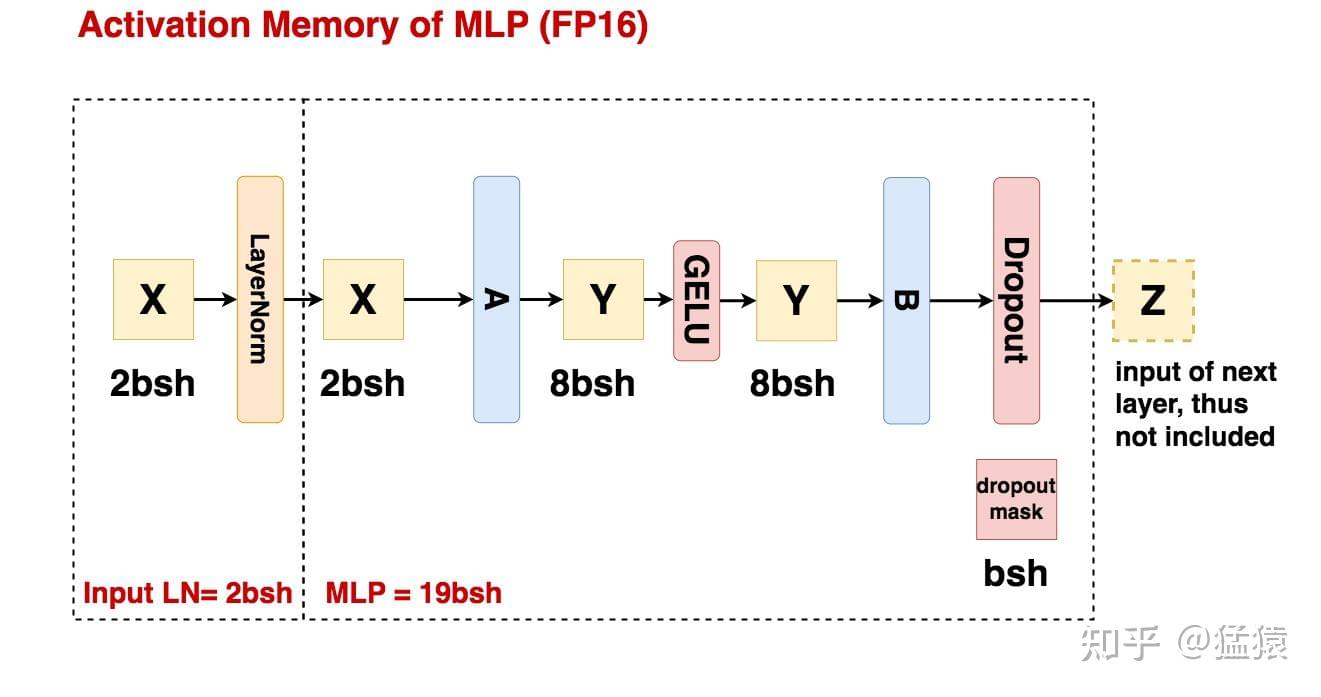
Self-attention和MLP各对应一个Layer Norm,每个均需保存其输入,大小为\(2bsh\),总显存占用为\(4bsh\).
综上,对于\(l\)层的transformer模型,中间激活值显存占用近似为\((34bsh+5bs^2a)l\).
对比:模型参数和中间激活值的显存占用
对于\(l\)层的transformer模型:模型参数量为\((12h^2+13h)*l\);中间激活值为\((34bsh+5bs^2a)*l\).
可以发现:模型参数显存占用量与输入数据大小无关;中间激活值显存占用与输入数据大小(批次大小b和序列长度s)成正相关。
随着批次增大或序列变长,中间激活值成为显存占用的主要来源。若采用激活重计算,理论上可将其显存占用从\(O(n)\)降至\(O(\sqrt{n})\).
KV Cache for Inference
由于每层decoder layer的attention计算独立,因此每一层都需要单独缓存\(K, V\)。代码中体现为:在Attention类中创建\(kv_cache\)张量:
1 | class Attention(nn.Module): |
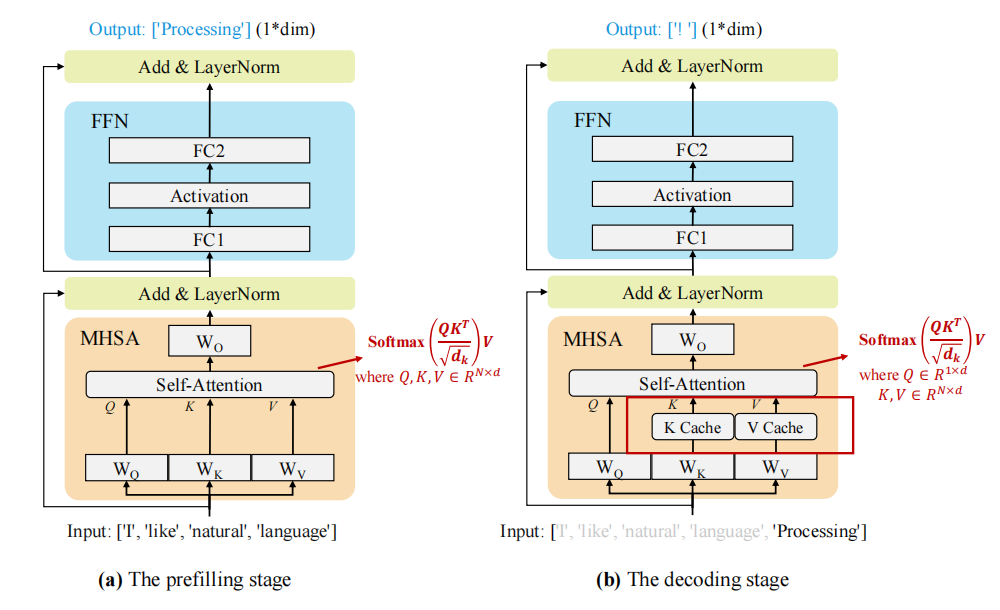
prefill
prefill阶段:输入一个prompt序列,每个transformer层的MHA模块生成KV键值对并存储在KV Cache中,最终生成第一个token,可采用并行计算加速。
用户输入prompt的token均需参与计算,因此\(Q\)的形状为:\([b,s,h]\)。
设输入到 Transformer 层的输入为 \(x_{pre}\in \mathbb{R}^{s\times h}\),其中 \(h\) 是隐藏维度,\(s\) 是提示词 token 序列的长度。MHA 模块的 \(4\) 个线性层权重用 \(W_Q\),\(W_K\),\(W_V\) 和 \(W_o\) 表示。查询、键和值(Q、K、V)的计算过程如下:
\[ Q_{pre}=x_{pre}W_Q, K_{pre}=x_{pre}W_K, V_{pre}=x_{pre}W_V \\ x_{out}=softmax(\frac{Q_{pre}K_{pre}^T}{\sqrt{h}})·V_{pre}·W_{o}+x_{pre} \]
生成的 \(K_{pre}\) 和 \(V_{pre}\) 被存储在 KV Cache中,每个 transformer layer 都独立的存储 KV 键值对。
MHA 的输出 \(x_{out}\in \mathbb{R}^{s\times h}\) 将传递到 MLP。MLP 的输出作为下一个 Transformer layer的输入。
decode
decode阶段:使用并更新 KV cache,逐个生成后续的token(无并行性),当前生成的token依赖于之前已经生成的所有tokens。该阶段的推理计算分两部分:更新 KV cache 和计算 decoder layers 的输出。
只有新生成的 token 作为下一次迭代过程的输入,所以此时 \(Q\) 的维度为 \([b, 1, h]\),即只有新 token 作为 Q。
- MHA加载先前存储的KV Cache,计算新生成token对应的KV键值对,并拼接到原有KV Cache: \[ Q_{dec}=x_{dec}W_{Q} \\ K_{cat}=[K_{cache }, x_{dec}W_{K}] \\ V_{cat}=[V_{cache }, x_{dec}W_{V}] \]
- MHA剩余计算: \[ x_{out}=softmax(\frac{Q_{cat}K_{pre}^T}{\sqrt{h}})·V_{cat}·W_{o}+x_{dec} \]
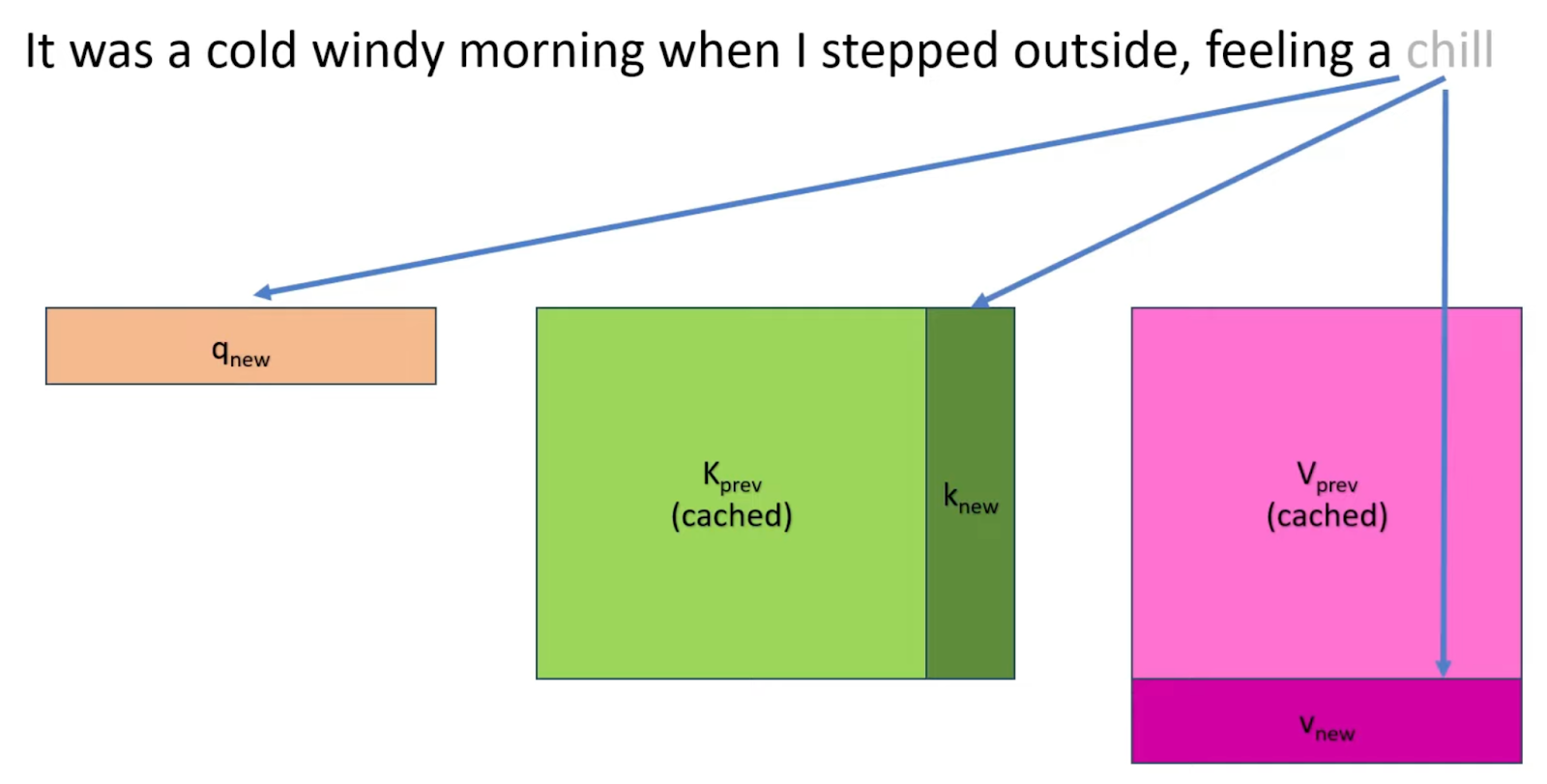
其中MHA的输出\(x_{out}\)被传递到 MLP;最后一个 Transformer 层的输出被发送到最终的预测层,以预测下一个 token。
KV Cache显存占用
单轮对话的KV Cache优化在decode阶段应用,加入KV Cache前后区别如下:
在B方案中,使用输出token替换查询嵌入中的输入token,且KV Cache存储之前生成的 token。因此在计算attention score时,只需要使用一个查询token,再加上KV Cache中的已有 token 就可以了,节省了矩阵乘法的计算量。在处理大规模序列和大批量数据时,显著降低计算开销。
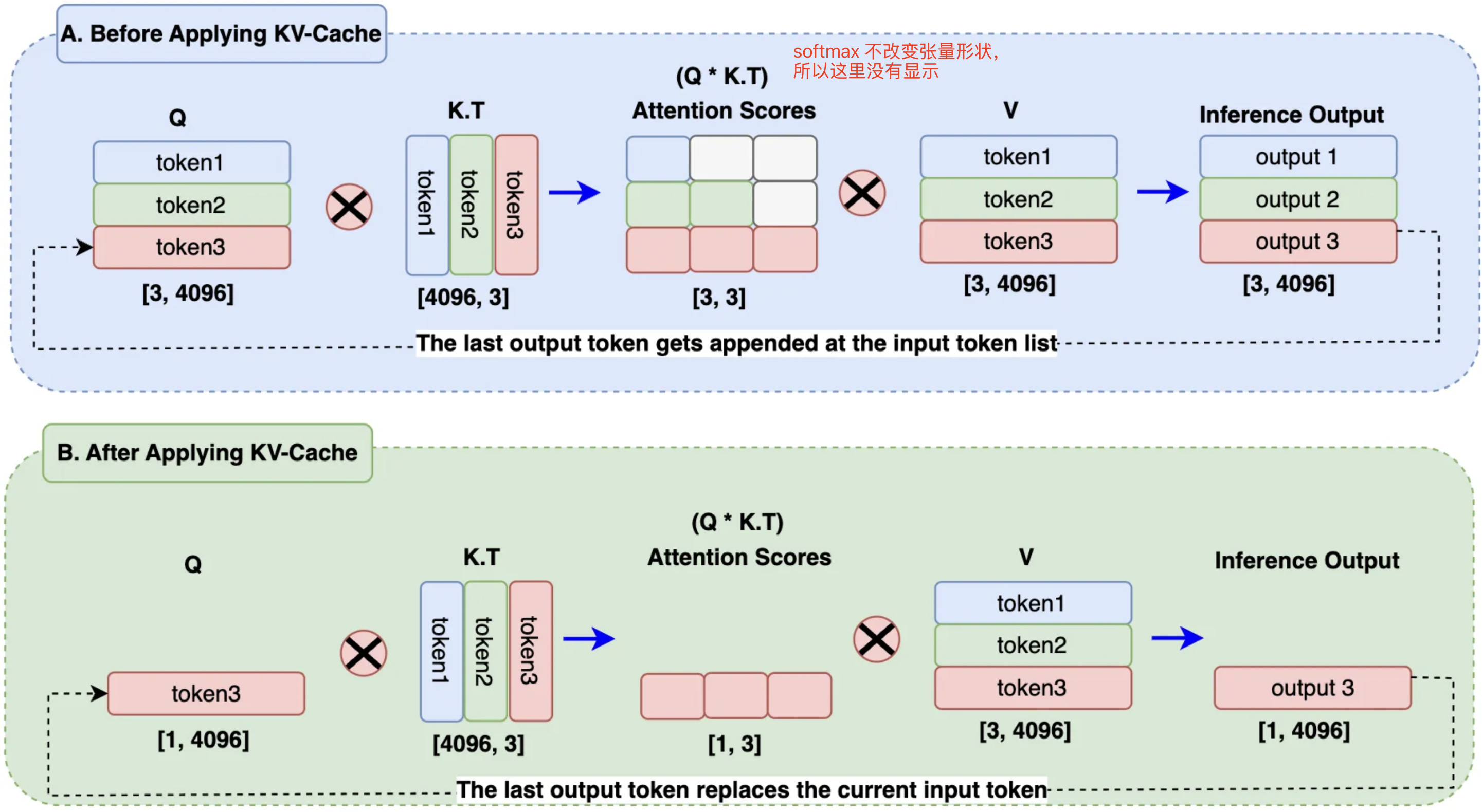
MHA模块中:生成单个token的KV键值对,矩阵计算开销为\(4*l*h^2\).
假设输入序列的长度为\(s\),输出序列的长度为\(o\),decoder layer的层数为\(l\)。若以F16保存KV Cache,那么其峰值显存占用为: \[ 2*2*l*h*b*(s+o)=4lhb(s+o) \] 其中,第一个 2 表示 K/V cache,第二个 2表示 float16 占 2 个 bytes.
References
探秘Transformer系列之(20)--- KV Cache
