Transformer 系列:2. Attention机制,MHA,MQA 和 GQA
Scaled Dot-Product Attention
只使用一个注意力头计算权重。
假设有输入序列\(X=(x_1, x_2,..., x_n)\),对于每个词\(x_i\)(维度为\(d\)),计算其与所有其他词的相关性,并赋予不同的权重,最后对这些信息加权求和,得到新的表示。 输入矩阵:\(X\in\mathbb{R^{n\times d}}\). \[ Attention(Q, K, V)=softmax(\frac{QK^{T}}{\sqrt{d_k}})V \] 这里,\(Q\in\mathbb{R^{n\times d_k}}, K\in\mathbb{R^{m\times d_k}, V\in\mathbb{R^{m\times d_v}}}\)。实质上,一个Attention层是:将\([n, d_k]\)的序列\(Q\)编码成一个新的\(n\times d_v\)序列。
从向量角度看: \[ Attention(q_t, K, V)=\sum_{s=1}^m \frac{1}{Z}\exp(\frac{<q_t, k_s>}{\sqrt{d_k}})v_s \] 其中,\(Z\)是归一化因子。上式意为:通过\(q_t\)这个query,通过与各个\(k_s\)内积再softmax的方式,得到\(q_t\)与各个\(v_s\)的相似度;再加权求和,得到一个\(d_v\)维的向量。
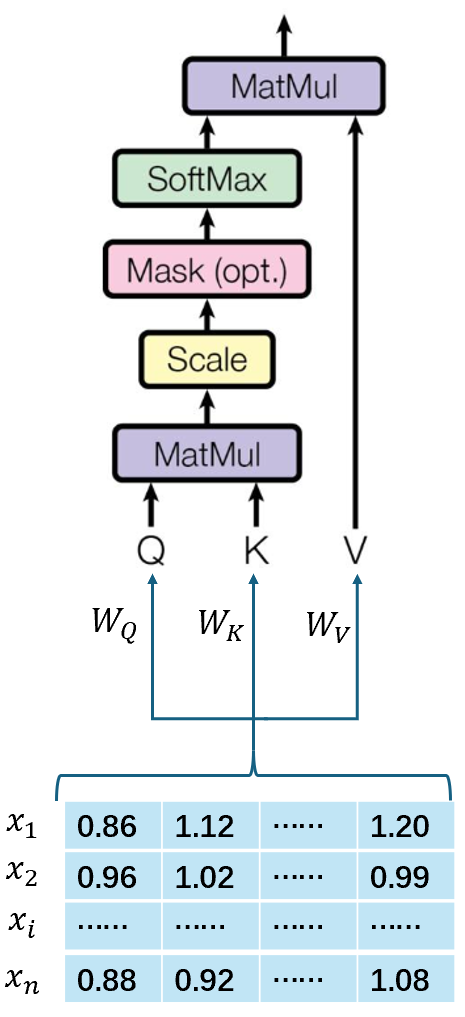
分为以下几个步骤:
计算Query, Key, Value矩阵:每个输入token被映射为三个不同的向量:
- Q:当前需要关注的内容,例如在机器翻译中,查询可能是目标语言句子中的一个token;
- K:与查询进行匹配的内容,例如源语言句子中的token;
- V:最终要提取的信息,通常与键对应。
转换矩阵: \[ Q=XW_Q, K=XW_K, V=XW_V \] 其中,\(W_Q, W_K, W_V\)是可学习的参数矩阵。
输入:维度\(d_k\)的queries和keys;输出:维度为\(d_v\)的values
查询矩阵Q的维度:[\(n, d_k\)],\(n\)为queries的数量;\(d_k\)是每个query的维度
键矩阵K的维度:[\(m, d_k\)],\(n\)为keys的数量;\(d_k\)是每个key的维度
值矩阵V的维度:[\(m, d_v\)],\(m\)为queries的数量;\(d_v\)是每个value的维度
- Q和K的维度必须一致:V和Q/K的维度可以不一致;
- K和V的长度必须一致:K和V本质上对应同一个sequence在不同空间的表达。
Attention得到的output:[\(n, d_v\)]. Attention层的本质:将\([n, d_k]\)的序列\(Q\)编码成一个新的\([n, d_v]\)的序列。
计算点积:得到注意力分数矩阵 \[ scores=QK^{T} \]
缩放:将点积除以\(\sqrt{d_k}\),其中:\(\sqrt{d_k}\)是Key向量的维度,\(\sqrt{d_k}\)是缩放因子,避免数值过大导致梯度消失。
为什么要使用缩放因子\(\sqrt{d_k}\)? 归一化
假设\(Q, K\)里的元素均值为0,方差为1,那么:\(A=QK^{T}\)中元素均值为0,方差为\(d\)。当d变得很大时,\(A\)中的元素方差也变得很大,导致\(softmax(A)\)的分布也趋于陡峭(分布的方差大,分布集中在绝对值大的区域)。
\(A\)中每一个元素乘上\(\frac{1}{\sqrt{d_k}}\)后,方差又回到1,使得:\(softmax(A)\)的分布陡峭程度与\(d\)解耦,从而使得训练过程中,梯度值保持稳定。
softmax归一化:对缩放后的点积结果,应用softmax函数,得到注意力权重矩阵A: \[ A=softmax(\frac{QK^{T}}{\sqrt{d_k}}) \]
加权求和:将注意力权重矩阵\(A\)与值矩阵\(V\)相乘,得到加权求和的结果。
单头注意力机制代码实现:
1 | import torch |
MHA
单头注意力中,模型只能通过一个注意力头来捕捉输入数据中的特征,这限制了模型对复杂关系的建模能力。而多头注意力(Multi-Head Attention)是Transformer架构的核心组件,它的核心思想是:将输入数据分解为多个子空间,每个子空间通过一个独立的注意力“头”(heads)进行处理,最后将所有heads的输出合并,从而能够捕捉到输入数据中不同子空间的特征;同时其复杂度并无增加。
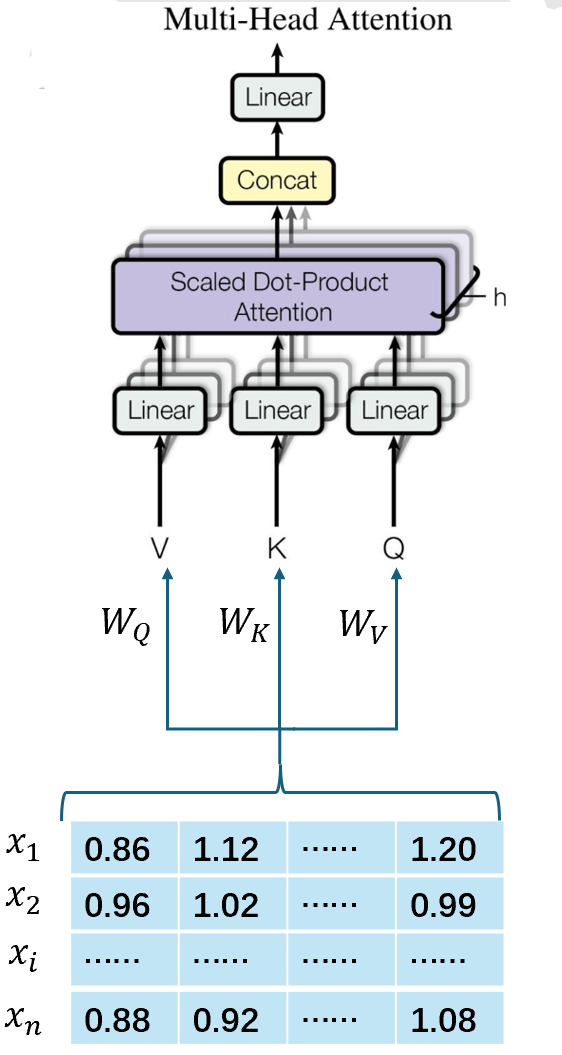
这里对\(W^Q, W^K, W^V\)进行拆分,有: \[ head \]
步骤如下:
计算Query,Key,Value矩阵: \[ Q=XW_Q, K=XW_K, V=XW_V \]
分割多个heads:假设有\(h\)个heads,每个head的维度为\(d_k\),则有: \[ d_k=\frac{d_{dim}}{h} \] 其中,\(d_{dim}\)是模型的嵌入维度。
分割后的Q,K,V如下: \[ Q_i=split(Q, i), \\ K_i=split(K, i), \\ V_i=split(V, i) \] 其中,\(i\)表示第\(i\)个头。
计算每个head的注意力:
计算点积注意力分数: \[ A_i=Q_i\times K_i^{T} \]
缩放: \[ S_i=\frac{A_i}{\sqrt{d_k}} \]
SoftMax: \[ W_i=softmax(S_i) \]
加权求和: \[ O_i=W_i\times V_i \]
合并所有head的输出: \[ O=concat(O_1,O_2,...,O_h)W^{O} \] 其中,\(W_O\)是另一个可学习的权重矩阵,用于将合并后的输出映射回原始维度。
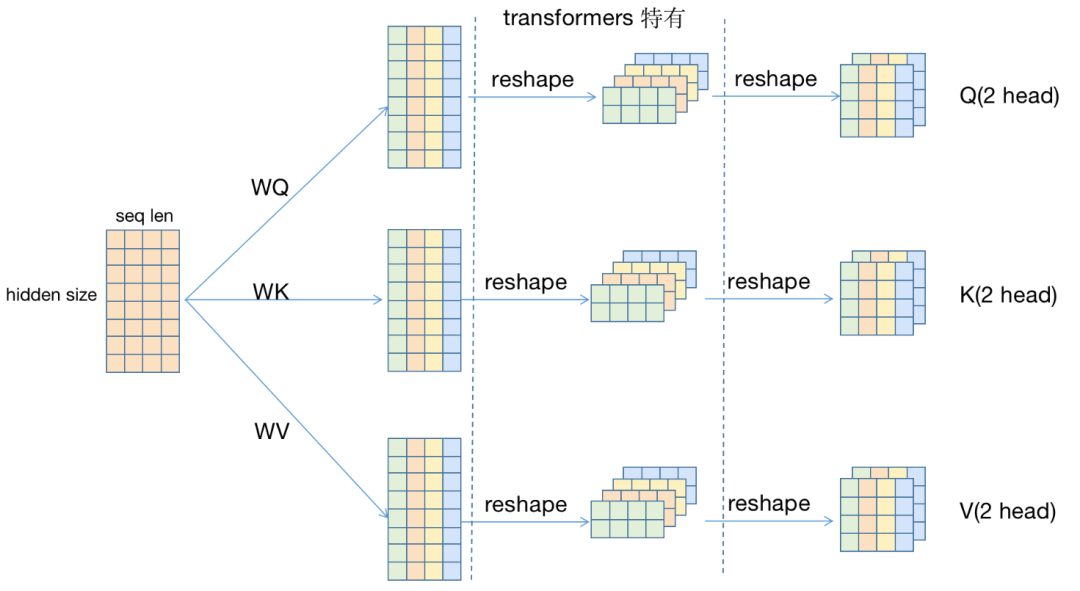
用一些示意图辅助理解:
假设输入序列的seq_len=4,hidden_size=8,使用2头注意力。弱化batch_size(假设为1).
\(Q=XW_Q\):\([s, h]\times [h, h]]\rightarrow [s, h]\)

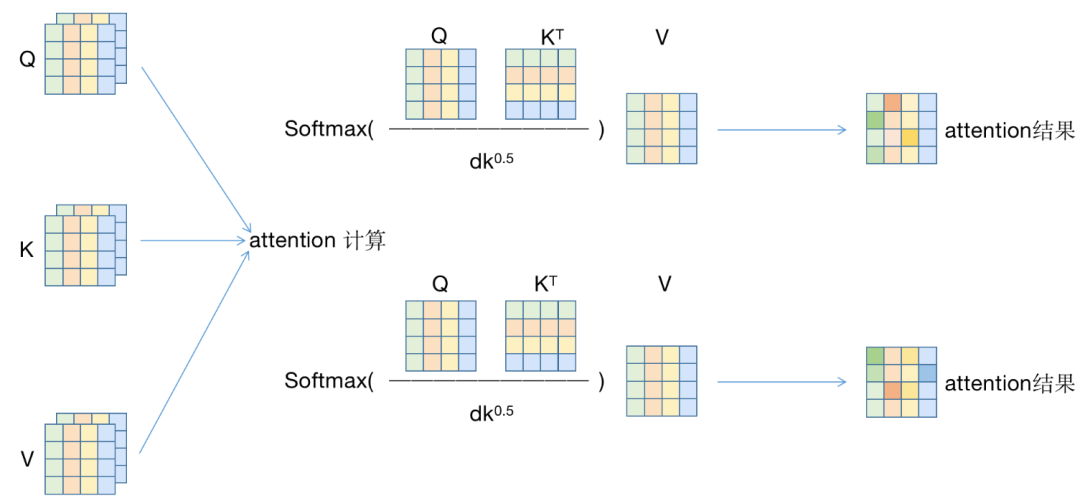
每个head:对于每个\(Q_i, K_i, V_i\),分别计算attention,最后得到一个[2, 4, 4]的矩阵,即\([h, s, d_i]\). (引入head,切分hidden_size,设每个head的hidden_size为\(d_i\))
\(QK^T=[h, s, d_i]\times [h, d_i, s]\rightarrow [h, s, s]\)
重新拼接为[8,4]的矩阵,即\([s, d]\);再经过\(W_O\),得到\(O\)矩阵,即输出。
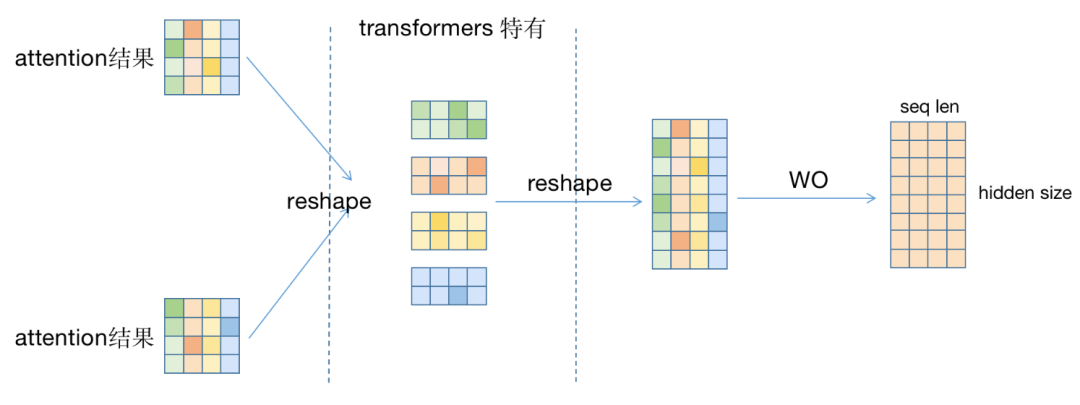
MHA代码实现:
1 | import torch |
KV Cache
大模型在decode阶段采用自回归的方式。即:最新的token输出依赖于先前生成或者预先填入的Token。
假如我们输入“窗前明月光下一句是”:decode过程如下:
1 | step0: 输入=[BOS]窗前明月光下一句是;输出=疑 |
在生成“疑”字时,用的是输入序列中“是”字的最后一层hidden state,再通过最后的分类头预测。可以注意到:下一个step的输入包含了上一个step的内容,而且只在最后面多一个token;因此下一个step的计算也包含了上一个step的计算。
由于decoder是casual的(一个token的attention只依赖于之前的token,得益于mask attention)。因此在自回归生成的过程中,每一步会重复计算之前所有tokens的attention,可简化为:只计算新token的attention。
如下图:空的方块代表可以以前的steps中重用的计算部分:

Key Cache
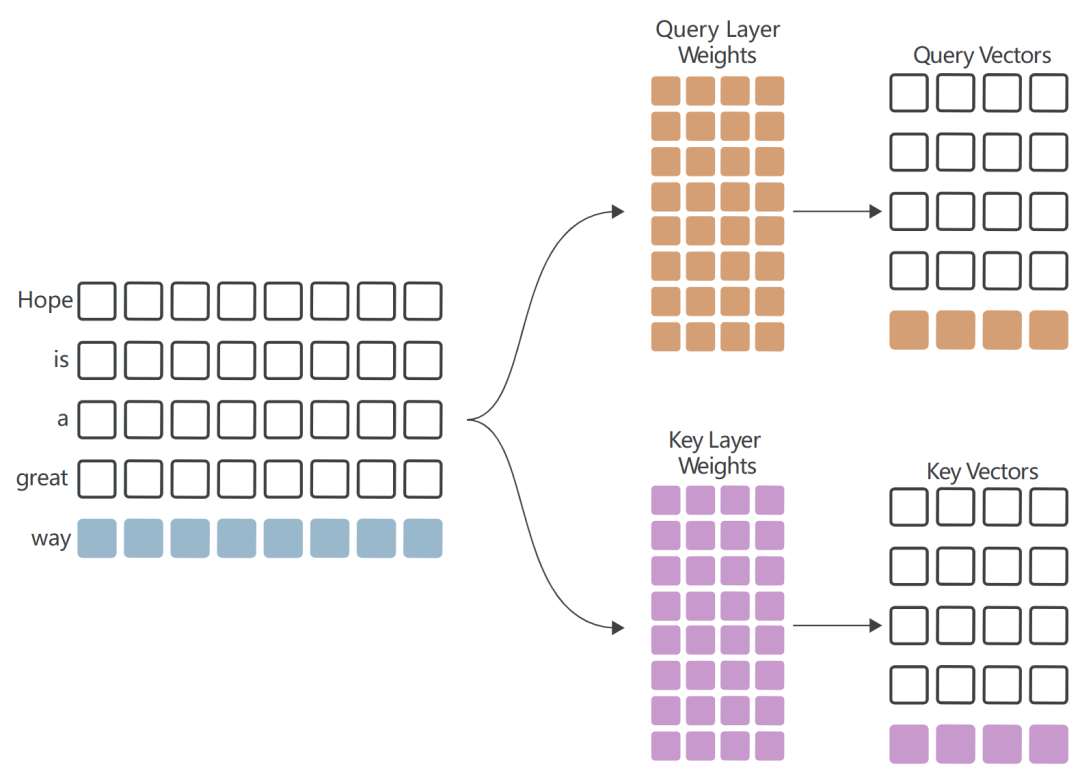
维护一个密钥缓存,存储:在每次迭代中计算的键向量。当前step的流程如下:
只计算一个Query向量和一个Key向量:
从Key Cache中提取先前steps计算的Key Vectors,计算Attention Score的最后一行,即新的Query Vector与所有Key Vectors的点积:
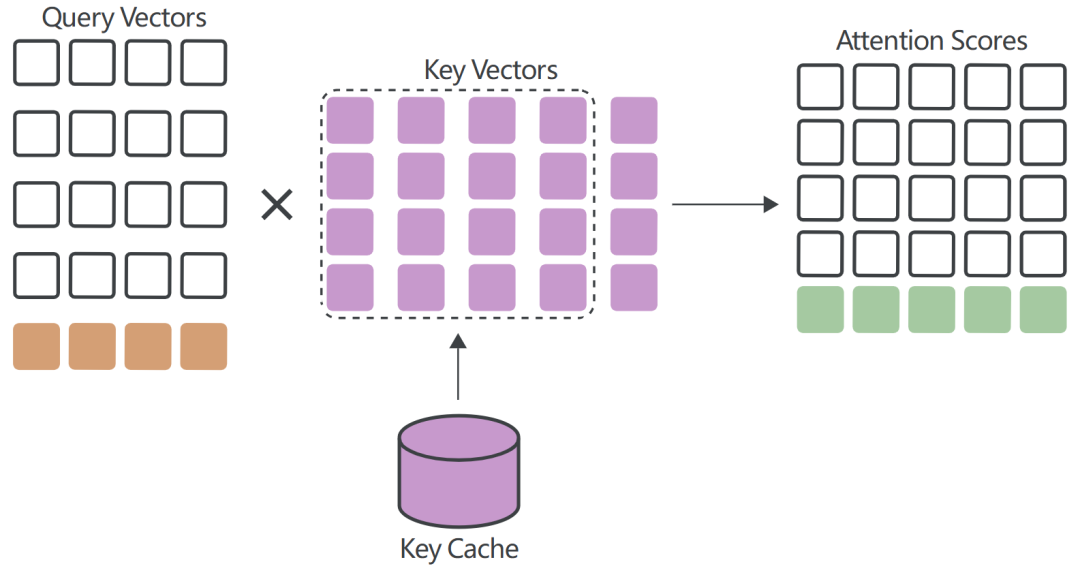
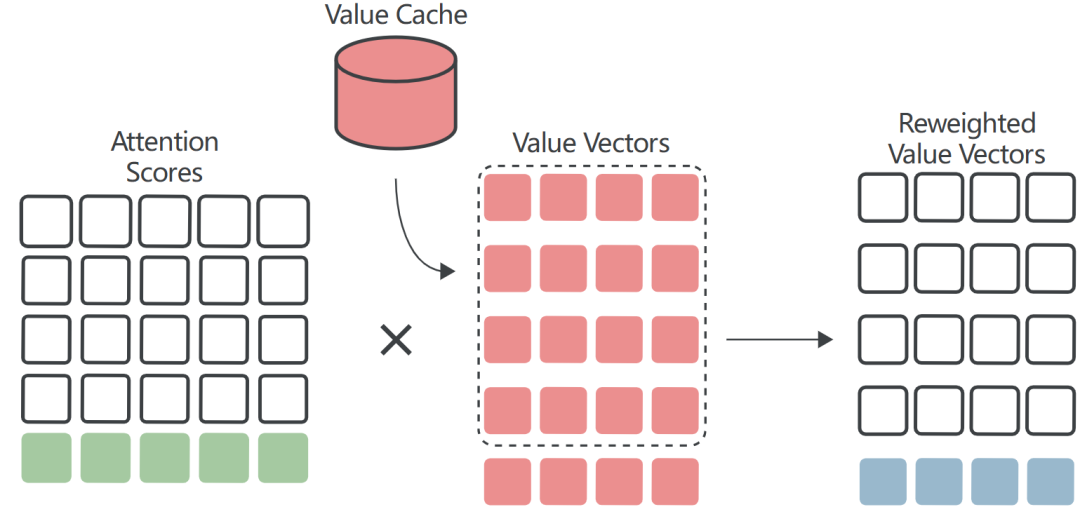
Value Cache
与Key Vector类似,每个step只需要计算最新的Value Vector;其他Value Vectors可以从Value Cache中提取并重复使用:
MQA
KV Cache虽然可以解决kv重复计算的问题,但面对长上下文时,显存占用量巨大。
以llama3-8B模型为例:模型序列长度\(L=8192\)(8K);Transformer层数\(N=32\),注意力头数\(H=32\),每个注意力头的维度\(D=128\),batch按照1算,数据类型为BF16(2个字节),需要的缓存为: \[ token_{kv}=2\times 1\times 32\times 8192\times 128\times 32\times 2=4294967296 \] 即4GB。
MQA的核心思想是:所有注意力头共享一份Key和Value矩阵,仅保留Query的多头性质。即:Key和Value的计算是唯一的,而Query则根据不同的头进行独立转换。
在下图中:
当 batch size=1 时,图中红色、绿色、蓝色虚线圈处的乘法全部为矩阵乘向量,是Memory Bound,算术强度不到 1。
当 batch size>1 时(比如 Continuous Batching):
- 红色和蓝色部分:线性层计算是权重乘以激活,不同请求之间可以共享权重,因此是矩阵乘矩阵,并且 Batch Size 越大,算术强度越大,越趋近于计算密集型(FFN 层也类似);
- 绿色部分:注意力计算是激活乘以激活。因为不同的请求之间没有任何相关性,即使 Batching,此处也是 Batched 矩阵乘向量,并且因为序列长度可能不同,这里不同请求的矩阵乘向量是不规则的。即,这里算术强度始终不到 1,是Memory Bound。
因此绿色部分较难优化,输入序列越长,瓶颈越大。
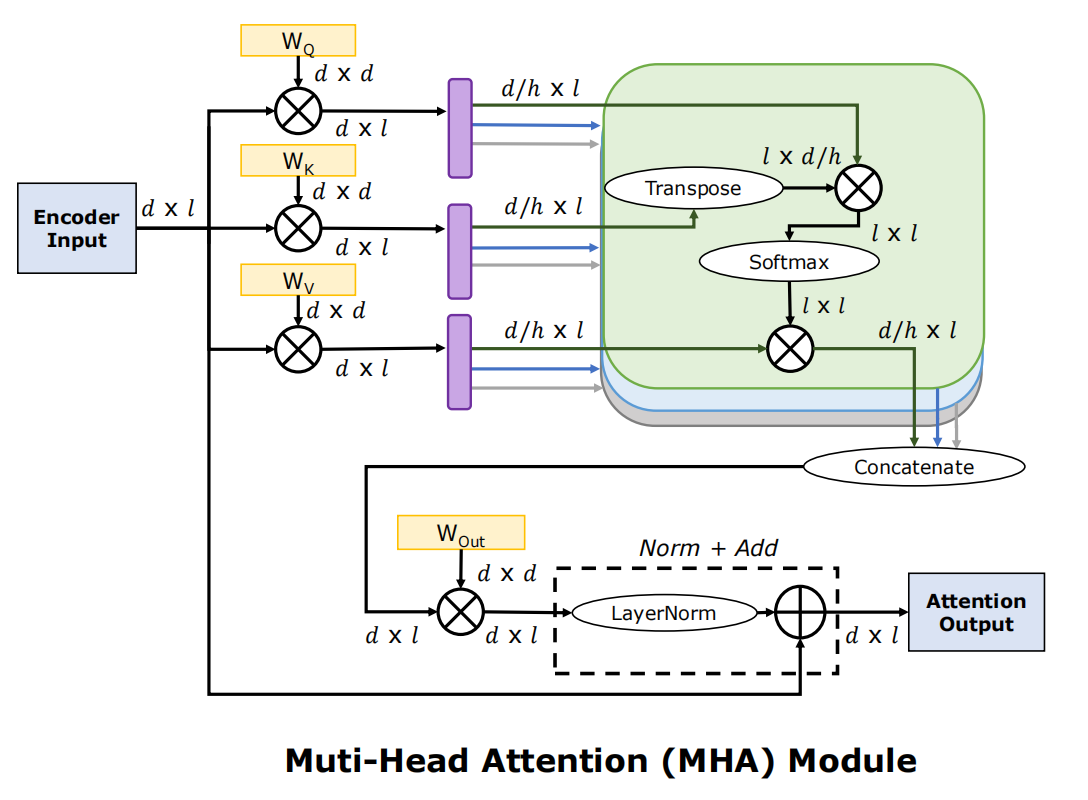
与MHA对比:
MHA:输入分别经过\(W_Q, W_K, W_V\)的变换,切成\(n\)份(n为头数),维度从\(d_{model}\)降到\(d_{head}\),分别进行attention计算再拼接;
MQA:只对\(Q\)切分,而\(K, V\)直接在线形变换时将维度降至\(d_{head}\)(而不是切分变小)
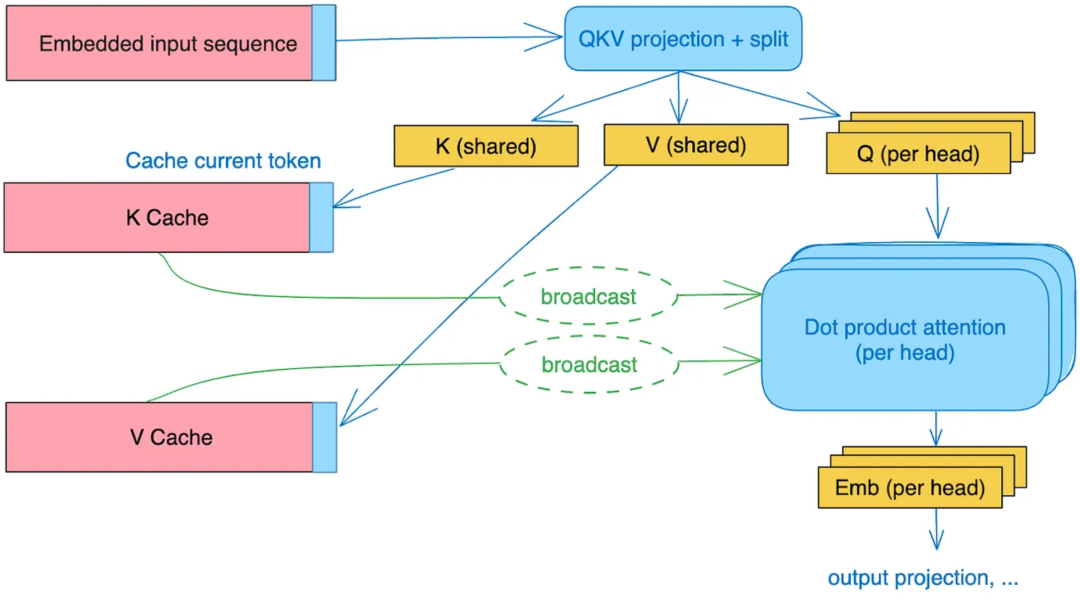
假设输入的维度为:\([b, s, d]\),其中\(b\)为batch size,\(s\)为sequence length,\(d\)为hidden size。
线性变换:得到的\(Q\)为\([b, s, d]\);\(K, V\)为\([b, s, d_head]\).
多头切分:
将\(Q\)按head切分:
1
Q = Q.view(batch_size, -1, self.num_heads, self.head_dim).transpose(1, 2)
拓展\(K, V\)以匹配\(Q\)的维度:
1
2K = K.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
V = V.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
注意力计算:计算\(Q, V\)之间的点积: \[ scores=\frac{Q_{split}K_{split}^T}{\sqrt{d_{head}}} \] 应用softmax获取注意力权重: \[ W=softmax(scores) \] 使用注意力权重,对Value加权求和: \[ context=WV_{split} \]
多头合并:使用矩阵乘法 matmul广播,使得每个头都乘以这同一个张量,以此来实现KV参数共享。
1
2
3output = torch.matmul(attn, V)
# (batch_size, num_heads, seq_len, head_dim)
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model) # (batch_size, seq_len, d_model)
数学公式:
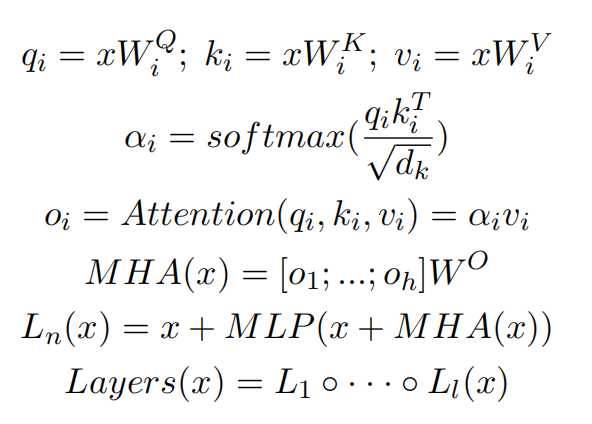
MQA代码实现:
1 | import torch |
内存
MQA所需要缓存的KV值,从所有头减为一个头,KV Cache减少为之前的\(\frac{1}{h}\)。
性能测试如下:
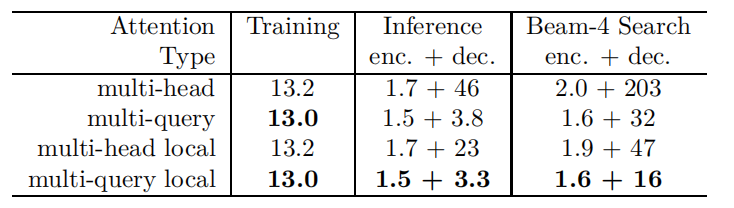
- 训练速度基本不变;
- 推理时间和beam-search时间大幅缩短;
- 推理过程中:Encoder推理速度基本不变;Decoder推理大幅加速。
MQA不改变计算量,但大幅降低了显存使用(降低KV Cache):
- 降低KV Cache的空间占用率;节省的显存空间可用于增加批次大小、提升吞吐量;
- 头数量的减少,导致从显存中读取的数据量减少,减少了计算单元的等待时间,从内存密集型趋近于计算密集型。
表征能力
共享K,V可能导致模型捕捉上下文的能力下降,限制模型的表征能力,导致任务效果相比MHA略有损失。
通信
在多卡并行情况下,MQA减少了访存,但是增加了并行通信开销。由于K和V张量在所有头部之间共享,每个GPU上都需要有自己的备份。与下图(a)中MHA并行策略相比,MQA需要使用all-to-all对进行输入输出激活张量resharding,从而产生额外的通信成本。具体如下图(b)所示。另外,因为每个卡上都有备份,这可能会导致MQA的内存成本节省将会丧失。
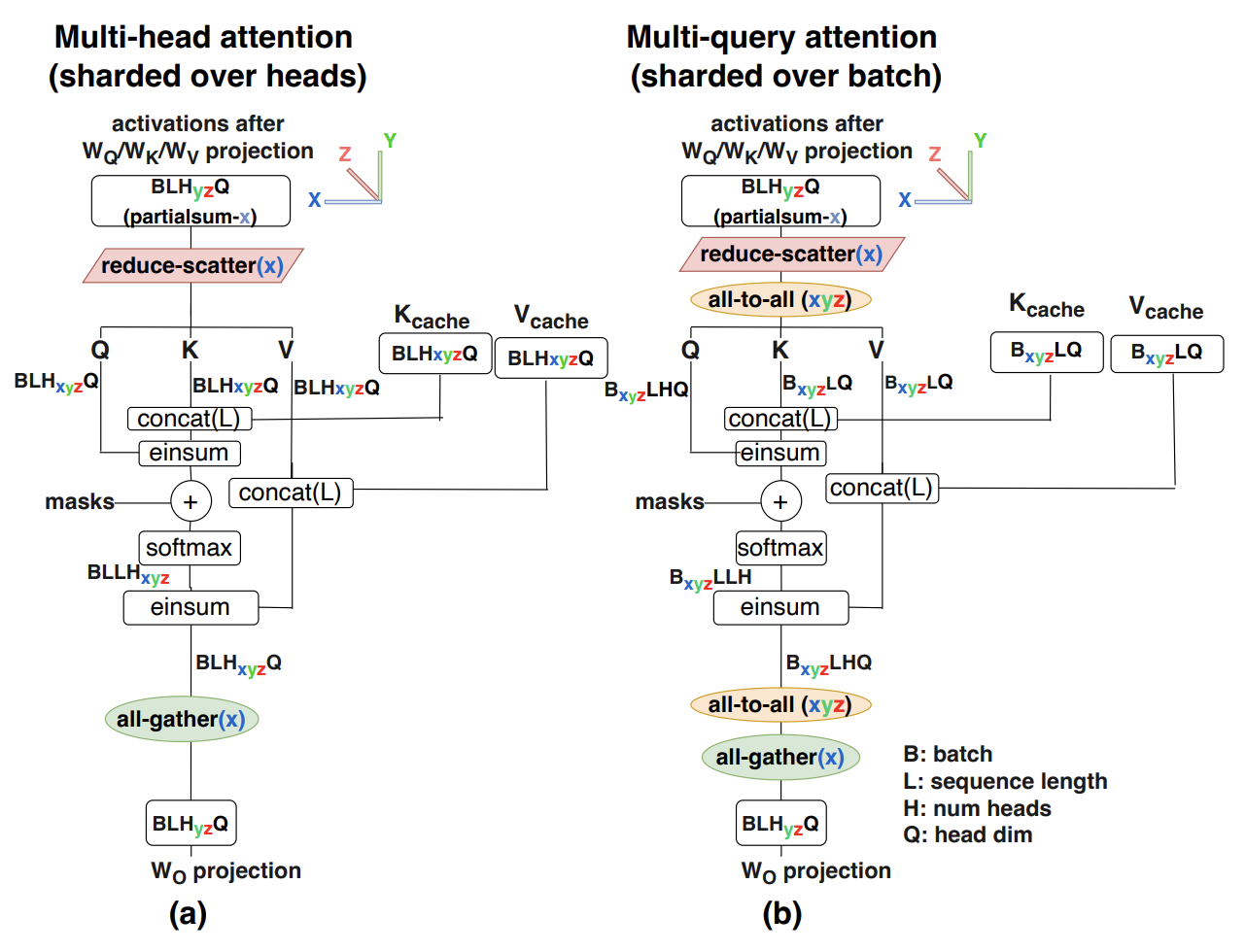
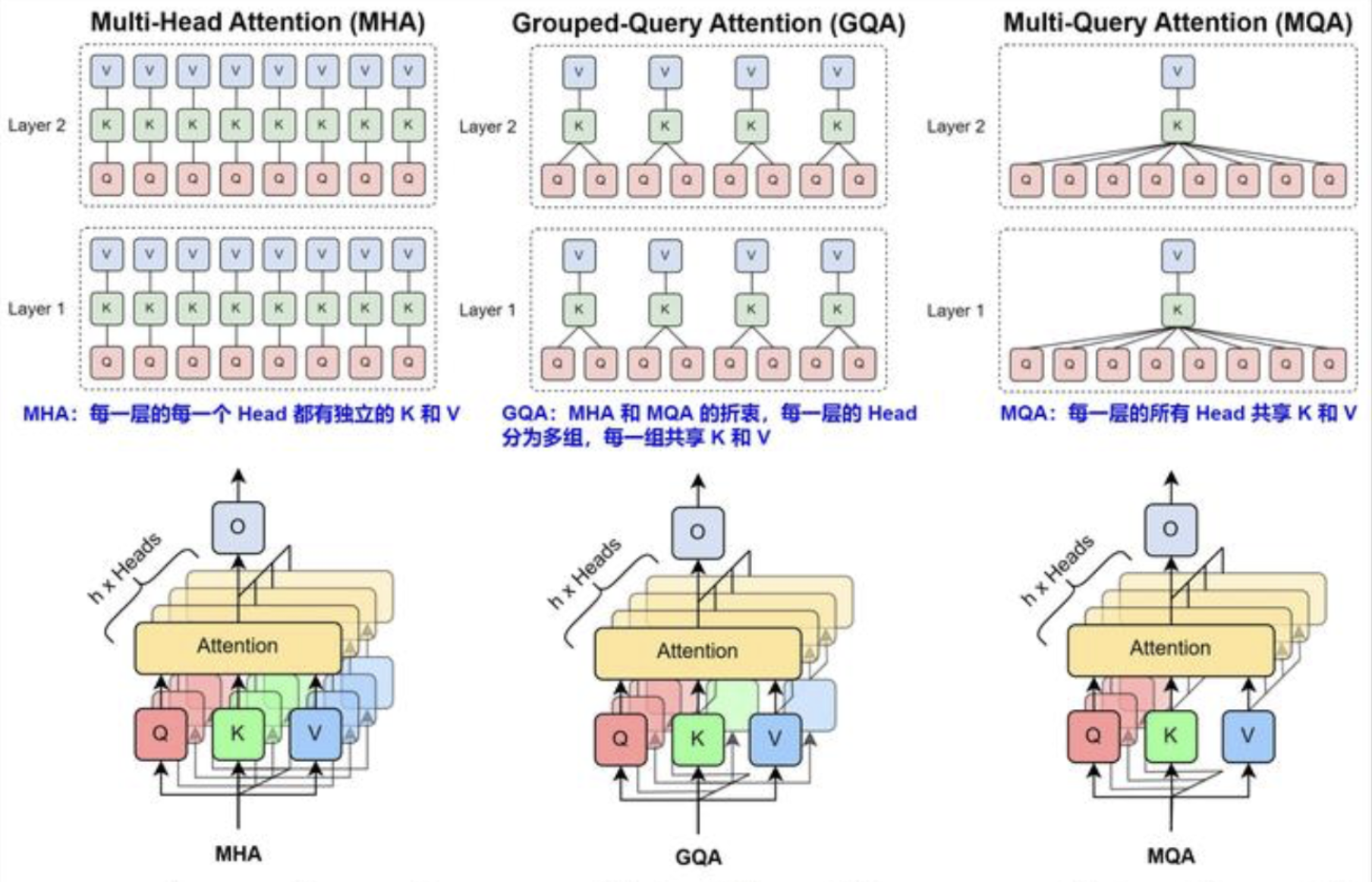
GQA
MHA和MQA的折中方案:采用分组机制,让多个 Query 共享少量的 Key 和 Value,减少自注意力计算的复杂度,同时保持 Transformer 的表达能力。

Query多头计算:Query依然是每个头独立计算。假设有\(h\)个注意力头,计算方式如下: \[ Q_i=XW_Q^i, i=1,2,...,h \] 其中:\(W_Q^i\)是第\(i\)个头的Query投影矩阵;计算出的\(Q_i\)形状为\([b, s, d_{head}]\).(\(d_head=\frac{d}{h}\))
共享分组:Key和Value计算。将Key和Value分成\(g\)组,其中\(g<h\),即: \[ K_j=XW_K^j, V_j=XW_V^j, j=1,2,...,g \] 计算出的\(K_j, V_j\)形状为\([b, s, d_g]\)(\(d_g=\frac{d}{g}\))
计算注意力分数: \[ A_i=softmax(\frac{Q_iK_j^T}{\sqrt{d_g}}) \] 其中:\(Q_i\)来自每个Query头;\(K_j\)来自共享的Key组。计算得到的\(A_i\)形状为\([b, s, s]\).
计算加权Value: \[ Z_i=A_iV_j \]
其中:\(V_j\)是共享的Value组。计算得到的\(Z_i\)形状为\([b, s, d_{head}]\)
- 输出计算:拼接所有注意力头计算的结果\(Z_i\)会被拼接: \[ Z=[Z_1, Z_2, ..., Z_h]W_O \] 其中,\(W_O\)是输出投影矩阵,最终得到形状为\([b, s, d]\)的输出。
GQA代码实现:
1 | import torch |
MHA,MLA,MQA对比:
在MHA下,对于所有输入批次和序列中的每个token,KV Cache的总大小为: \[ 2\times b\times l\times h\times d\times n \] 其中,\(b\)为batch size,\(l\)为总序列长度(输入+输出序列),\(h\)为注意力头数量,\(d\)为每个head的维度,\(n\)为层数。
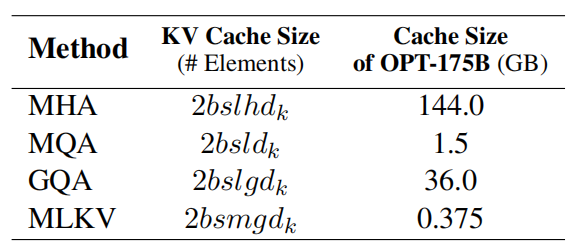
上图中,\(g\)为KV头的组数。当\(g=h\)时是MLA;当\(g=1\)时是MQA;当\(1<g<h\)时,只将KV Cache压缩到\(\frac{g}{h}\)。
GQA和MQA的性能收益主要来源于KV Cache的减少,支持放入更多tokens;但GQA和MQA的性能容易受到并行策略的影响。
GQA和MQA的瓶颈主要在于加载 KV。如果GQA kernel在Q head维度上做并行(一个Q head对应一个block),则会导致共享一个KV head的block被调度在不同的SM上,每个SM 都会对同一份KV head 做重复加载。则内存减少的收益会大大降低。因此需要减少Q head的并行度。
在llama2/3-70B中,GQA中\(g=8\),其他用了GQA的同体量模型基本上也保持了这个设置,这是出于对推理效率的考虑。70B体量的模型,如果不进行极端的量化,不可能部署到单卡(A100/H100 80G)上;一般情况下一台机可以装8张卡,而Attention的每个Head实际上是独立运算然后拼接起来的,因此,正好可以每张卡负责计算一组K、V对应的Attention Head。这样可以在尽可能保证K、V多样性的同时最大程度上减少卡间通信。
参考
MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding
Full Stack Optimization of Transformer Inference: a Survey
Fast Transformer Decoding: One Write-Head is All You Need
Efficiently Scaling Transformer Inference
