CMU15-445 Lecture#03,#04 数据库存储
本篇博客为CMU15-445(2024 Fall)中数据库存储部分的理论学习笔记。
存储结构
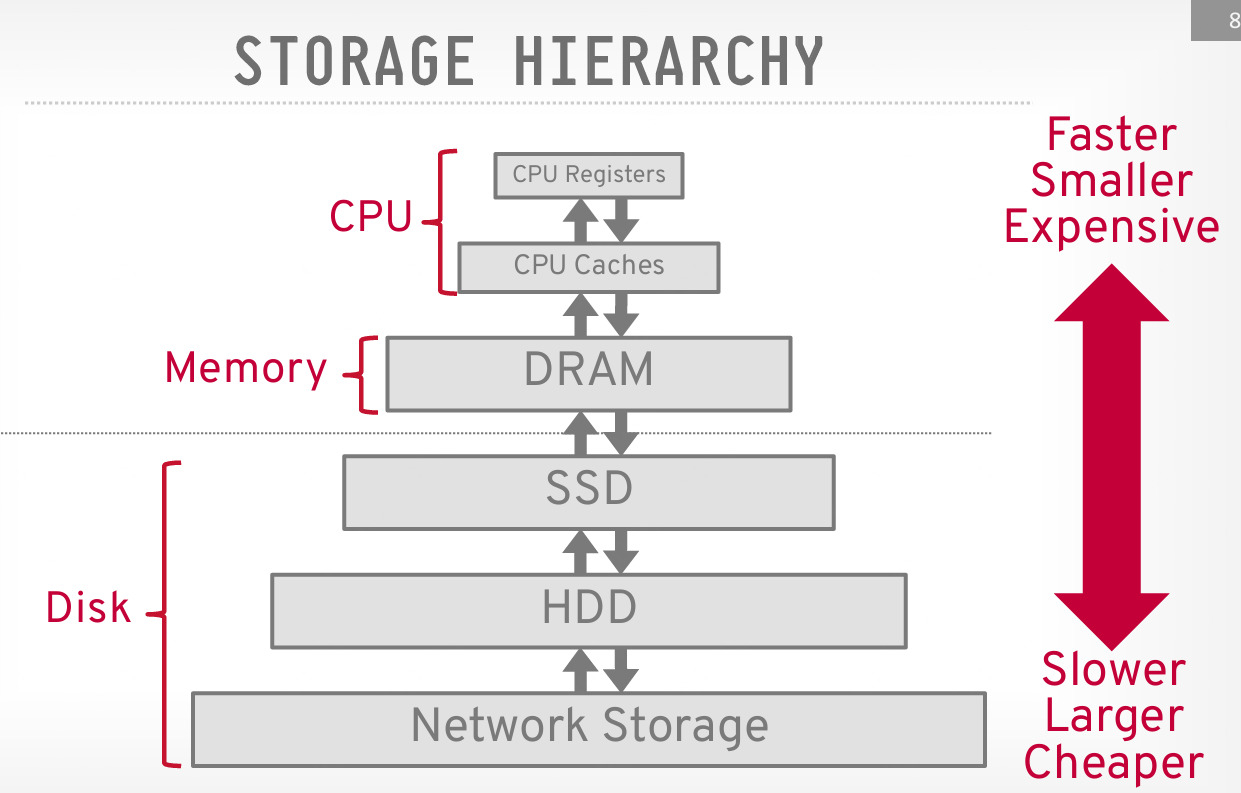 存储层次结构的最上面是离 CPU 最近的设备。这些设备速度最快,但也是最小且最贵的;随着距离 CPU 的增加,存储设备变得更大,但更慢。每 GB 存储的成本也会下降。
存储层次结构的最上面是离 CPU 最近的设备。这些设备速度最快,但也是最小且最贵的;随着距离 CPU 的增加,存储设备变得更大,但更慢。每 GB 存储的成本也会下降。
易失性设备
- 易失性:如果拔掉机器的电源,数据将丢失;
- 易失性存储支持快速的随机访问,具有字节可寻址的地址。这意味着程序可以跳到任何字节地址并获取数据。
非易失性设备
- 非易失性:该存储设备不需要持续供电,就能保持它存储的位;
- 块/页面可寻址:要读取某个特定偏移位置的值,程序必须先加载包含该值的 4 KB 页面到内存中;
- 适合顺序访问(一次读取多个连续的数据块)。
- 我们将其称为“磁盘”,暂时不会区分固态存储(SSD)和旋转硬盘(HDD)。
持久内存
介于DRAM和磁盘之间,结合了 DRAM 的快速性和磁盘的持久性。
持久内存的设计目标是达到两者的最佳平衡。最著名的例子是 Optane。
NVMe 表示非易失性内存快车。这些 NVMe SSD 并不是持久内存模块,而是通过改进的硬件接口连接的典型 NAND 闪存驱动器。这种硬件接口的改进允许更快的传输,从而提升了 NAND 闪存的性能。
磁盘导向DBMS概述
系统假设数据全存储在磁盘上,数据库文件中的数据组织成页面,第一页是目录页。DBMS的任务就是从磁盘到内存之间来回移动数据(因为系统不能直接对磁盘进行操作)。为了操作这些数据,DBMS 需要将数据加载到内存中。它通过一个缓冲池,来管理数据在磁盘和内存之间的移动。
DBMS 还有一个执行引擎来执行查询。执行引擎会请求缓冲池提供某个特定的页面,缓冲池会负责将该页面加载到内存中,并向执行引擎提供指向该页面的指针。缓冲池管理器将确保页面在内存中,执行引擎可以在该内存区域操作。 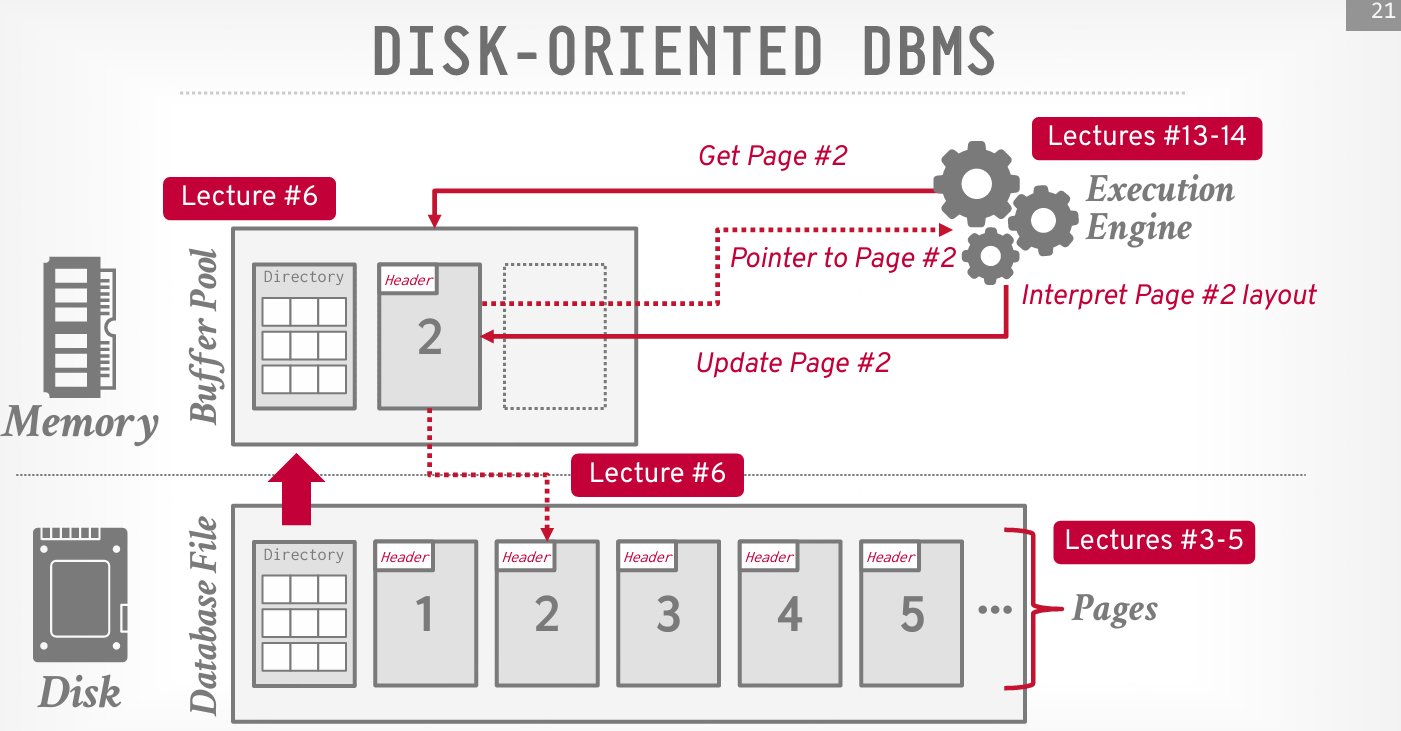
DBMS与操作系统的关系
DBMS 的一个高层设计目标是:支持超过可用内存的数据库。由于读写磁盘非常昂贵,必须小心管理磁盘的使用。我们不希望从磁盘获取数据的操作导致大的停顿,影响其他操作的执行;而希望 DBMS 能在等待从磁盘获取数据时,继续处理其他查询。
这个高层设计目标类似于虚拟内存,其中有一个大的地址空间,操作系统可以从磁盘中读取页面。在 DBMS 中实现虚拟内存的一种方式是:使用 mmap 将文件的内容映射到进程的地址空间,这使得操作系统负责在磁盘和内存之间移动页面;mmap 如果发生页面错误,将会阻塞进程。
也通过一些指令来指导操作系统进行page的替换(madvise, mlock, msync);
如果我们的数据库只需要读取数据的话,使用mmap实际上是可行的,但是问题在于我们并不仅仅需要读。如果有写操作,那么操作系统是不知道那些page需要在其他page执行前,从内存刷到磁盘上的,这将会与日志与并发控制的实现有关。因此若需要写入,则不应使用mmap。
总的来说,相比使用mmap,让DBMS自己管理page始终会是一个更加高效且安全的做法,可以更好地支持: 1. 将脏页按照正确顺序刷新到磁盘; 2. 专门的预取规则; 3. 缓冲区替换策略; 4. 线程与进程的调度
文件存储
实际上,除了专门定制了文件管理系统的DBMS(Oracle,DB2和SQL server),大多数DBMS将数据库文件按照特定格式编码,存储为磁盘上的文件;通过操作系统提供的API读写,并由存储引擎去管理和维护。
DBMS 的存储引擎负责管理数据库的文件。它将文件表示为页面的集合,每个页面有固定大小的块,并跟踪页面上的所有读写操作,以及页面中剩余的空闲空间。
数据库页面
DBMS 将数据库组织成一个或多个文件,数据以固定大小的块(页面)进行存储。页面可以包含不同类型的数据(元组、索引等);大多数系统不会将这些类型混合在同一页面内。
有些系统要求页面是自包含的:即读取页面所需的所有信息都在页面本身上。
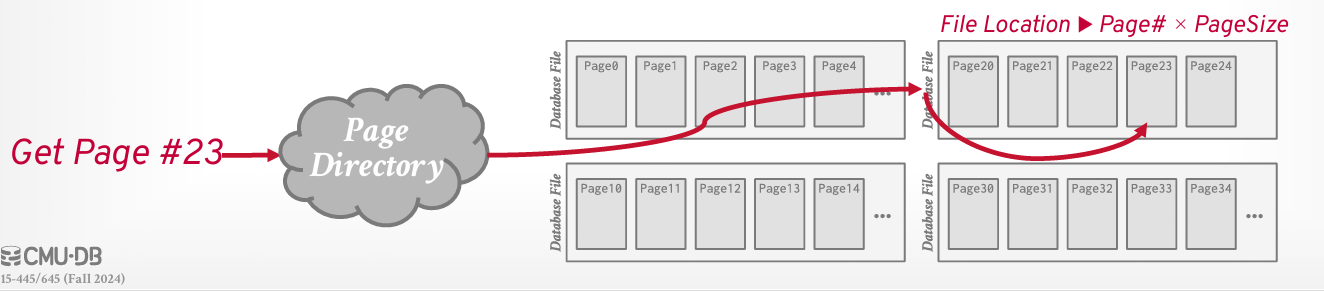
每个页面都有一个唯一的标识符(页面 ID)。如果数据库只有一个文件,则页面 ID 可以是文件偏移量。页面 ID 可以是每个 DBMS 实例、每个数据库或每个表唯一的。大多数 DBMS 都有一个间接层,将页面 ID 映射到文件路径和偏移量。
在调用文件时:系统的上层会请求特定的页面编号;然后,存储管理器需要将页面编号转换为文件路径和偏移量,以便找到该页面。
在文件整体移动后,只要知道整体文件的初始位置,依然可以通过相对位置(即page ID)找到某个文件某个位置的数据所对应的page。方便支持磁盘的压缩,以及使用另一块磁盘而不改变page ID。
大多数 DBMS 使用固定大小的页面,以避免支持可变大小页面所带来的工程开销。例如,对于可变大小的页面,删除页面可能会在文件中产生一个空洞,DBMS 无法轻松填充这些空洞。
页面类型
DBMS有三个页面概念: 1. 硬件页面(通常为 4 KB);
* 存储设备保证**硬件页面的原子写入**:如果硬件页面是 4 KB,则系统尝试写入 4 KB 数据时,要么全部写入,要么都不写入;这意味着:如果数据库页面大于硬件页面,DBMS 必须采取额外措施来确保数据安全写入,因为在系统崩溃时,程序可能只写入了一部分数据库页面。- 操作系统页面(4 KB,x64 2MB/1GB);
- 数据库页面(1-16 KB)


专门针对只读工作负载的 DBMS ,通常会使用较大的页面大小。
DBMS文件组织方式
不同的 DBMS 以不同的方式管理磁盘上的页面文件:
- 堆文件组织(Heap File Organization)
- 树形文件组织(Tree File Organization)
- 顺序/排序文件组织(ISAM,索引顺序访问方法)
- 哈希文件组织(Hashing File Organization)
堆文件组织
DBMS 查找磁盘上页面的位置的一种方式:是使用堆文件组织。堆文件是一个无序的页面集合,其中元组以随机顺序存储。
- 创建/读取/写入/删除页面
- 支持在所有页面上的迭代
DBMS 可以使用:链表或页面目录,来定位磁盘上的特定页面。
链表:头页面包含指向自由页面列表和数据页面列表的指针。但是,如果 DBMS 想要查找特定页面,它必须在数据页面列表中进行顺序扫描,直到找到目标页面。
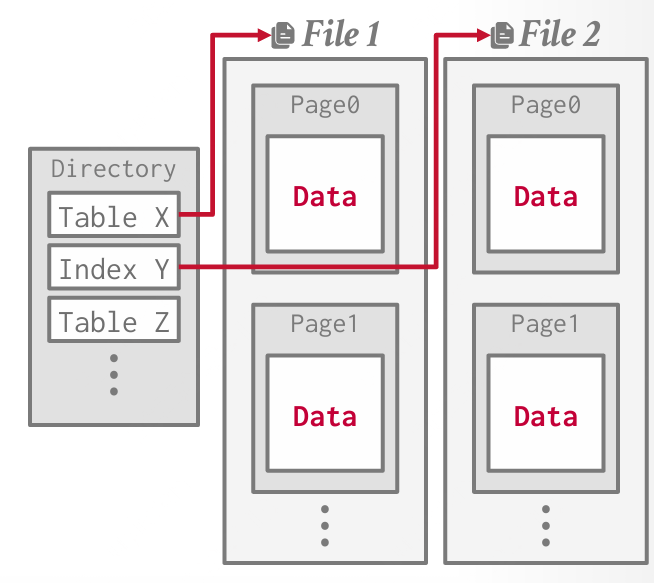
页面目录:DBMS 维护特殊的页面,称为页面目录,用于跟踪数据页面的位置、每个页面上的空闲空间量、空闲/空页面的列表以及页面类型。这些特殊页面为每个数据库对象提供一个条目。
元组布局(Tuple-oriented)
元组本质上是字节序列(这些字节不一定是连续的);DBMS 的工作是解释这些字节,并将其转换为属性类型和值。
元组头部
元组头部包含元数据:
- DBMS 的并发控制协议中的可见性信息(例如,记录哪个事务创建/修改了该元组);
- NULL 值的位图。
注意:DBMS 在这里不需要存储数据库模式的元数据。
元组数据:属性的实际数据
属性通常按照:创建表时指定的顺序存储。;大多数 DBMS 不允许一个元组的大小超过页面大小。 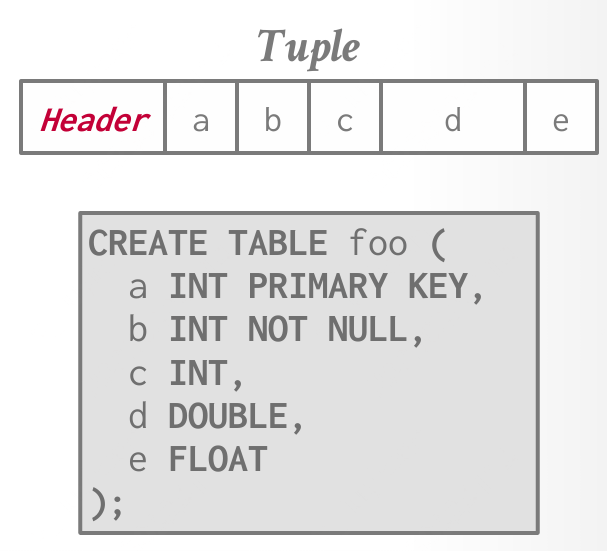
元组的唯一标识符
每个元组在数据库中都有一个唯一标识符;最常见的方式是:页面 ID +(偏移量或插槽)。
应用程序不能依赖这些标识符来表示任何含义。
去规范化元组数据
如果两个表是相关的,DBMS 可以将它们“预先连接”在一起,使得它们存储在同一个页面上。这样可以加快读取速度,因为 DBMS 只需要加载一个页面,而不是两个单独的页面。然而,这样做会增加更新的成本,因为 DBMS 需要为每个元组更多的存储空间。 
页面布局
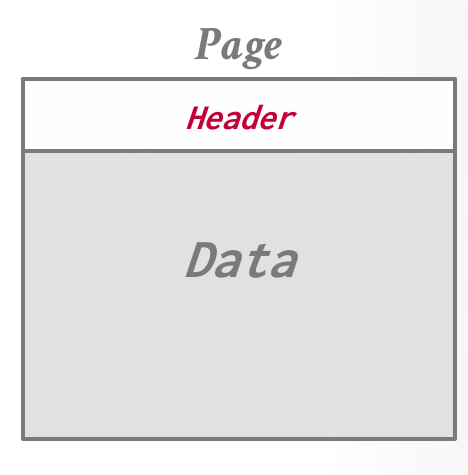 每个页面都包括一个头部,用于记录页面内容的元数据:
每个页面都包括一个头部,用于记录页面内容的元数据:
- 页面大小
- 校验和
- DBMS 版本
- 事务可见性(一些数据查询和修改的权限等)
- 自包含性(例如 Oracle 要求此项)。
一种简单的的数据布局方法是:跟踪 DBMS 已存储在页面中的元组数,然后每次添加新的元组时将其附加到页面末尾。然而,当元组被删除或元组具有可变长度属性时,问题就出现了。
DBMS 中有两种主要的数据布局方法:插槽页、日志结构化。
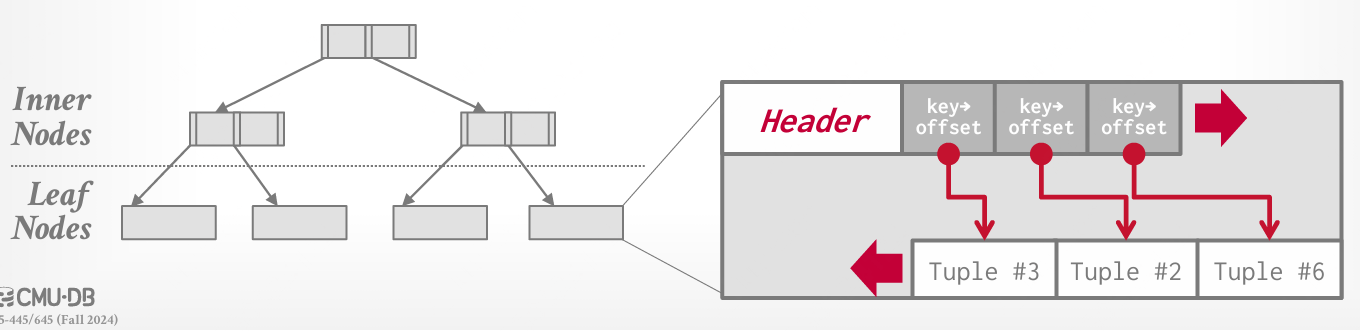
插槽页(Slotted-Page)
页面头部跟踪:已使用插槽的数量;最后一个已使用插槽的起始位置的偏移量;一个插槽数组(将插槽映射至元组的起始位置偏移量) > 每个元组可以通过:一个page id,一个slot id来定位。
要添加元组,插槽数组会从页面开始向末尾增长,而元组的数据将从页面末尾向前增长;当插槽数组和元组数据相遇时,页面被视为已满。 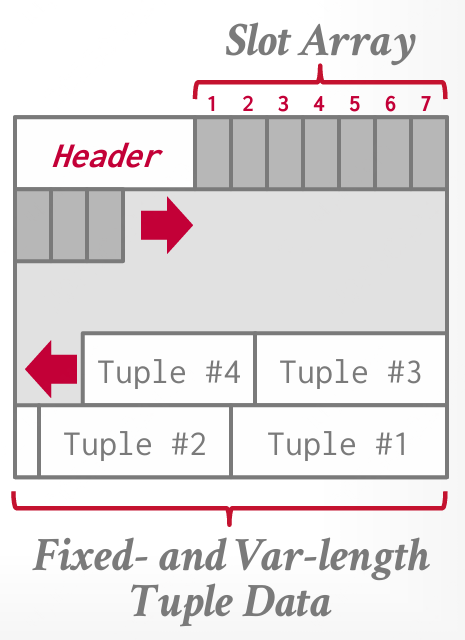
插入新元组
- 检查页面目录:找到具有空闲插槽的页面;
- (如果不在内存中)从磁盘中检索页面;
- 检查插槽数组:找到页面中空闲的合适位置,插入新元组。
更新现有元组(使用其记录ID)
- 检查页面目录以找到页面的位置;
- 从磁盘中检索页面(如果不在内存中)
- 检查插槽数组:找到页面中的偏移位置;
- 如果新数据适合,覆盖现有数据。
- 否则,将现有元组标记为已删除,并在不同的页面中插入新版本。
插槽页的几个问题
基于Slotted-Page的元组导向架构存在几个问题:
- 碎片化:删除元组可能会在页面中留下空隙,导致页面不能被充分利用;
- 无用磁盘 I/O:由于非易失性存储的块导向特性,需要加载整个块来更新一个元组;
- 随机磁盘 I/O:磁盘读取器可能需要跳到 20 个不同的位置,来更新 20 个不同的元组,这会非常慢。
索引组织存储
将表中元组存储为:索引的值(页面中依照元组的键排序)
B+树提前支付维护成本,而 LSM 树则是稍后支付维护成本。
日志结构存储(Log-Structured Storage)
假设我们正在处理一个只允许创建新页面、不允许覆盖的系统(例如 HDFS、Google Colossus 或一些对象存储),日志结构存储模型可以解决上述一些问题。
这种存储方式并不存储page的元组,而是去存储如何创建以及如何修改tuple的信息(即存储log信息)。这样做的好处有很多:首先是方便回滚,因为用了日志数据结构后,回滚只需要删除某些log即可完成;更重要的是高效,因为顺序读写比随机读写要快得多。
场景:如果要更新10个元组,而这10个元组的信息存储在10个pages上,那么我们就要修改10个page的信息;但是如果是日志结构,就只需要把相关的更新语句存储在1个page上即可。
日志结构存储概述
日志结构存储基于:日志结构文件系统(LSFS)和日志结构合并树(LSM Tree)。
与将元组存储在页面中并就地更新它们不同,DBMS 只存储元组更改的日志记录。每条日志记录对应:一个元组的插入/删除操作。每条记录包括:元组的唯一标识符、操作类型(PUT/DELETE),对于 PUT 操作,还包含元组的内容。
步骤
将更改应用到内存数据结构(MemTable);
将更改按顺序写入SSTable;
DBMS 在写入磁盘之前,会根据键的顺序将每个 SSTable 排序;再将每个SSTable写入磁盘。 > 磁盘写入是顺序的,现有的页面是不可变的,这减少了随机磁盘 I/O。这对追加式存储非常有利
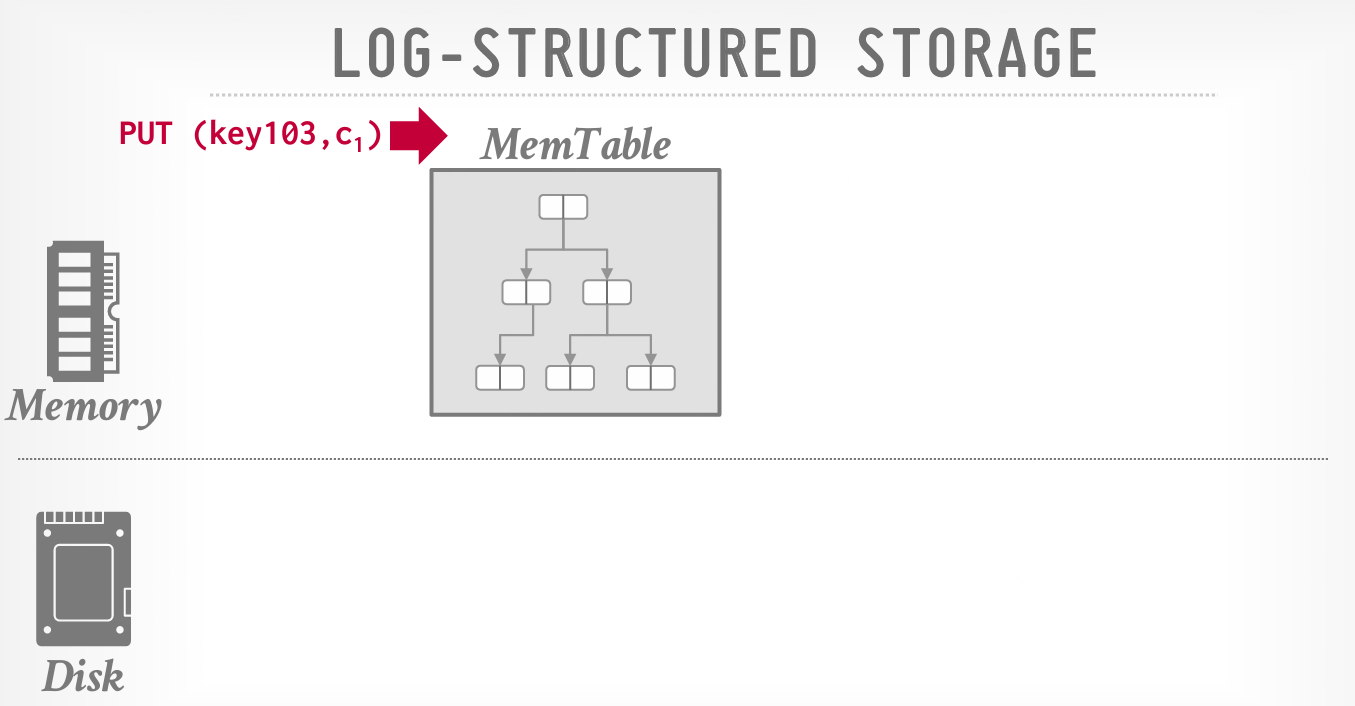
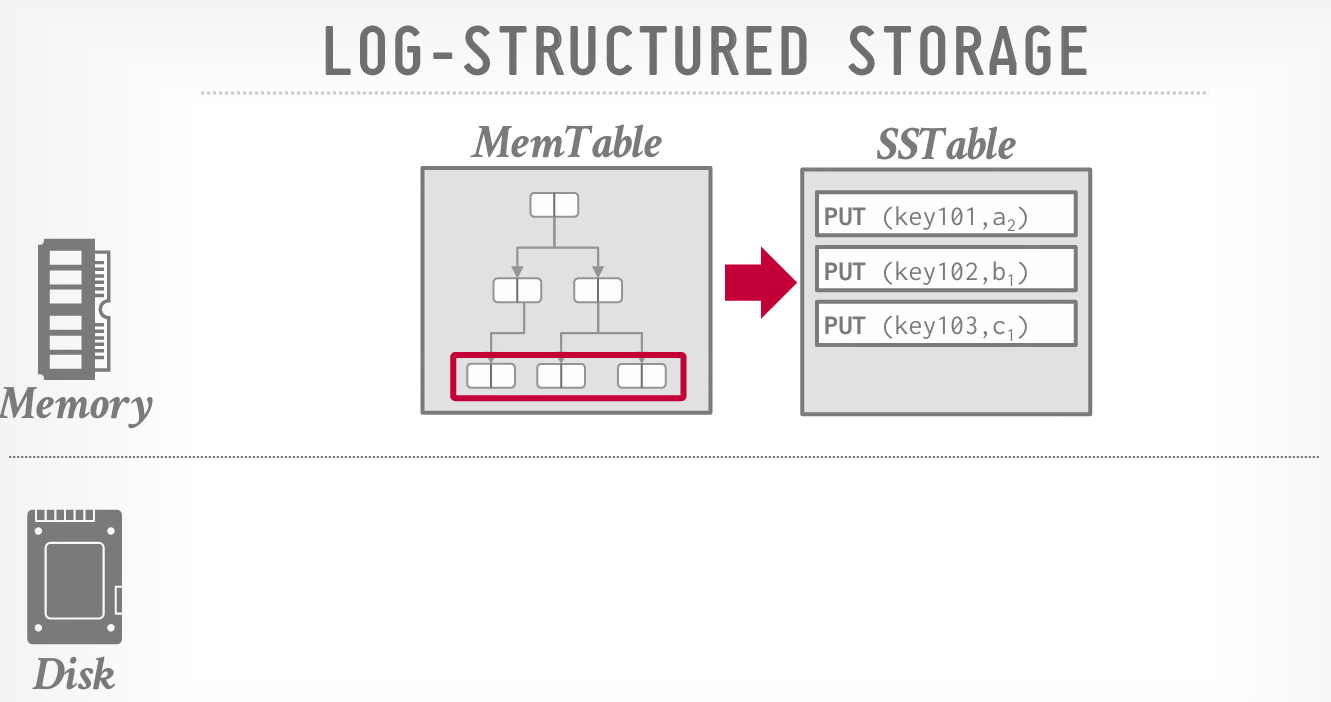
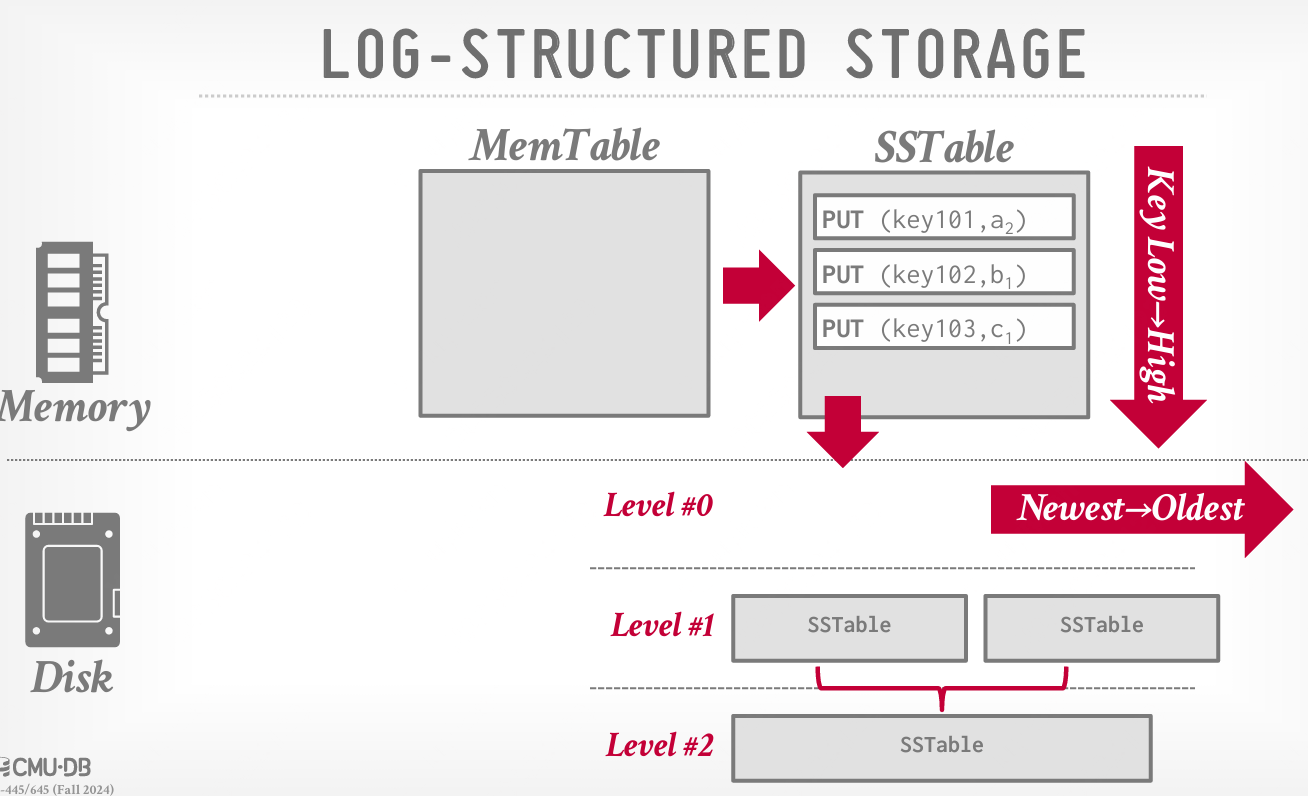
DBMS 将更改应用到内存数据结构(MemTable),然后将更改按顺序写入磁盘(SSTable)。记录包含元组的唯一标识符、操作类型(PUT/DELETE),对于 PUT 操作,还包含元组的内容。实际上,DBMS 只跟踪每个键的最新值(最新的 PUT/DELETE)。
显著地,就地更新应用到内存数据结构,因为这样更快,而磁盘写入是顺序的,现有的页面是不可变的,这减少了随机磁盘 I/O,对追加式存储非常有利。DBMS 在写入磁盘之前,会根据键的顺序,将每个 SSTable 排序。
SummaryTable
出现背景:为了读取记录,DBMS 首先检查 MemTable 看是否存在该键;如果 MemTable 中没有该键,DBMS 就需要检查每个级别的 SSTable:暴力解决方案是扫描 SSTable,从最新到最旧,并在每个 SSTable 内部进行二分查找,找到最最新的元组内容,这可能会很慢。
解决方案:DBMS 维持一个内存中的 SummaryTable ,来跟踪每个 SSTable 的附加元数据,如每个 SSTable 的最小/最大键和每个级别的键过滤器(例如,布隆过滤器)。 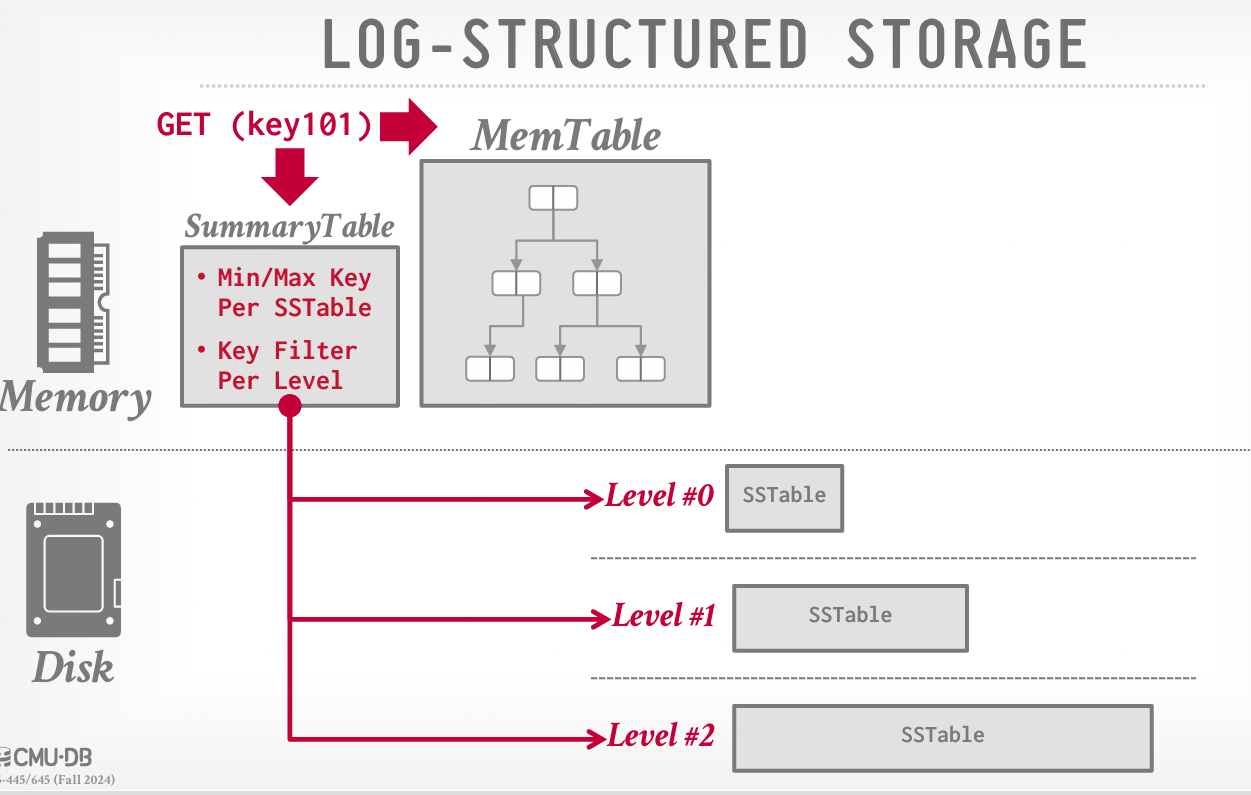
压实
问题背景:在写入密集型的工作负载下,DBMS 会在磁盘上积累大量 SSTable。 解决方案:DBMS 定期使用排序合并算法来压实日志,保留每个元组的最新更改。这样可以减少浪费的空间并加快读取。 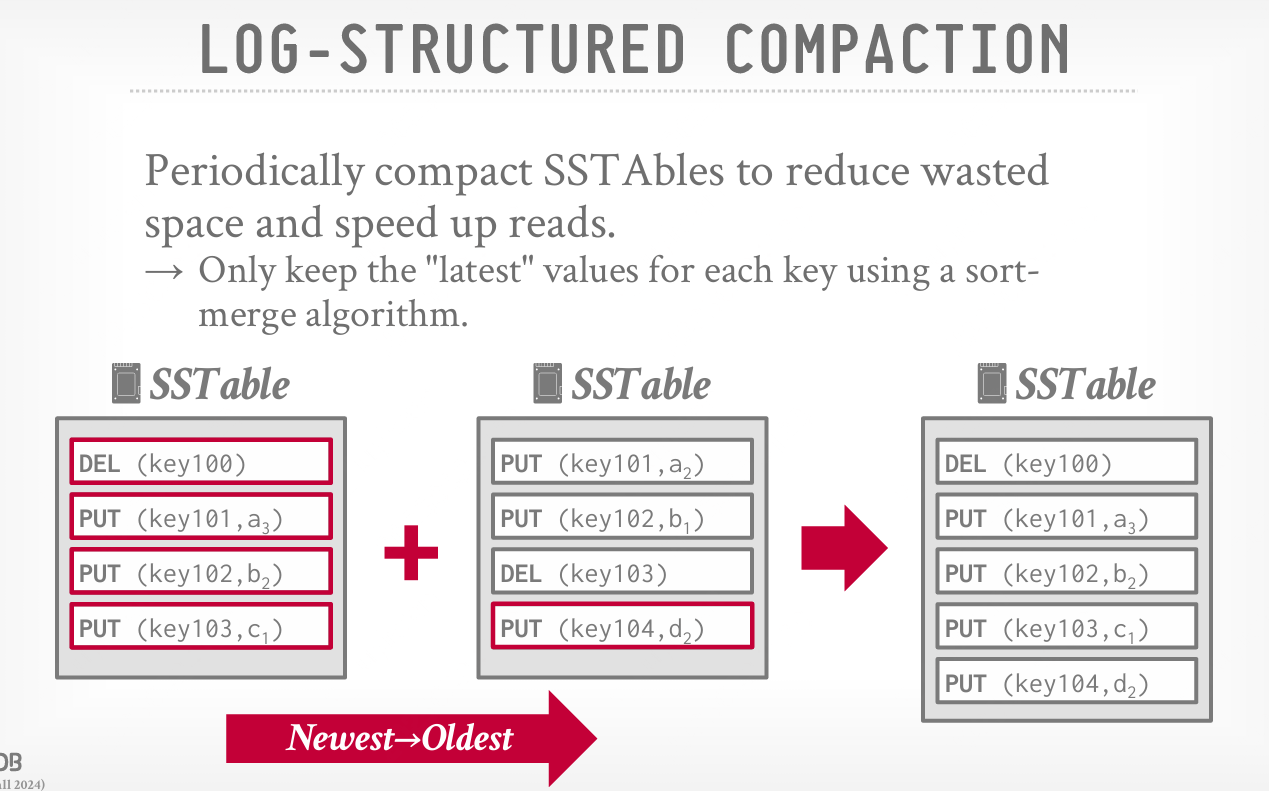 压实方法分类:
压实方法分类:
- Universal Compaction:任何日志文件都可以一起压实。
- Level Compaction:最小的文件是第 0 级文件,第 0 级文件可以压实以创建更大的第 1 级文件,第 1 级文件可以压实为第 2 级文件,依此类推。
- Tiering 是另一种日志压实方法,在本课程中不做介绍。
权衡
使用日志结构存储的权衡如下:
- 顺序写入速度快,适合追加式存储;
- 方便写,不方便读;
- 压实是昂贵的;
- 写放大效应(每个逻辑写入可能对应多个物理写入)。
数据表示
元组中的数据本质上是:带有头部的字节数组,头部包含关于数据的元数据。它并不跟踪属性的数据类型,DBMS 负责知道如何跟踪并解释这些字节。
字节对齐
DBMS 希望确保元组的字节对齐,以便 CPU 可以高效访问它,而不产生任何意外行为或额外的工作。通常采用两种方式:填充和重新排序。 #### 填充(Padding) 在属性后添加空位,确保元组字节对齐。 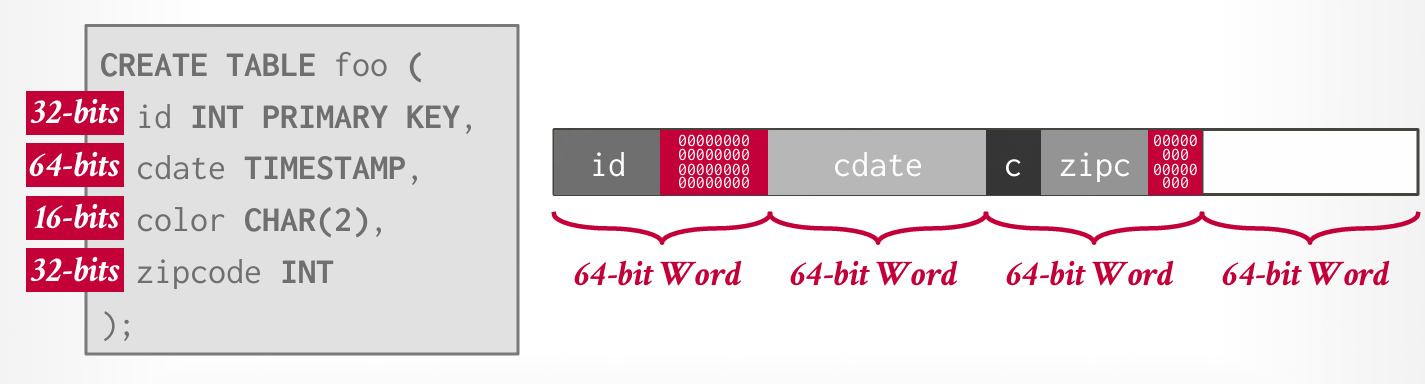 #### 重新排序(Reordering) 改变物理布局中属性的顺序,确保它们对齐。
#### 重新排序(Reordering) 改变物理布局中属性的顺序,确保它们对齐。 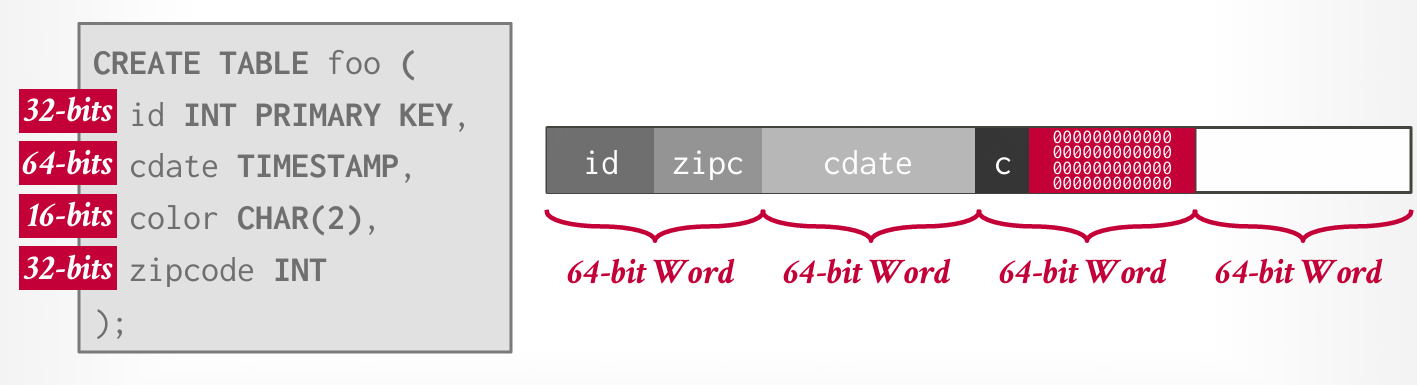
5种数据类型
元组中可以存储五种高层数据类型:整数、可变精度数字、定点精度数字、可变长度值和日期/时间。
整数
大多数 DBMS 使用其“本地”的 C/C++ 类型来存储整数,这些类型是由 IEEE-754 标准指定的。这些值是固定长度的。 例如:INTEGER、BIGINT、SMALLINT、TINYINT。
可变精度数字
不精确的、可变精度的数字类型,使用 IEEE-754 标准指定的本地 C/C++ 类型存储。它们的长度也是固定的。 例如:FLOAT、REAL、DOUBLE。
可变精度数字通常比固定精度数字的计算速度更快,因为 CPU 体系架构 (Xeon, Arm)有指令/寄存器支持专门的运算。
固定精度数字
这些是具有任意精度和标度的数字数据类型。它们通常以不精确的、可变长度的二进制表示存储(几乎像字符串一样),并附加元数据来告诉系统数据的长度和小数点的位置。 例如:NUMERIC、DECIMAL。
如果DBMS不提供任意精度,开销可降低。
可变长度数据
任意长度的数据类型。它们通常以header的方式存储,header跟踪字符串的长度,以便跳到下一个值。它们可能还包含数据的校验和。例如:VARCHAR、VARBINARY、TEXT、BLOB。
日期和时间
日期/时间的表示方法在不同系统中有所不同。通常,它们表示为自 Unix 纪元以来的某个单位时间(微秒/毫秒)。 例如:TIME、DATE、TIMESTAMP。
Null 数据类型
在 DBMS 中有三种常见的表示 NULL 的方法:
NullColumnBitmapHeader:在一个集中式的头部存储位图,指定哪些属性为NULL;(最常见的方法)- 特殊值:为数据类型指定一个值表示
NULL(例如,INT32 MIN)。 Per-Attribute Null Flag:为每个属性存储一个标志,表示该值为NULL。(它在内存上效率较低)
大值
例如:VARCHAR、VARBINARY、TEXT、BLOB。 大多数 DBMS 不允许元组的大小超过单个页面的大小。如何处理超出部分呢?
溢出页
将数据存储在特殊的“溢出”页面上,并且元组会包含指向该页面的引用;这些溢出页面可以包含指向其他溢出页面的指针,直到所有数据都能存储为止。 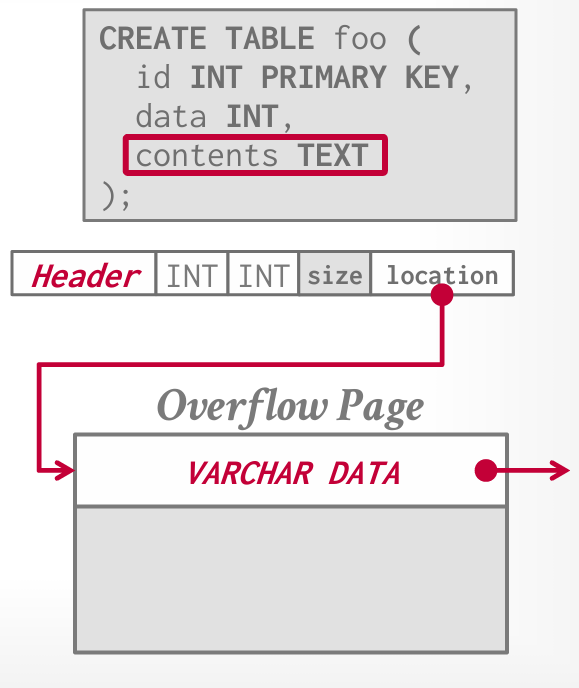 这样管理起来就是一些特殊的page,但在一些持久性等问题上,需要做特别的处理;这对于应用程序透明,你并不会知道自己是否使用了overflow page。
这样管理起来就是一些特殊的page,但在一些持久性等问题上,需要做特别的处理;这对于应用程序透明,你并不会知道自己是否使用了overflow page。
外部值
一些系统允许将大值存储在外部文件中,通常将其视为 BLOB 类型。
- Oracle:
BFILE数据类型 - Microsoft:
FILESTREAM数据类型
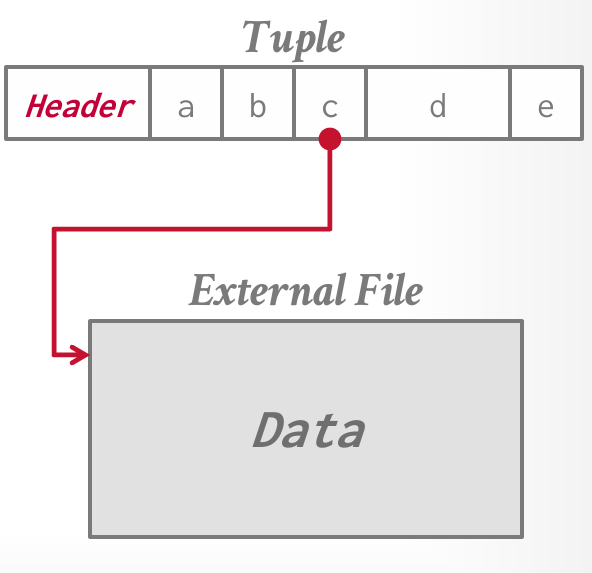
缺点:存储在外部文件中。这样实现简单,但是DBMS无法提供持久性保证和事务隔离能力。
系统目录
DBMS维护一个内部目录,告诉它关于数据库的元数据。内容为:
- 数据库中的表和列信息,以及这些表上的索引;
- 数据库用户及其权限;
- 表的统计信息,以及包含的内容(例如,某属性的最大值)。
