CMU15-445 Lecture#05 存储模型和压缩
本篇博客为CMU15-445(2024 Fall)中存储模型与压缩技术部分的理论学习笔记。
数据库工作负载
OLTP(在线事务处理):写操作密集
快速、短时间运行的操作,重复操作和简单查询,每次操作只处理一个实体。OLTP 工作负载通常写操作比读操作多,每次只读/更新少量数据。 * 示例:亚马逊商店。用户可以将物品添加到购物车并进行购买,但这些操作只影响他们自己的账户。
OLAP(在线分析处理):读操作密集
长时间运行的复杂查询(通常涉及计算聚合)和对大量数据的读取。在 OLAP 工作负载中,数据库系统通常会分析和推导来自 OLTP 端的数据。 * 示例: 个性化的亚马逊购物广告。网站分析用户购物车和购买的数据,然后为不同的用户选择不同的广告。
HTAP(混合事务和分析处理)
OLTP 和 OLAP 工作负载在同一数据库实例中共存。 
存储模型
DBMS的存储模型决定:元组在磁盘或内存上等物理介质上的组织形式。
N-元存储模型(NSM):行存储
在 NSM中,DBMS 将单个元组(行)的所有属性连续地存储在一个页面中,因此也称为“行存储”。
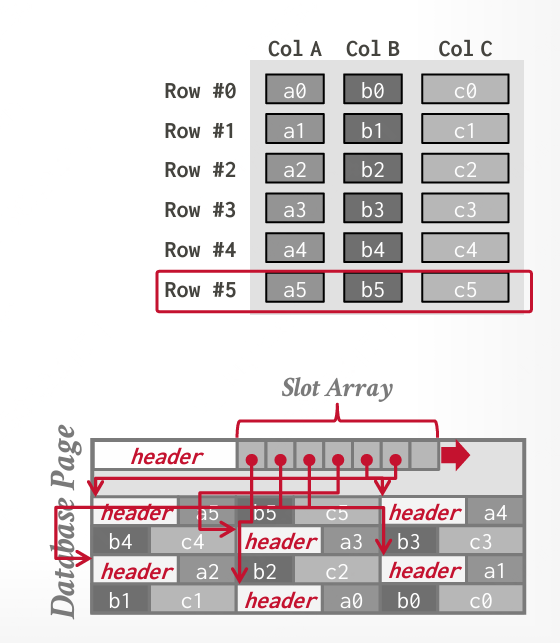
NSM 主要针对 OLTP 场景,要求高性能的随机写入,每次访问大多是单个实体。这种方法的优点是,只需要一次读取就可以获取单个元组的所有属性。NSM 页面通常是 4KB 硬件页面的常数倍。 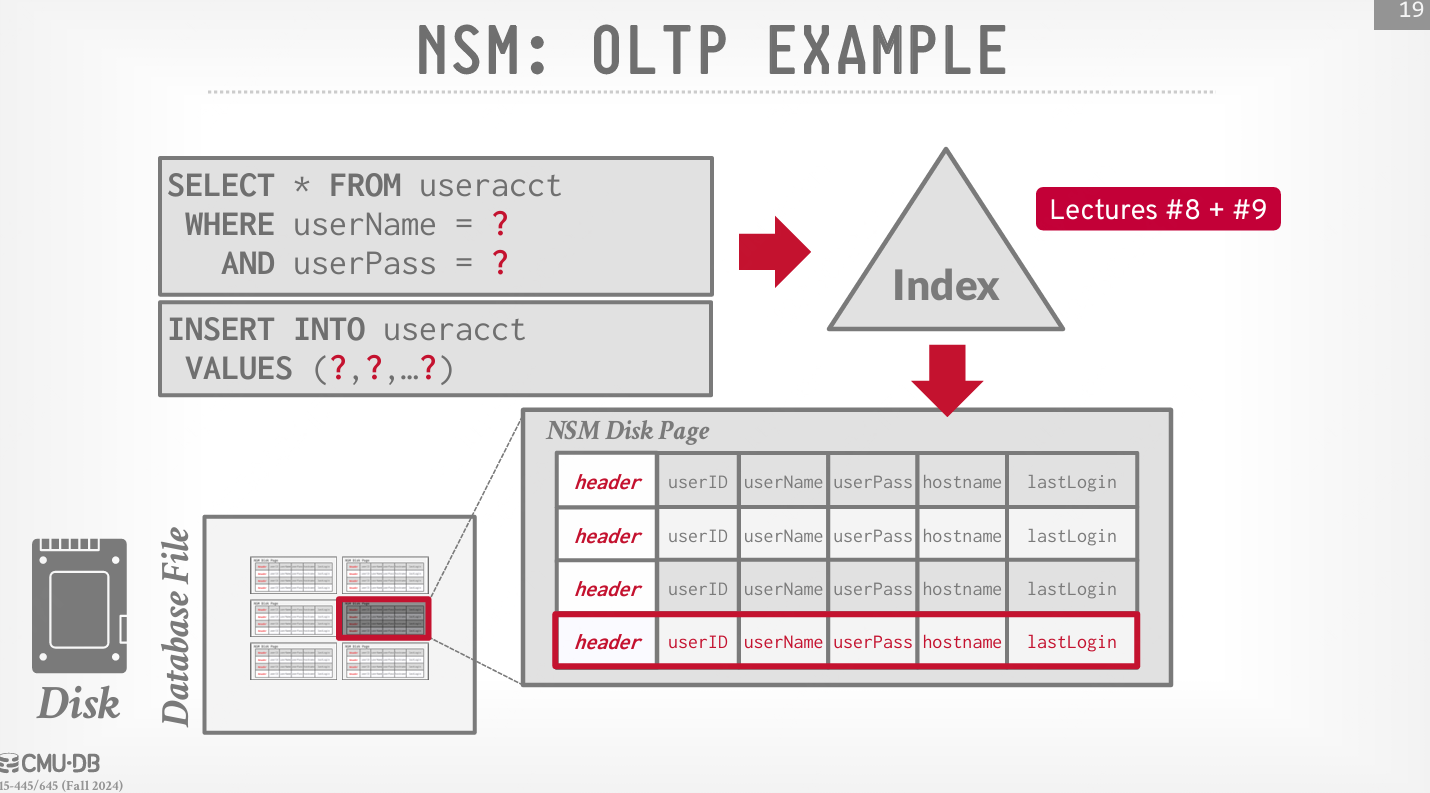
- 优点:快速的插入、更新和删除;适用于需要整个元组的查询(OLTP)。可以使用面向索引的物理存储进行聚集。
- 缺点:扫描大量表数据和/或部分属性效率低;访问模式的内存局部性差;因为一个页面包含多个值域,所以很难应用压缩。
分解存储模型(DSM):列存储
在DSM中,DBMS 将所有元组的单个属性(列)存储在数据块中,因此也称为“列存储”。 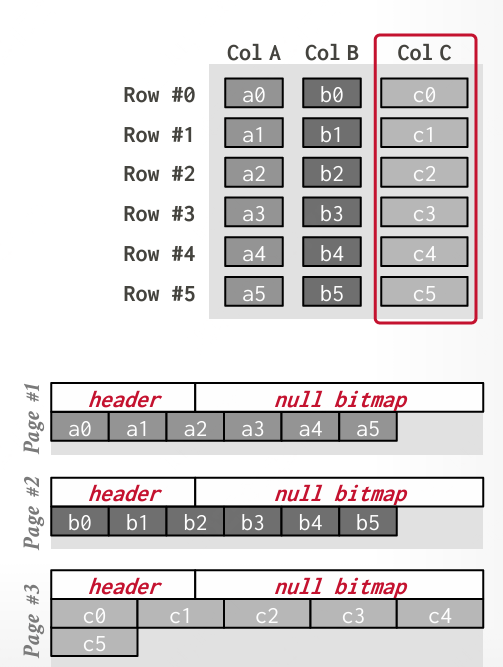
DSM适合 OLAP 工作负载,其中有许多只读查询,需要对表的子集进行大规模扫描。 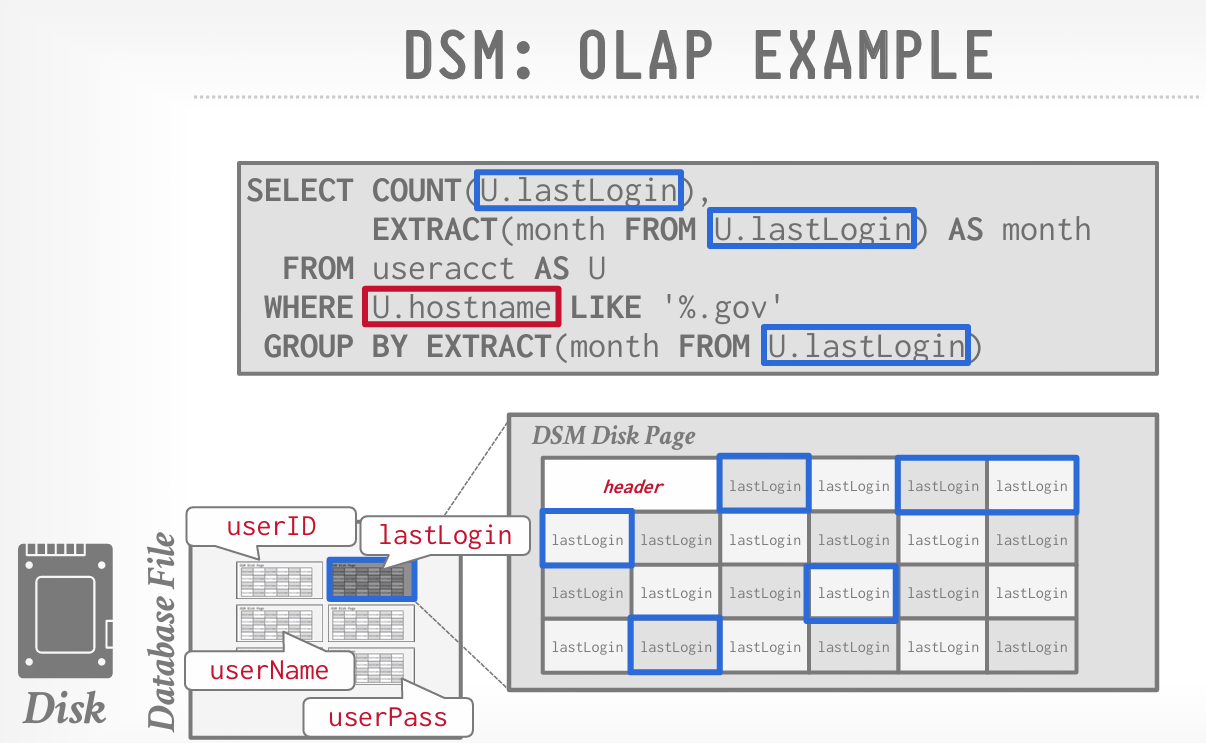
优点:减少每次查询时浪费的 I/O,因为 DBMS 只读取该查询所需的数据;更快的查询处理,数据的局部性和缓存重用率提高;更利于数据压缩。
缺点:对于点查询、插入、更新和删除来说较慢,因为需要拆分和重新组合元组。
重新组合元组的方法
固定长度偏移量
每个列中的数据元素(值)都会使用 固定长度 来表示。这意味着每个属性在列中存储的每个值都占据相同的内存空间,不管这个属性的实际大小。
由于每个列中的值长度相同,DBMS 可以使用 偏移量(offset) 来确定每个属性值在行中的位置。当 DBMS 需要重建一个元组时,它可以利用每个属性的固定长度来准确计算该元组中每个属性值的位置。 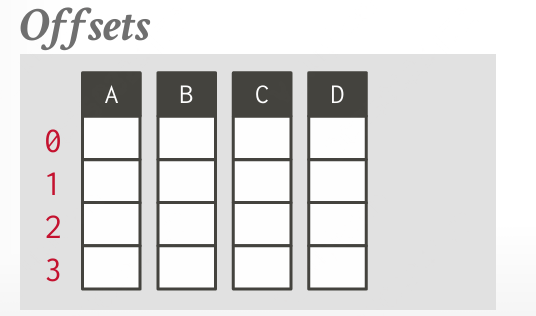
- 优点:简单高效,因为每个值的大小已知且固定;DBMS 可以快速确定每个值在列中的位置。
- 缺点:内存浪费;不适用于变化较大的数据类型(如字符串长度差异大的情况下)。
嵌入元组 ID
每个列中的每个值都会 附带一个元组ID,该元组ID(通常是主键或唯一标识符)指示该属性值属于哪个元组。
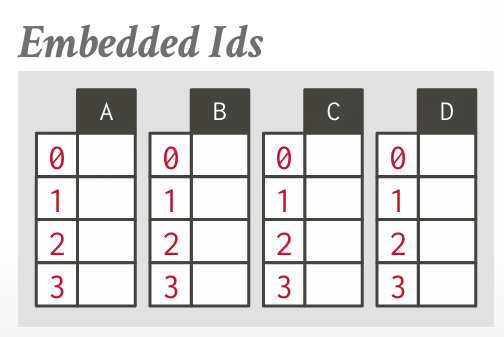
- 优点:适用于具有变动数据类型或长度的列
- 缺点:存储开销较大,每个属性值都要附带一个元组ID;需要额外的索引或映射来解析这些元组ID。
属性跨页分区(PAX)
行按组水平分区;在每个行组内,属性按列垂直分区。
PAX 文件包含一个全局头,其中包含指向文件的行组的偏移量的目录;每个行组维护自己的头,包含有关其内容的元数据。
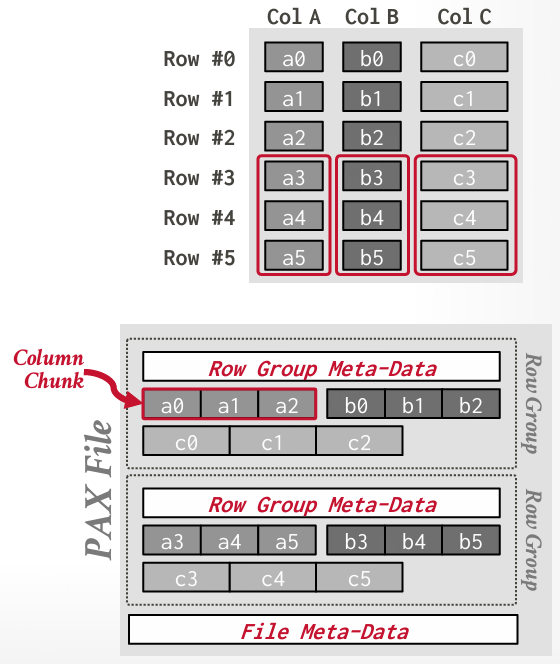
- 优点:获得列存储的处理速度优势,同时保持行存储的空间局部性优势。
数据库压缩
压缩在基于磁盘的数据库管理系统(DBMS)中被广泛使用,因为磁盘 I/O 几乎总是性能瓶颈。它在只读分析型工作负载的系统中尤为常见。DBMS 可以预先压缩数据,这样在查询时可以更有效地获取有用的元组,尽管这会增加压缩和解压缩的计算开销。
内存数据库(In-memory DBMS)更为复杂,因为它们不需要从磁盘加载数据进行查询。内存比磁盘要快得多,但压缩数据库可以减少内存(DRAM)需求并降低处理成本。它们需要在速度和压缩比之间找到平衡。压缩数据库减少了 DRAM 的需求,可能还会在查询执行过程中减少 CPU 成本。
考虑到这些,我们希望数据库压缩方案具备以下属性:
- 必须产生固定长度的值(唯一的例外是存储在单独池中的可变长度数据);
- 允许 DBMS 在查询执行过程中,尽可能延迟解压缩(延迟物化);
- 无损(任何损失性压缩都必须在应用程序级别进行)。
如果数据集完全是随机的比特,则无法执行压缩。然而,现实世界数据集具有一些可压缩的关键特性:
- 属性值的高度偏斜分布(例如,布朗语料库中的 Zipf 分布);
- 同一元组中属性之间的高度相关性(例如,邮政编码与城市、订单日期与发货日期之间的相关性)。
压缩粒度
- 块级别:对同一表的元组块进行压缩;
- 元组级别:对整个元组的内容进行压缩(仅限于 NSM);
- 属性级别:对单个元组中的单个属性值进行压缩(可以针对同一元组的多个属性);
- 列级别:对多个元组中存储的一个或多个属性值进行压缩(仅限于 DSM)。允许使用更复杂的压缩方案。
原始压缩
DBMS 使用通用压缩算法(如 gzip、LZO、LZ4、Snappy、Brotli、Oracle OZIP、Zstd)对数据进行压缩。工程师通常选择压缩比低但压缩和解压缩速度快的算法。
一个使用原始压缩的例子是: MySQL 的 InnoDB。DBMS 会压缩磁盘页面,将它们填充为 2KB 的倍数,并将它们存储到缓冲池中。然而,每次 DBMS 尝试读取或更新数据时,缓冲池中的压缩数据必须首先解压缩;对于盲写操作,不需要解压缩。
问题:
每次访问都需要解压缩数据(如果目标是整个表,每次访问压缩/解压缩不实际),客观上限制了压缩范围(MySQL 将表拆分为较小的块再压缩);
原始压缩方案并未考虑数据的高层次意义或语义。因此,无法利用延迟物化,因为 DBMS 无法知道何时可以延迟解压缩数据。
列式压缩
运行长度编码 (Run-Length Encoding, RLE)
RLE 压缩将单列中相同值的连续实例压缩为三元组:(属性值,列段中的起始位置(偏移量),运行的元素数量(长度)) 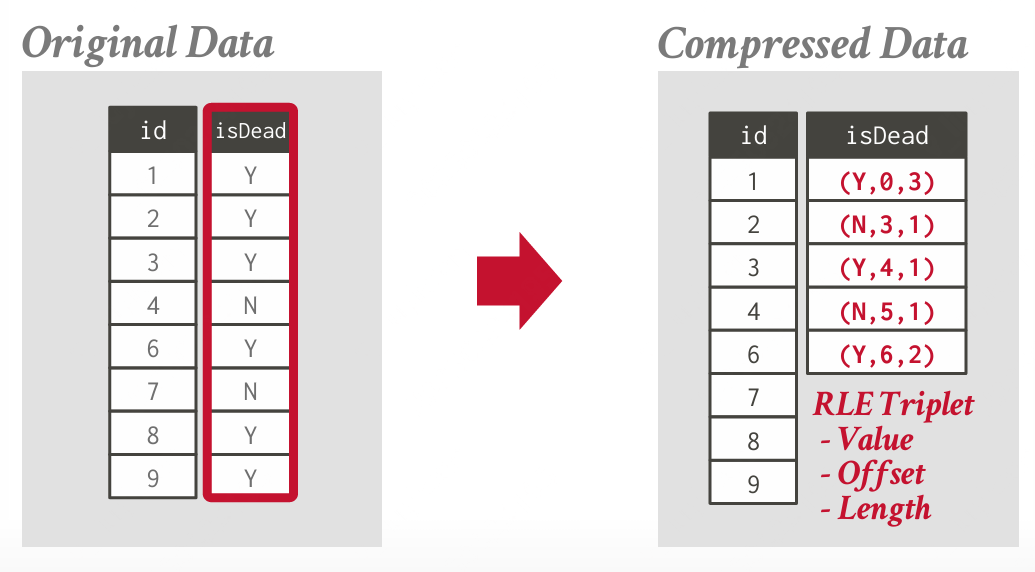
位打包编码 (Bit-Packing Encoding)、
当较高位数的编码用不上时,用更少的位数表示。 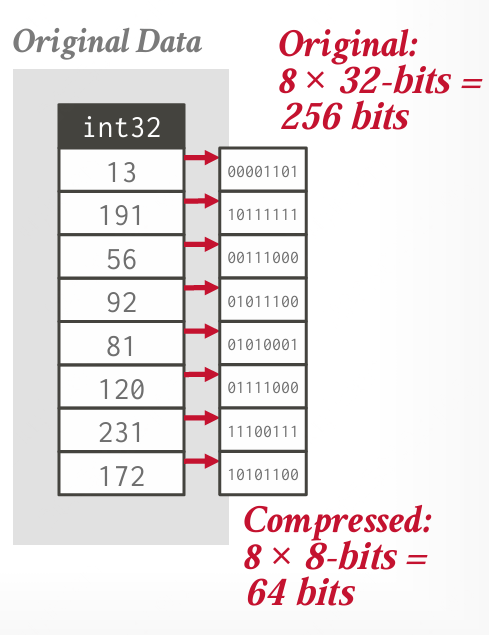
大多数编码 (Mostly Encoding)
位打包的变体:当仅有少数值超过位数表示范围时,使用特殊标记来指示,并维护一个查找表来存储它们。 
位图编码 (Bitmap Encoding)
DBMS 为每个属性的每个唯一值存储一个单独的位图:其中向量中的偏移量对应于元组。位图中的第 i 位表示该元组在该属性中是否存在对应的值。位图通常被分割成多个块,以避免分配大块的连续内存。
因为位图的大小与属性值的基数成线性比例,这种方法只在值的基数较低时才实际可行。
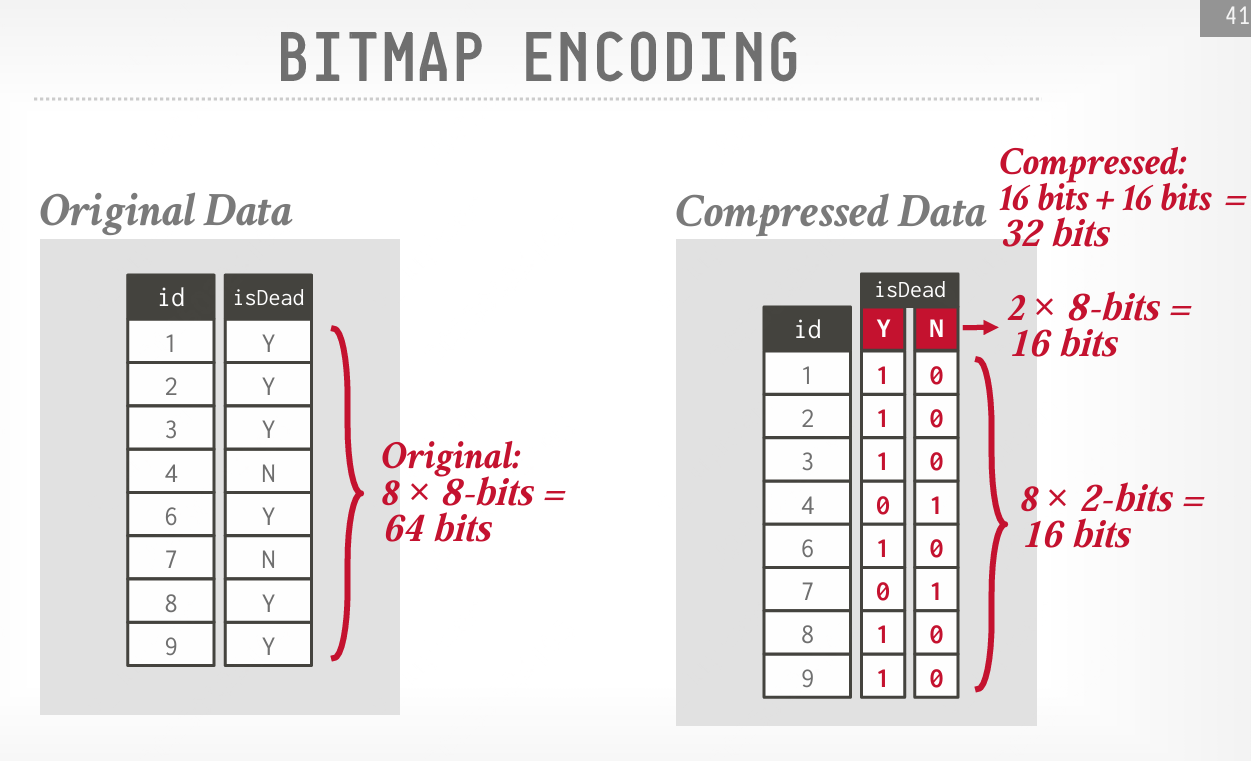
假设有1000,0000个元组,43,000个邮编:
10000000 × 32-bits = 40 MB
10000000 × 43000 = 53.75 GB
每当插入一个新元组时,DBMS必须扩展43,000 个位图单位空间,不划算!
增量编码 (Delta Encoding)
增量编码不存储精确值,而是记录同一列中相邻值之间的差异。基准值可以内联存储,也可以存储在单独的查找表中。我们还可以对存储的增量使用 RLE 进一步提高压缩比。 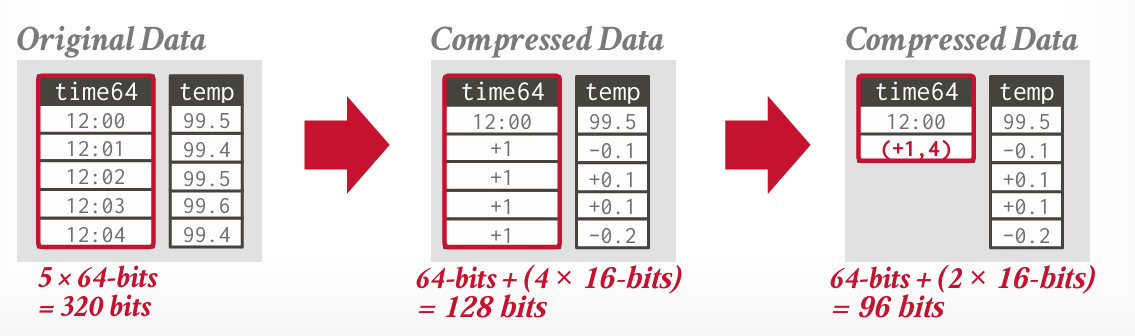
字典压缩
最常见的数据库压缩方案是字典编码。DBMS 用较小的编码替换频繁出现的模式值;字典将编码映射回原始值。字典压缩方案需要支持快速的编码/解码,并且要支持范围查询。
保持顺序的编码:编码后的值,需要支持按照与原始值相同的顺序进行排序,以确保在压缩数据上与原始数据上执行的查询结果一致。 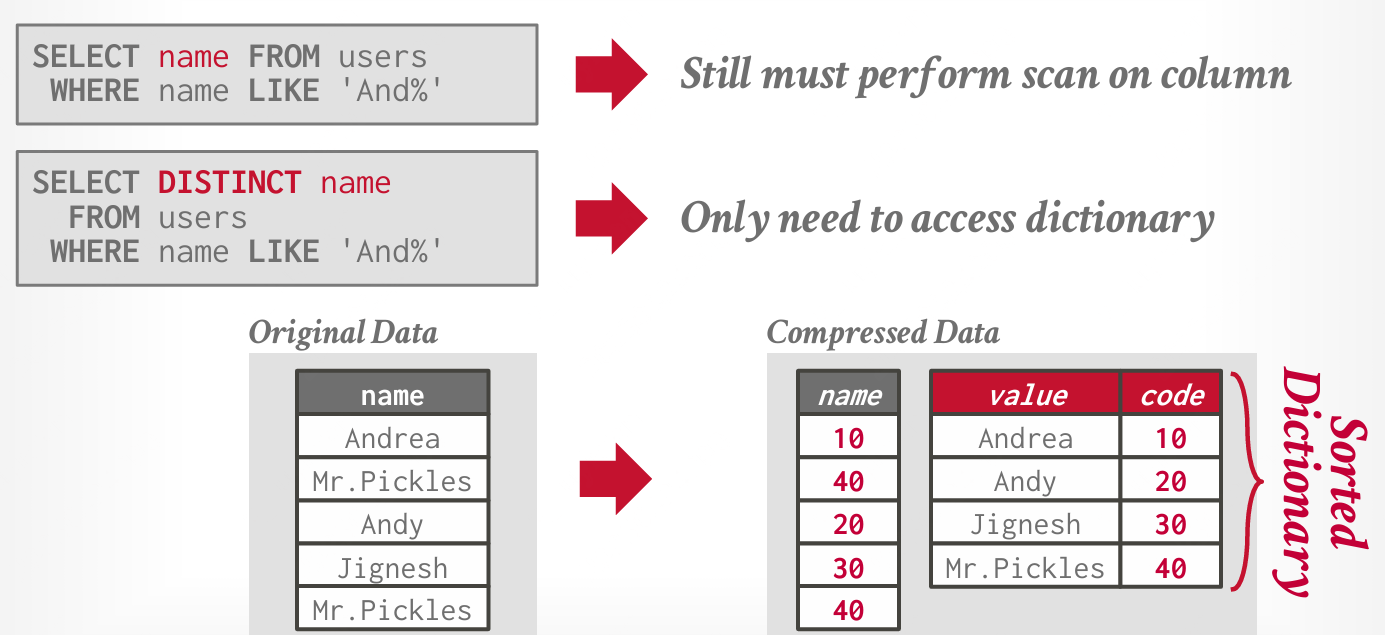
在某些查询(如字符串匹配)中,查询可以在压缩数据上执行得更快。
