大模型推理框架vLLM:paper + code 解析
论文解读:Efficient Memory Management for Large Language Model Serving with PagedAttention
Abstract
为了提供LLM的高吞吐量服务,每次需要批量处理足够多的请求。然而现有系统面临KV缓存内存不足的挑战:每个请求的KV缓存内存占用巨大,且动态增减。当内存管理效率低下时,碎片化和冗余复制会造成显著的内存浪费,从而限制批处理规模。为解决这一问题,我们提出PagedAttention,这是一种受经典操作系统虚拟内存与分页技术启发的注意力算法。基于此,我们构建了vLLM这一LLM服务系统,其实现了:(1) KV缓存内存接近零浪费;(2) 支持请求内及跨请求的KV缓存灵活共享,进一步降低内存占用。评估表明,在相同延迟水平下,vLLM将主流LLM的吞吐量较FasterTransformer、Orca等最先进系统提升了2-4倍。当处理更长序列、更大模型及更复杂解码算法时,性能提升尤为显著。
Introduction
当前LLM serving system主要面临:KV缓存的管理问题。通常做法是将一条request的KV cache存储在连续的内存空间内(大部分deep learning框架要求tensors在连续内存空间中存储)。KV cache和tensors的区别在于: 1. KV Cache随模型生成新token,而动态增减; 2. 其生命周期和长度无法提前预测。
因此,在两个方向上导致了内存使用的低效:
内存的内外碎片:为满足连续空间存储的要求,需要预先分配一段连续的最大内存空间(例如:2048 tokens),这会导致内部碎片(request的实际长度小于最大长度);
即使长度预知,预先分配也是低效的:在request的生命周期内,内存块为其保留;导致其他更短的request也无法使用当前空闲的内存块。
另外,对于每个request,预分配不同长度的空间,会导致外部碎片。
未实现内存共享的最大优化:LLM通常采用advanced decoding算法(并行采样或束搜索),这些算法为每个request生成多个输出序列,可以部分共享KV Cache,但已有系统未考虑这一点。
PagedAttention的想法是什么呢?提出了页式虚拟内存机制。
将request的KV cache拆分为多个blocks:每个block包括固定数量tokens的attention keys和values。因此,KV Cache无需存储在连续内存空间。 > 联动OS的理念:将blocks当作页面;tokens当作字节;requests当作进程。 > > 这个设计通过使用更小尺寸的的blocks和按需分配,消除内部碎片;通过固定大小的blocks消除外部碎片。
BackGrounds
基于Transformer的LLM
LLM的任务是:对token序列\((x_1, x_2, ..., x_n)\)的概率模型建模。采用自回归分解:将整个序列的联合概率,分解为条件概率的乘积: \[ P(x)=P(x_1)\cdot P(x_2|x_1)\cdot\cdot\cdot P(x_n|x_1,...,x_{n-1}). \]
Transformer模型是大规模概率建模的事实标准架构,其核心组件是自注意力层(self-attention layer)。处理输入隐藏状态序列\((x_1, ..., x_n)\in\mathbb{R}^{n\times d}\)时,首先对每个位置\(i\)进行线性变换生成查询(query)、键(key)和值(value)向量: \[ q_i=W_q x_i, k_i=W_k x_i, v_i=W_v x_i. \] 随后,该层通过计算当前位置query向量与所有历史位置的key向量的点积,得到注意力分数\(a_{ij}\): \[ a_{ij}=\frac{\exp(\frac{q_i^{T}k_j}{\sqrt{d}})}{\sum_{t=1}^{i}\exp(\frac{q_i^{T}k_t}{\sqrt{d}})}, o_i=\sum_{j=1}^{i}a_{ij}v_j. \]
LLM服务&自回归生成
经过训练后,大型语言模型(LLM)通常被部署为条件生成服务(例如自动补全API或聊天机器人)。向LLM服务发出的请求会提供一组input prompt tokens\((x_1,x_2,...,x_n)\),LLM服务则根据自回归分解公式,生成output tokens\((x_{n+1},x_{n+2},...,x_{n+T})\)。将input prompt tokens与output tokens的组合称为序列(sequence)。
由于自回归分解公式的分解特性,LLM只能逐个采样生成新token,且每个新token的生成过程都依赖于该序列中所有先前的tokens——特别是它们的键(key)和值(value)向量。在这一顺序生成过程中,现有token的键值向量,通常会被缓存以供后续token生成使用,即KV缓存(KV cache)。需要注意的是,某个token的KV缓存取决于其之前的所有token,这意味着同一token出现在序列不同位置时,其KV缓存也会不同。
对于给定的一个request prompt,生成过程分为两个阶段:
prompt phase:以完整用户prompt\((x_1,x_2,...,x_n)\)为输入,计算首个新token的概率\(P(x_{n+1}|x_1,...,x_n)\)。在此过程中,同时生成键向量\(k_1,...,k_n\)和值向量\(v_1,...,v_n\)。由于token\(x_1,...,x_n\)均为已知,该阶段可通过矩阵-矩阵乘法实现并行计算,因此能充分利用GPU的并行计算优势。
autoregressive generation phase:按顺序生成剩余新tokens。在第\(t\)次迭代时,模型接收单个token\(x_{n+t}\)作为输入,基于缓存的键向量\(k_1,...,k_{n+t-1}\)和值向量\(v_1,...,v_{n+t-1}\),计算概率\(P(x_{n+t+1}|x_1,...,x_{n+t})\),并生成新的键值向量\(k_{n+t}\)和\(v_{n+t}\)。该阶段在序列达到最大长度(用户指定或模型限制)或生成结束符
时终止。由于数据依赖性,不同迭代的计算无法并行化,且多采用效率较低的矩阵-向量乘法运算,导致GPU计算资源利用率严重不足,形成内存瓶颈——这构成了单个请求延迟的主要来源。
LLM批处理
由于同一批次内的请求共享模型权重,权重加载的开销可被批量请求均摊——当批次规模足够大时,计算开销将完全覆盖权重传输成本。然而LLM 批处理面临两大挑战:
- 请求的异步到达特性。若采用简单批处理策略,要么让先到请求等待后续请求(导致排队延迟),要么推迟新请求直至当前批次完成(造成吞吐量下降)。
- 请求的输入输出长度差异巨大。若强行通过填充(padding)对齐序列长度,将导致GPU计算资源和内存的严重浪费。
为解决这些问题,学界提出了细粒度批处理机制(如蜂窝批处理和迭代级调度)。与传统请求级批处理不同,这些技术基于迭代维度运作:每完成一次迭代,系统便移除已处理完成的请求,并动态加入新请求。这使得新请求仅需等待单个迭代周期即可被处理,无需阻塞至整批请求完成。此外,借助专用GPU内核,这些技术彻底消除了序列填充需求。通过降低排队延迟与填充损耗,细粒度批处理机制能显著提升LLM服务的吞吐效率。
Methods
PagedAttention
将每个序列的KV Cache分为若干个KV blocks,每个block包含:固定数量的键向量和值向量。将key block表示为:\(K_j=(k_{(j-1)B+1},...,v_{jB})\);value block表示为:\(V_j=(v_{(j-1)B+1},...,v_{jB})\).注意力计算公式变为: \[ A_{ij}=\frac{\exp(\frac{q_{i}^{T}K_j}{\sqrt{d}})}{\sum_{t=1}^{\lceil \frac{i}{B}\rceil}\exp(\frac{q_{i}^{T}K_t}{\sqrt{d}})}, o_i=\sum_{j=1}^{\lceil \frac{i}{B}\rceil}V_jA_{ij}^T \] 其中,\(A_{ij}=(a_{i,(j-1)B+1},...,a_{i,jB})\)是第\(j\)个KV block的注意力分数。
在注意力计算过程中,PagedAttention内核会动态识别、并分别获取不同的KV块。如图所示,键值向量分散存储在三个非连续物理内存块中(例如块0存储"Four score and seven"的键值向量)。 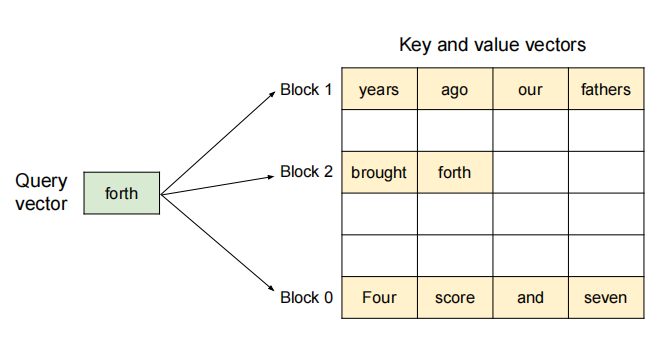 内核执行分阶段计算:
内核执行分阶段计算:
- query-key交互:每一次计算中,内核将query token("forth")的query向量\(q_i\),与一个block内的key向量\(K_j\)相乘,以计算注意力分数\(A_{ij}\)。
- value聚合:将\(A_{ij}\)与当前块的\(V_j\)相乘,生成局部注意力输出\(o_i\)。
总结来说,PagedAttention算法允许KV blocks存储在非连续的物理内存空间,使得vLLM中能够采用更灵活的页内存管理。
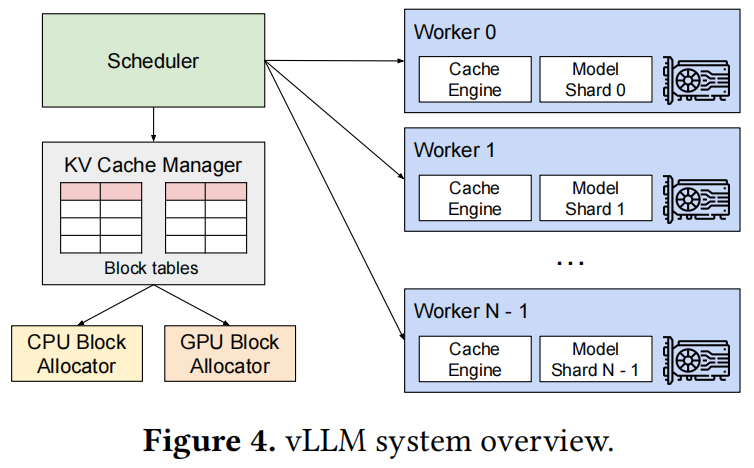
KV Cache Manager
vLLM内存管理器的核心设计思想源于:操作系统的虚拟内存机制。操作系统将内存划分为固定大小的页(page),并将用户程序的逻辑页映射到物理页上——连续的逻辑页可对应非连续的物理内存页,使得用户程序能以连续视角访问内存。更重要的是,物理内存空间无需预先全量分配,操作系统可按需动态分配物理页。
vLLM将虚拟内存的思想应用于LLM服务的KV缓存管理:
- 存储结构:
- 通过PagedAttention将KV缓存组织为固定大小的KV块(类比虚拟内存中的页);
- 每个请求的KV缓存表示为从左到右填充的逻辑KV块序列,末块预留空位供未来生成使用。
- 硬件资源管理:
- GPU工作节点:块引擎(block engine)分配连续GPU显存,并划分为物理KV块;
- CPU内存:同样分块以支持交换机制
- 映射系统:
- 块表(block table):维护逻辑KV块与物理KV块的映射关系
- 每个块表条目记录:
- 逻辑块对应的物理块地址
- 已填充位置数量
使用PagedAttention和vLLM解码
通过以下示例,说明vLLM如何在单输入序列的解码过程中执行PagedAttention并管理内存: 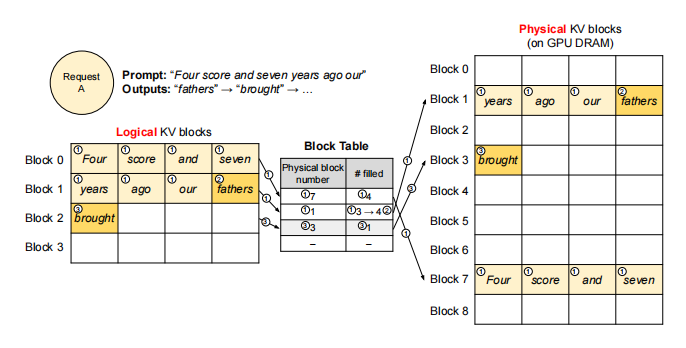
- prefill:与操作系统虚拟内存类似,vLLM无需预先为最大可能序列长度保留内存,而是仅分配prompt计算所需的KV块。
- 7个prompt tokens被分配到2个逻辑KV块(块0和块1);
- 逻辑块映射到物理块7和1;
- 使用常规自注意力算法,生成prompt的KV Cache和首个输出token;
- 前4个tokens存入逻辑块0,后3个tokens存入逻辑块1(末位预留空位)。
- 首次自回归解码
- 基于物理块7和1执行PagedAttention生成新token;
- 新生成的KV缓存存入逻辑块1预留槽;
- 块表中#filled字段更新。
- 二次解码
- 当逻辑块1写满时,分配新逻辑块;
- 从空闲池获取物理块3并建立映射;
- 更新块表记录新增的逻辑-物理块对应关系。
全局来看,vLLM在每次解码迭代时执行以下关键操作:
- 动态批处理构建:选择候选序列集合进行批处理;为新需求的逻辑KV块分配物理块。
- 输入序列整合:将当前迭代内,所有输入tokens拼接为单一序列:提示阶段请求的所有tokens+生成阶段请求的最新token
- 分页注意力执行:通过PagedAttention内核:访问以逻辑KV块形式存储的历史KV缓存;将新生成的KV缓存写入分配的物理KV块。
vLLM采用动态物理块分配机制:随着新token及其KV缓存的生成,系统持续为逻辑块分配新的物理块。其内存高效性体现在两个关键设计:
- 紧凑的内存布局:
- 严格遵循从左到右的填充顺序;
- 仅当所有现存块写满时,才分配新物理块;
- 将内存浪费严格限制在单个块容量内。
- 弹性资源共享:
- 请求完成生成后,立即释放其KV块,供其他请求复用;
 如图所示:两个序列的逻辑块,可映射到不同的物理块,实现GPU节点的内存共享。
如图所示:两个序列的逻辑块,可映射到不同的物理块,实现GPU节点的内存共享。
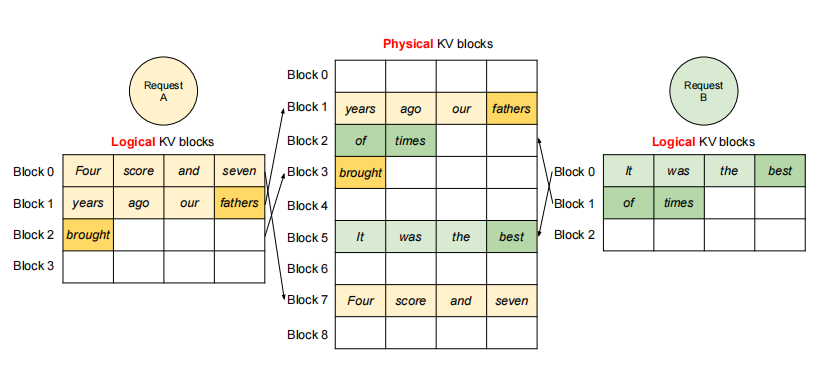 如图所示:两个序列的逻辑块,可映射到不同的物理块,实现GPU节点的内存共享。
如图所示:两个序列的逻辑块,可映射到不同的物理块,实现GPU节点的内存共享。vLLM在其他解码场景的应用
并行采样(Parallel Sampling)
对于一个输入prompt,LLM生成多个输出采样。用户可从多个候选者中,选出最喜欢的输出。
并行采样场景中,单个请求包含:共享相同输入prompt的多个输出样本,这使得prompt的KV缓存也可被共享。借助PagedAttention和分页内存管理机制,vLLM能够轻松实现这种内存共享优化。共享机制的实现如下图: 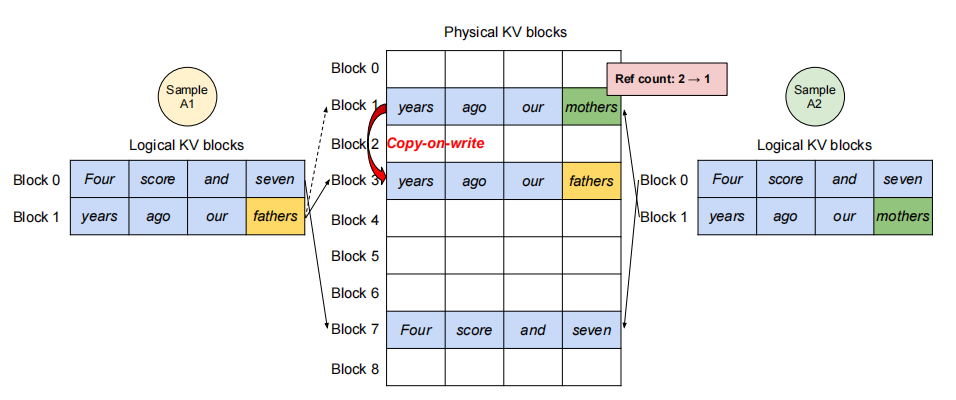
- prompt阶段:双输出样本共享相同的prompt,因此只保留一份prompt状态的拷贝;两个序列的prompts对应逻辑块,映射至相同的物理块。
- 逻辑块映射:序列A1/A2的逻辑块0 → 物理块7;序列A1/A2的逻辑块1 → 物理块1
- 物理块引用计数:物理块7和1的引用计数均为2
- generation阶段:写时复制机制(copy-on-write)
- 当样本A1需修改逻辑块1时:检测物理块1引用计数>1;分配新物理块3并复制原数据;物理块1引用计数降为1
- 样本A2写入物理块1时:引用计数已为1,直接写入
vLLM的技术优势:
- 内存节省:多个输出共享prompt的KV缓存,显著减少长提示词场景的内存占用;
- 安全隔离:块级写时复制,确保多样本修改隔离性;
- 零冗余设计:仅末位逻辑块需写时复制,其余物理块完全共享。
束搜索(Beam Search)
在机器翻译等LLM任务中,束搜索用于获取最优k个输出。通过束宽参数\(k\),控制每一步保留的候选序列数,有效避免全量遍历样本空间的计算复杂度。其工作流程分为三步:
- 候选扩展:对束内的每个候选序列,枚举词汇表\(V\)的所有可能续接tokens;
- 概率评估:调用LLM计算\(k\times |V|\)个候选序列各自的生成概率(\(|V|\)为词汇表大小)
- 择优保留:筛选概率最高的\(k\)个序列,进入下一轮迭代。
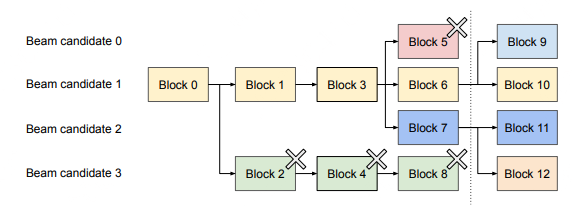
与并行解码不同,束搜索实现了更深层次的KV块共享机制:不止共享prompt对应block,不同候选序列也共享对应blocks,共享机制随着解码过程动态迭代。
- 动态共享拓扑:
- 所有候选序列,强制共享首个block(prompt block 0)
- 候选序列3从第2块开始分叉;候选序列0-2共享前3块,在第四块分叉
- 淘汰候选序列(0和3)时自动释放其逻辑块
- 智能内存管理:
- 引用计数归零的物理块即时释放;
- 为新候选序列动态分配物理块(块9-12)
共享前缀
在LLM应用中,用户通常需要提供包含instructions和example inputs/outputs的系统提示词(system prompt),这些内容会与实际任务input拼接,形成完整prompt。此类共享prefix可通过提示词工程进一步微调,以提升下游任务的准确率。vLLM的实现方式如下:
- 预缓存机制:预先将共享prefix的KV缓存,存入专用物理块(类比OS对共享库的内存管理);
- 动态映射:含有共享prefix的用户请求,可直接将逻辑块映射到已缓存的物理块(末位块标记为copy-on-write);
- 计算优化:prompt phase仅需执行用户独有输入的计算(消除对共享prefix的冗余计算)
调度与抢占机制
当请求流量超过系统容量时,vLLM优先处理部分请求。vLLM采用先来先服务(FCFS)算法,以确保公平性并避免请求饥饿。
LLM服务面临的挑战有:输入prompts的长度差异显著;输出长度无法预知(由输入和模型行为决定)。随着请求数量和输出数量增加,VLLM可能会耗尽GPU的物理块,以致无法存储新生成的KV Cache。对此有两个亟需解决的问题:
块驱逐策略:通常使用启发式算法,预测最晚访问的物理块
- 全有或全无(All-or-Nothing)原则:同一序列的所有blocks,必须同时被驱逐或保留(由于一个序列的所有blocks同时被访问);
- 组调度(Gang-Scheduling):同一请求内的多序列(如束搜索中的候选序列)作为序列组统一调度(需要避免破坏序列间潜在的内存共享关系)
驱逐块恢复:
内存交换(Swapping):将被驱逐的KV块,暂存至CPU RAM。工作流程如下:
- 一旦GPU中没有空闲的物理块以分配给新token,选择待驱逐的序列组;
- 将该序列组的所有KV块,整体迁移至CPU RAM(在此期间,vLLM暂停接收新需求,直至所有被抢占的序列迁移完成);
- 一旦请求完成,从GPU内存释放其所有blocks,被抢占的序列从CPU中迁移回GPU,继续计算。
注意:CPU RAM永不超过GPU RAM中的物理块总数,因此:CPU RAM中交换空间大小严格受限于GPU显存容量。
重计算(Recomputation):当被抢占的序列被重新调度时,重新计算其KV Cache。
- 加速机制:将被抢占序列的已解码tokens,与原始用户prmpt,拼接形成新prompt;通过单次prompt阶段(prefill phase)并行,重构完整KV缓存。
分布式执行
许多LLMs的参数量超过了单个GPU的容量。因此,需要将参数分区并分布到多个GPU上,并采用模型并行策略处理。vLLM通过以下机制实现分布式部署:
模型并行架构:Megatron-LM风格的张量并行策略
基于SPMD的执行模式:
- 线性层:块状矩阵乘法分区计算
- 注意力层:按注意力头维度切分(每个SPMD进程处理一部分注意力头)
- 同步机制:通过all-reduce操作同步中间结果
全局KV缓存管理:(每个GPU处理相同的输入tokens)
- 采用集中式调度器统一管理:维护逻辑块到物理块的全局映射(所有GPU共享);为每个请求,分配物理块ID
- 分布式存储:相同物理块ID在不同GPU存储不同内容(对应各自分片的注意力头KV Cache);各GPU仅保留自身注意力头对应的KV Cache分片
工作流程
- 调度器预处理阶段:
- 对于batch中的每个请求,生成包含输入tokens的ID的集合,和逻辑-物理块映射表(Block Table);
- 将控制信息(token IDs+Block Table)广播至所有GPU workers;
- GPU workers并行计算阶段:
- 注意力层:根据控制信息中的块表,读取对应的KV Cache;各worker独立处理分配的注意力头子集;
- 全局同步:通过all-reduce原语自动同步中间结果(无需调度器介入)
- 回收迭代结果:GPU workers将采样生成的tokens回传至调度器。
vLLM仅需在每个解码迭代开始时,一次性同步由调度器下发的控制信息包含的内存状态;执行期间无需额外同步内存状态。
Implementation
vLLM作为端到端的LLM服务系统,采用分层架构设计:
- 前端接口层:基于FastAPI构建RESTful服务,完整支持OpenAI API协议;其可定制的参数包括:最大序列长度,束搜索宽度\(k\),温度系数等采样参数;
- 核心引擎层:控制平台(8.5K Python代码)包括分布式调度器和块管理器;数据平台(2K C++/CUDA代码)包括PagedAttention定制内核和高并发内存操作原语。集成PyTorch与HuggingFace Transformers等,原生适配:GPT系列,OPT和LLaMA等主流架构。
- 分布式通信层:基于NCCL实现跨GPU张量高效同步,和全兼容Megatron-LM的并行模式。
内核级优化
针对PagedAttention的特有内存访问模式,vLLM开发了三大定制化GPU内核:
- 融合式KV缓存写入:在每个Transformer层,KV Cache被划分为若干个blocks,重构为一个为读取blocks而优化的内存布局,再按块表写入。
- 传统方案需多次内核启动完成;而当前将三级操作融合为单一内核。
- 块感知注意力计算:基于FasterTransformer内核改造,使得每个GPU warp专门负责读取单个KV块,支持动态批处理(变长序列混合计算)。
- 该方法强制合并内存访问,实现块内计算零拷贝。
- 批量块拷贝:传统的
cudaMemcpyAsync导致碎片化小拷贝;因此该方法实现非连续块拷贝操作批量提交,采用写时复制。
解码算法支持框架
vLLM通过三大原子操作实现多样化解码算法:
| 操作 | 功能描述 | 典型应用场景 |
|---|---|---|
| fork | 从现有序列克隆新序列 | 并行采样/束搜索候选分支 |
| append | 追加新tokens到指定序列 | 自回归生成迭代step |
| free | 释放序列及其KV Cache | 终止条件触发/低概率路径修剪 |
源码
vLLM整体架构如下,支持离线批处理(同步)和在线API服务(异步)。 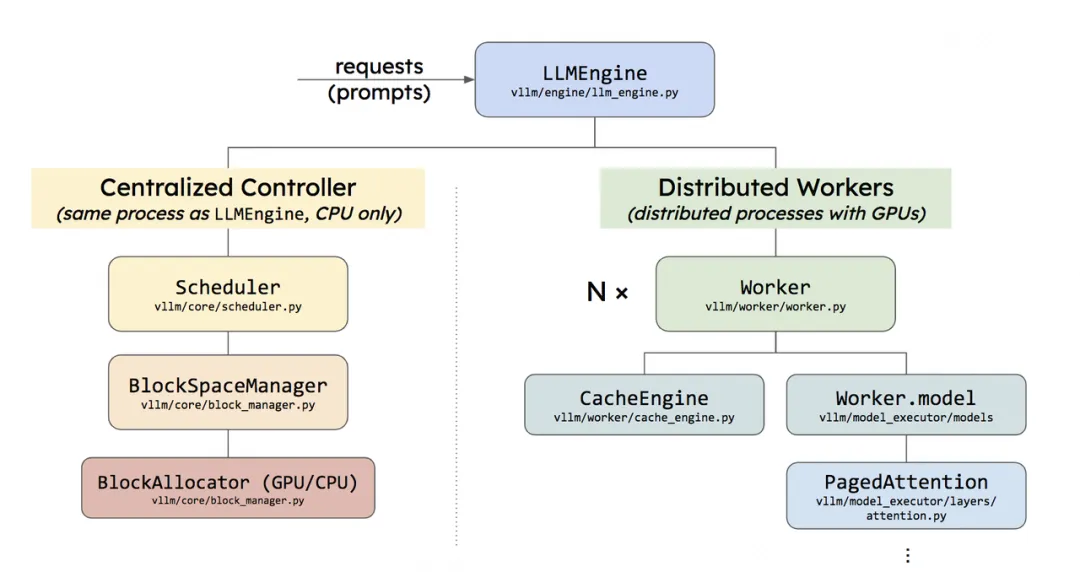
调用方式
离线批推理(Offline Batched Inference)
从一个最基础的离线推理脚本开始:
1 | # Sample prompts. |
llm = LLM(model="facebook/opt-125m")实例化一个LLM对象,其本质是实例化一个LLMEngine对象,通过EngineArgs加载配置。在离线批推理中,每次给模型发送推理请求时,需要整个batch的数据一起发送、推理、返回推理结果,称为(batch内部)同步。
在线API服务(API Server For Online Serving)
1 | curl http://localhost:8000/v1/completions \ |
异步请求推理:核心处理逻辑封装在AsyncLLMEngine类中(继承自LLMEngine)。
从LLM开始
- 通过
EngineArgs加载配置:1
engine_args = EngineArgs(...)
- 创建
LLMEngine引擎:1
2
3
4
5
6
7
8# 1. 使用配置好的engine参数,初始化LLMEngine实例
self.llm_engine = LLMEngine.from_engine_args(
engine_args=engine_args, usage_context=UsageContext.LLM_CLASS)
self.engine_class = type(self.llm_engine)
'''2. 用于全局唯一的request_id:
在vLLM中内核引擎的处理中,1个prompt视为1个request,分配全局唯一的request_id'''
self.request_counter = Counter()
self.default_sampling_params: Union[dict[str, Any], None] = None
进入
from_engine_args函数,看看引擎的创建过程:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
def from_engine_args(
cls,
engine_args: EngineArgs,
usage_context: UsageContext = UsageContext.ENGINE_CONTEXT,
stat_loggers: Optional[Dict[str, StatLoggerBase]] = None,
) -> "LLMEngine":
# 1. 生成引擎配置对象`vllm_config`
vllm_config = engine_args.create_engine_config(usage_context)
engine_cls = cls
if envs.VLLM_USE_V1:
from vllm.v1.engine.llm_engine import LLMEngine as V1LLMEngine
engine_cls = V1LLMEngine
# 2. 创建引擎实例
return engine_cls.from_vllm_config(
vllm_config=vllm_config,
usage_context=usage_context,
stat_loggers=stat_loggers,
disable_log_stats=engine_args.disable_log_stats,
)
- 引擎配置实例的生成函数:create_engine_config:将EngineArgs分解成ModelConfig,CacheConfig, ParallelConfig和SchedulerConfig,返回一个
VllmConfig实例;- 引擎实例的创建函数:from_vllm_config:(工厂方法)使用传入的
VllmConfig配置对象,创建并返回一个新的LLMEngine实例。
采用推理引擎LLMEngine,整体架构如下: 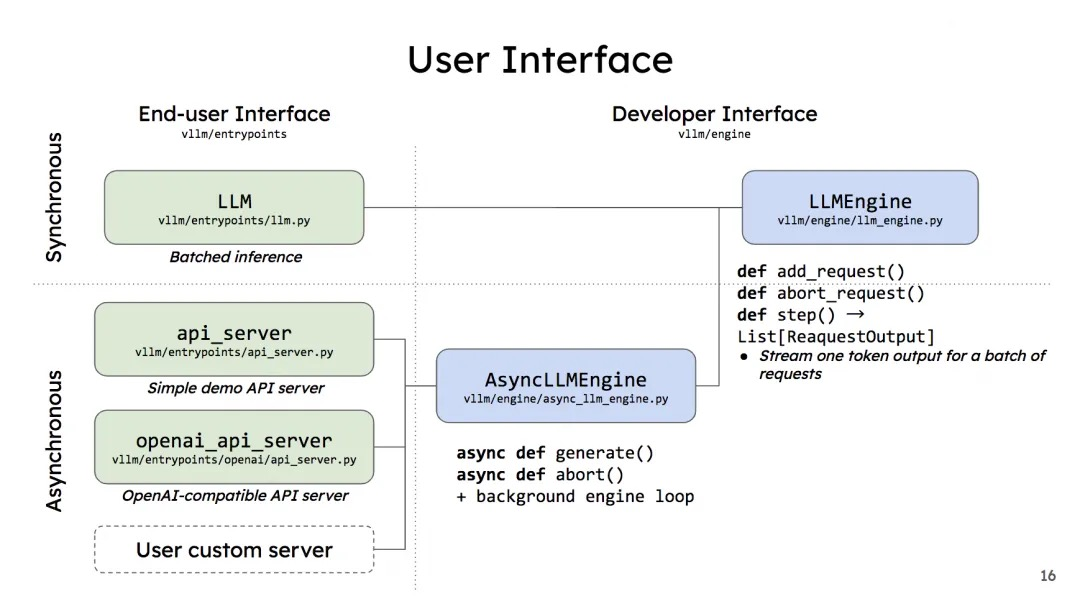
每个推理包含两个阶段:
- 调度预处理阶段:
Scheduler决定可参与推理的请求,为每个请求创建:包含输入tokens的ID的集合,和逻辑-物理块映射表; - Worker并行计算阶段:将请求的控制信息,分发到各个worker上推理。
Worker中的CacheEngine管理KV Cache;Worker中的model加载模型并开展推理。
模型执行器Executor
首先,模型执行器的类型是如何指定的呢?:
_get_executor_cls函数在创建引擎实例的函数
from_vllm_config中,有:executor_class=cls._get_executor_cls(vllm_config),来到
_get_executor_cls函数:根据VllmConfig配置中的distributed_executor_backend配置,动态选择并返回合适的执行器类:均为ExecutorBase的子类。有哪些执行器类型可供选择呢?
ExecutorBase为执行器基类;DistributedExecutorBase继承ExecutorBase,为分布式执行器的基类。UniProcExecutor(继承ExecutorBase):在单个节点上启动单个进程(支持单个节点上的多个GPU);ExecutorWithExternalLauncher(继承UniProcExecutor):专门与torchrun-compatible的启动器配合使用:通过
torchrun启动多个引擎,每个引擎对应一个工作进程(worker),每个进程负责一个或多个设备(GPU);所有进程在处理相同的输入时会生成相同的输出,无需进行状态同步;
不支持流水线并行,执行张量并行。
RayDistributedExecutor(继承DistributedExecutorBase):使用Ray集群进行分布式训练- 进程数:启动多个 Ray worker,每个 worker 是一个独立的进程,负责执行推理任务;(进程的数量由
world_size决定) - 设备数:每个 worker 指定使用的 GPU 数量(通过
num_gpus配置) - 节点数:执行器支持在多个节点上运行多个 worker;节点的分配通过 Ray placement group 管理
- 进程数:启动多个 Ray worker,每个 worker 是一个独立的进程,负责执行推理任务;(进程的数量由
MultiprocessingDistributedExecutor(继承DistributedExecutorBase):基于 Python 多进程:- 支持在单节点(即只有一个物理机器)上运行;通过
world_size指定创建的工作进程数;每个进程的任务由tensor_parallel_size分配。通过回环地址进行进程间通信。
- 支持在单节点(即只有一个物理机器)上运行;通过
执行器是何时创建的呢?
由
LLMEngine的初始化函数中以下语句创建:self.model_executor = executor_class(vllm_config=vllm_config, );执行器的初始化流程是怎样的呢?:
self._init_executor()
执行器初始化:_init_executor函数
UniProcExecutor的初始化
1 | def _init_executor(self) -> None: |
工作进程包装器(
WorkerWrapperBase):代表一个执行器中的一个进程,延迟初始化worker实例(真正的worker实例在init_worker中创建),控制worker的生命周期。
ExecutorWithExternalLauncher的初始化
1 | def _init_executor(self) -> None: |
RayDistributedExecutor初始化
- 提供两种优化路径:编译DAG+SPMD / 传统RPC
- 硬件适配:自动检测TPU(切换通信方式:NCCL转为shm共享内存)
1 | def _init_executor(self)->None: |
初始化Ray集群(
initialize_ray_cluster):负责连接或创建Ray集群,并设置资源分配策略;初始化工作进程(workers)(
_init_workers_ray):创建、配置和管理分布式LLM推理所需的所有工作节点。
- 在Ray集群中,创建并配置多个工作进程:使用Ray的Placement Group确保GPU资源正确分配;每个worker绑定到特定的资源bundle
- 分布式通信:单节点使用127.0.0.1优化通信;多节点使用实际IP地址
- 支持并行模式:流水线并行和张量并行
工作进程Worker
推理引擎LLMEngine
LLMEngine是主要的执行引擎,用于处理从客户端接收的请求,执行文本生成任务,并返回生成的结果。该类包括一个tokenizer、一个Language model(可能分布在多个 GPU 上),以及分配给中间状态(即 KV Cache)的 GPU 内存空间。
LLMEngine初始化
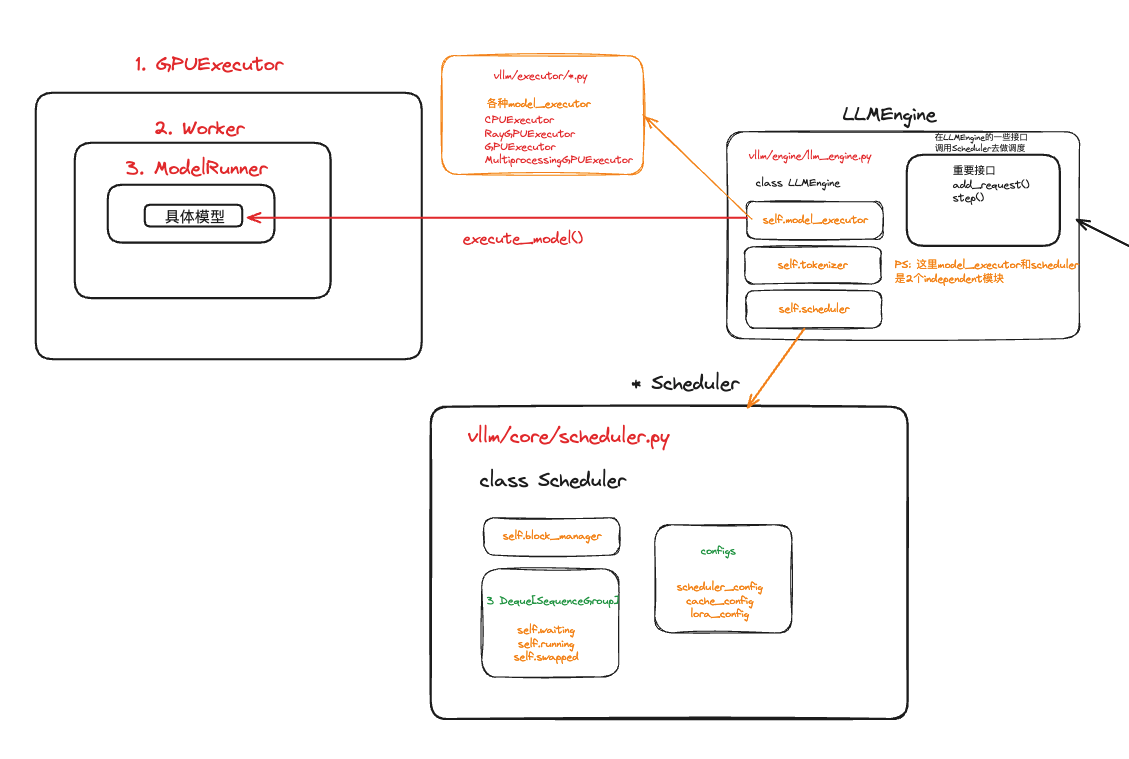
初始化
tokenizer(可选):根据配置中的skip_tokenizer_init参数决定是否初始化tokenizer(分词器);序列计数器:
self.seq_counter = Counter(),追踪生成的序列数量;输入预处理器:
self.input_preprocessor = InputPreprocessor(self.model_config,self.tokenizer,mm_registry),将处理输入数据并将其转换为模型能够理解的格式;模型执行器:
self.model_executor = executor_class(vllm_config=vllm_config, );创建继承
ExecutorBase基类的实例:初始化函数中包括self._init_executor()KV Cache初始化:
self._initialize_kv_caches();(如果模型的运行类型不是pooling),用于存储推理过程中间结果,减少重复计算;使用统计信息
创建调度器:
1
2
3
4
5
6
7
8self.scheduler = [
Scheduler(
self.scheduler_config, self.cache_config, self.lora_config,
self.parallel_config.pipeline_parallel_size,
self.async_callbacks[v_id]
if self.model_config.use_async_output_proc else None)
for v_id in range(self.parallel_config.pipeline_parallel_size)
]统计日志记录器:支持输出到 Prometheus 或本地日志;
初始化输出处理器:创建输出处理器,用于处理生成的序列,支持序列生成技术(如 Beam Search 或推测解码);
其他初始化:初始化
self.seq_id_to_seq_group: Dict[str, SequenceGroupBase] = {}字典,跟踪序列的组信息。
初始化KV Cache:_initialize_kv_caches
- 决定在GPU Cache和CPU Cache中的block数量。总流程如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def _initialize_kv_caches(self) -> None:
start = time.time()
# 1. 调用模型执行器:确定可用的 GPU 和 CPU 缓存块数
num_gpu_blocks, num_cpu_blocks = (
self.model_executor.determine_num_available_blocks())
# 2. 若存在缓存块数的覆盖配置,则使用该覆盖值
if self.cache_config.num_gpu_blocks_override is not None:
num_gpu_blocks_override = self.cache_config.num_gpu_blocks_override
logger.info(
"Overriding num_gpu_blocks=%d with "
"num_gpu_blocks_override=%d", num_gpu_blocks,
num_gpu_blocks_override)
num_gpu_blocks = num_gpu_blocks_override
# 3. 更新缓存配置:将GPU 和 CPU 块数,保存到cache_config配置对象中
self.cache_config.num_gpu_blocks = num_gpu_blocks
self.cache_config.num_cpu_blocks = num_cpu_blocks
# 4. 初始化模型的缓存
self.model_executor.initialize_cache(num_gpu_blocks, num_cpu_blocks)
elapsed = time.time() - start
logger.info(("init engine (profile, create kv cache, "
"warmup model) took %.2f seconds"), elapsed)
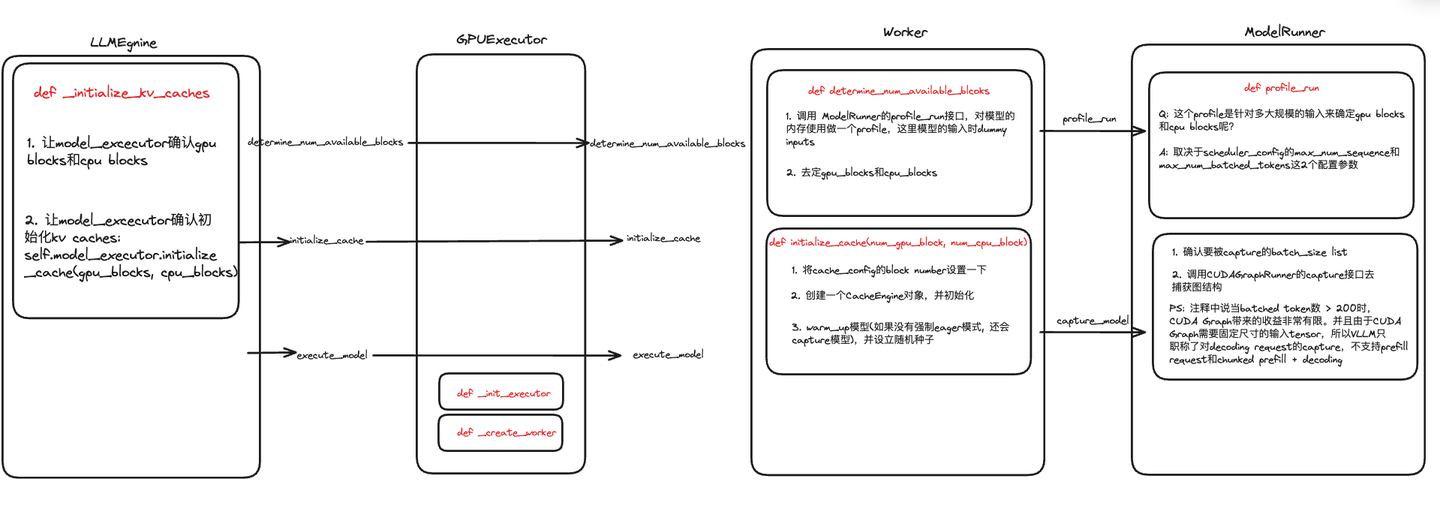
调用两个模型执行器的函数:
ExecutorBase类的方法(所有executor的基类)
determine_num_available_blocks:
2
3
4
results = self.collective_rpc("determine_num_available_blocks")
a = min([r[0] for r in results])
b = min([r[1] for r in results])
initialize_cache:通过底层的 worker初始化 KV 缓存
- 计算最大并发量:推理过程中同时处理请求的最大数量。
2
3
max_concurrency = (num_gpu_blocks * self.cache_config.block_size /
self.model_config.max_model_len)- 调用
collective_rpc("initialize_cache", args=(num_gpu_blocks, num_cpu_blocks))来通知各个 worker 初始化缓存
Worker前向推理:determine_num_available_blocks
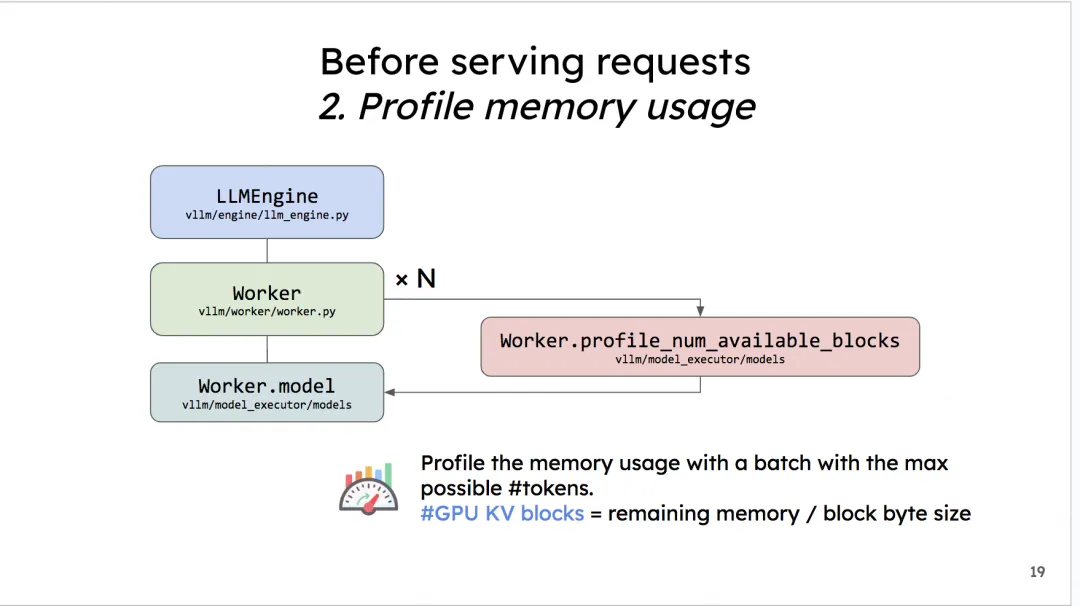 在模型部署的初始化阶段(推理正式开始前),vLLM通过模拟实验的方式,来决定gpu/cpu上到底有多少个KV cache物理块可分配给后续的请求做推理。这是如何完成的呢?
在模型部署的初始化阶段(推理正式开始前),vLLM通过模拟实验的方式,来决定gpu/cpu上到底有多少个KV cache物理块可分配给后续的请求做推理。这是如何完成的呢?
1 |
|
内存分析准备:
1
2
3
4torch.cuda.empty_cache() # 释放当前 CUDA 上的未使用内存
torch.cuda.reset_peak_memory_stats() # 重置 GPU 内存的峰值统计信息
# 返回:当前GPU空闲内存 和 总GPU内存
free_memory_pre_profile, total_gpu_memory = torch.cuda.mem_get_info()执行内存分析:调用
model_runner的profile_run方法,调用_dummy_run模拟一次前向推理1
2
3
4with memory_profiling(
self.baseline_snapshot,
weights_memory=self.model_runner.model_memory_usage) as result:
self.model_runner.profile_run()profile_run方法:调用_dummy_runmax_num_seqs为在1个推理阶段中,LLMEngine最多能处理的seq数量;max_num_batched_tokens为1个推理阶段中,LLMEngine最多能处理的token数量。1
2
3
4
5
6
def profile_run(self) -> None:
max_num_batched_tokens = \
self.scheduler_config.max_num_batched_tokens
max_num_seqs = self.scheduler_config.max_num_seqs
self._dummy_run(max_num_batched_tokens, max_num_seqs)
模拟一次前向推理:调用
model_runner的_dummy_run,通过生成虚拟数据和配置来模拟一次模型的推理过程,帮助评估内存使用情况;并不涉及实际的训练过程。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102def _dummy_run(self,
max_num_batched_tokens: int,
max_num_seqs: int = 1) -> None:
with self.set_in_profile_run():
# 1. 设置配置和采样参数: top-k采样
sampling_params = \
SamplingParams(top_p=0.99, top_k=self.vocab_size - 1)
# 2. 构造LoRA请求:
dummy_lora_requests: List[LoRARequest] = []
dummy_lora_requests_per_seq: List[LoRARequest] = []
if self.lora_config:
# 调用 self._add_dummy_loras() 方法生成一组虚拟的 LoRA 请求(请求数为max_loras)
dummy_lora_requests = self._add_dummy_loras(
self.lora_config.max_loras)
assert len(dummy_lora_requests) == self.lora_config.max_loras
# 每个序列都得到一个相应的 LoRA 请求
dummy_lora_requests_per_seq = [
dummy_lora_requests[idx % len(dummy_lora_requests)]
for idx in range(max_num_seqs)
]
# 3. 处理多模态数据(可能消耗更多GPU内存):将batch_size设置为图片的最大数量
max_mm_tokens = self.mm_registry.get_max_multimodal_tokens(
self.model_config) # max_mm_tokens :多模态数据中可用的最大 token 数量
if max_mm_tokens > 0: # 调整最大序列数max_num_seqs
max_num_seqs_orig = max_num_seqs
max_num_seqs = min(max_num_seqs,
max_num_batched_tokens // max_mm_tokens)
if max_num_seqs < 1:
expr = (f"min({max_num_seqs_orig}, "
f"{max_num_batched_tokens} // {max_mm_tokens})")
logger.warning(
"Computed max_num_seqs (%s) to be less than 1. "
"Setting it to the minimum value of 1.", expr)
max_num_seqs = 1
# 4. 循环为每个序列,生成虚拟输入数据:
seqs: List[SequenceGroupMetadata] = []
batch_size = 0
for group_id in range(max_num_seqs):
# seq_len 计算当前序列的长度,确保每个序列的长度总和等于 max_num_batched_tokens
seq_len = (max_num_batched_tokens // max_num_seqs +
(group_id < max_num_batched_tokens % max_num_seqs))
batch_size += seq_len
# 调用dummy_data_for_profiling:生成用于分析的虚拟数据
dummy_data = self.input_registry \
.dummy_data_for_profiling(self.model_config,
seq_len,
self.mm_registry)
# 为每个序列创建一个 SequenceGroupMetadata 对象
seq = SequenceGroupMetadata(
request_id=str(group_id),
is_prompt=True,
seq_data={group_id: dummy_data.seq_data},
sampling_params=sampling_params,
block_tables=None,
lora_request=dummy_lora_requests_per_seq[group_id]
if dummy_lora_requests_per_seq else None,
multi_modal_data=dummy_data.multi_modal_data,
multi_modal_placeholders=dummy_data.
multi_modal_placeholders,
)
seqs.append(seq)
# 5. 创建并执行模型推理
# Run the model with the dummy inputs.
num_layers = self.model_config.get_num_layers(self.parallel_config)
kv_caches = [ # 为每个层创建一个空的张量缓存(float32)
'''
1. 使用空tensor而非None:确保框架(如 PyTorch 的 Dynamo)在处理这些参数时,将它们作为引用传递,而不是根据参数的值(如 None)进行特殊化;
2. 在循环中每次创建新的张量,而不是通过列表复制,避免张量别名问题。
'''
torch.tensor([], dtype=torch.float32, device=self.device)
for _ in range(num_layers)
]
finished_requests_ids = [seq.request_id for seq in seqs]
model_input = self.prepare_model_input( # 准备模型的输入数据
seqs, finished_requests_ids=finished_requests_ids)
intermediate_tensors = None
if not get_pp_group().is_first_rank:
intermediate_tensors = \
self.model.make_empty_intermediate_tensors(
batch_size=batch_size,
dtype=self.model_config.dtype,
device=self.device)
# 虚拟模型推理中,禁用键值比例计算
if model_input.attn_metadata is not None:
model_input.attn_metadata.enable_kv_scales_calculation = False
# 执行模型推理
self.execute_model(model_input, kv_caches, intermediate_tensors)
torch.cuda.synchronize()
# 6. 清理之前添加的虚拟 LoRA 请求
if self.lora_config:
self._remove_dummy_loras()
return(回到
Worker)可分配的KV cache物理块总数:
分配给KV cache显存 = gpu总显存 -(不使用KV cache情况下)做1次FWD时的显存占用
对于“不使用KV cache做1次FWD时的显存占用”,使用上一步中模拟的一次FWD计算得出。
1
2memory_for_current_instance = total_gpu_memory * self.cache_config.gpu_memory_utilization
available_kv_cache_memory = (memory_for_current_instance - result.non_kv_cache_memory)总物理块数量 = 分配给KV Cache的显存大小/ 物理块大小,其中“大小”的单位是bytes。
1
2
3
4
5
6
7
8
9cache_block_size = self.get_cache_block_size_bytes()
if cache_block_size == 0:
num_gpu_blocks = 0
num_cpu_blocks = 0
else:
num_gpu_blocks = int(available_kv_cache_memory // cache_block_size)
num_cpu_blocks = int(self.cache_config.swap_space_bytes // cache_block_size)
num_gpu_blocks = max(num_gpu_blocks, 0)
num_cpu_blocks = max(num_cpu_blocks, 0)
这里抛出一个问题:GPU上物理块大小
cache_block_size如何计算呢?调用
CacheEngine的get_cache_block_size_bytes方法:总结:由大模型中KV值的定义,易知:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def get_cache_block_size(
cache_config: CacheConfig,
model_config: ModelConfig,
parallel_config: ParallelConfig,
) -> int:
# head_size:每个 Attention 头部 的大小(即每个头部的维度)
head_size = model_config.get_head_size()
# num_heads:KV Cache中使用的 Attention 头的数量
num_heads = model_config.get_num_kv_heads(parallel_config)
# num_attention_layers:Attention 层 的数量
num_attention_layers = model_config.get_num_layers_by_block_type(
parallel_config, LayerBlockType.attention)
# dtype:数据类型
if cache_config.cache_dtype == "auto":
dtype = model_config.dtype
else:
dtype = STR_DTYPE_TO_TORCH_DTYPE[cache_config.cache_dtype]
# 每个Key Cache条目的大小:num_heads(头数)* head_size(每个头的大小)
key_cache_entry = num_heads * head_size
# 每个Value Cache条目的大小:如果 模型使用 MLA,则没有Value Cache;如果 模型没有使用 MLA,则 value_cache_entry 等于 key_cache_entry
value_cache_entry = key_cache_entry if not model_config.use_mla else 0
# 每个 KV Cache所需的总内存大小:
total = num_attention_layers * cache_config.block_size * \
(key_cache_entry + value_cache_entry)
dtype_size = get_dtype_size(dtype)
# 缓存块的总大小
return dtype_size * totalK_cache_block_size = block_size * num_heads * head_size * num_layers * dtype_size。其中dtype_size表示精度对应的大小,例如fp16是2,fp32是4;同理可知:
V_cache_block_size = K_cache_block_size最终一个物理块的大小为:
cache_block_size = block_size * num_heads * head_size * num_layers * dtype_size * 2CPU上物理块总数也是同理,但与GPU不同的是,它无需模拟前向推理。CPU上可用的内存总数由用户通过参数传入(默认4G)。
Worker初始化 KV Cache:initialize_cache
在确定KV Cache Block的大小后,创建empty tensor,将其先放置到gpu上,实现显存的预分配。这是如何完成的呢?核心函数:_allocate_kv_cache
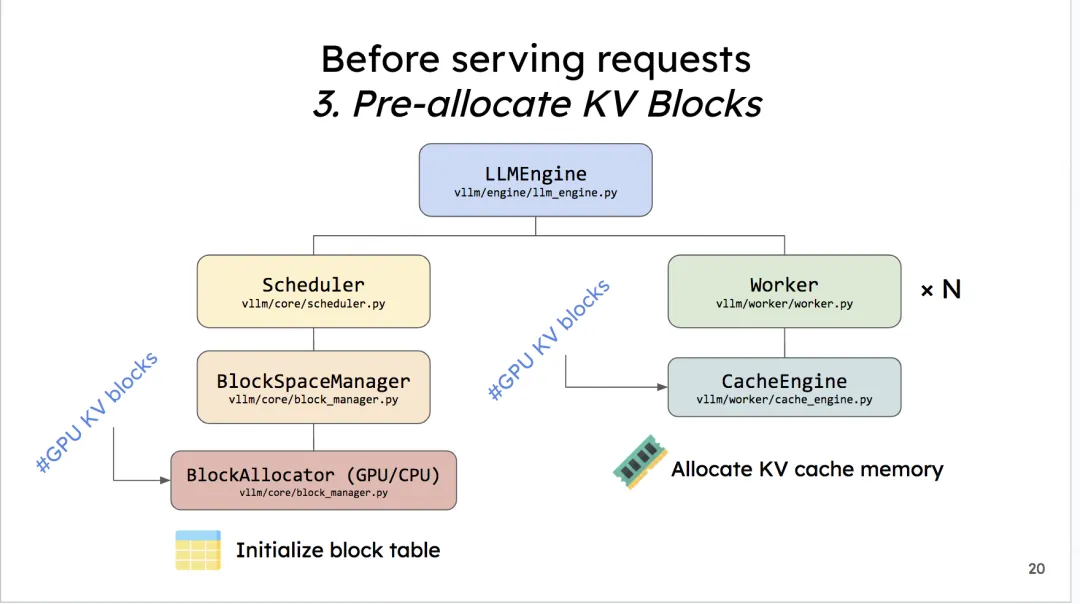
回到LLMEngine初始化函数中,调用_initialize_kv_caches后,进入:self.model_executor.initialize_cache(num_gpu_blocks, num_cpu_blocks),来看看模型执行器的initialize_cache函数:
1 | def initialize_cache(self, num_gpu_blocks: int, |
包括两个关键步骤:
_init_cache_engine():创建一个CacheEngine对象,并初始化:1
2
3
4# CacheEngine的初始化函数中,包括:
self.gpu_cache = self._allocate_kv_cache(
self.num_gpu_blocks, self.device_config.device_type)
self.cpu_cache = self._allocate_kv_cache(self.num_cpu_blocks, "cpu")
_allocate_kv_cache预分配KV Cache内存:为每个注意力层创建全零初始化的张量
大小为:(2, num_blocks, block_size, num_kv_heads, head_size)
1 | def _allocate_kv_cache( |
模型预热
_warm_up_model:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16def _warm_up_model(self) -> None:
# 1. 确定预热尺寸:在非eager模式下,过滤掉已被CUDA图捕获的尺寸,避免重复工作
warmup_sizes = self.vllm_config.compilation_config.compile_sizes.copy()
if not self.model_config.enforce_eager:
warmup_sizes = [
x for x in warmup_sizes if x not in
self.vllm_config.compilation_config.cudagraph_capture_sizes
]
# 2. 按尺寸降序预热:通过_dummy_run执行虚拟推理,触发内核编译和缓存预热
for size in sorted(warmup_sizes, reverse=True):
logger.info("Compile and warming up model for size %d", size)
self.model_runner._dummy_run(size)
# 3. CUDA图捕获:capture_model
if not self.model_config.enforce_eager:
self.model_runner.capture_model(self.gpu_cache)
set_random_seed(self.model_config.seed)调用
capture_model方法,通过CUDA图捕获模型的计算图:- 主要支持小批量decoding场景(<=200 tokens):当批处理的token数量超过200时,CUDA图带来的性能提升不明显;
- 需要固定大小的tensor,不支持变长批处理
- 使用场景:仅支持decoding request的捕获(每个序列单个token):不支持prefill request和chunked prefill+decoding
推理
序列组SequenceGroup
原生输入
SequenceGroup的作用
1个SequenceGroup实例包括:"1个prompt -> 多个outputs"
一个seq_group中的所有seq共享1个prompt
其中每组"prompt -> output"组成一个序列(seq,属于Sequence实例),每个seq下有若干状态(status)属性(
class SequenceStatus(enum.IntEnum)),包括:WAITING:正在waiting队列中(waiting队列中的序列都没有做过prefill);RUNNING:正在running队列中(即已经开始做推理);SWAPPED:正在swapped队列中,表示:此时gpu资源不足,相关的seq_group被抢占,导致其暂停推理,相关的KV block被置换到cpu上(swap out);等待gpu资源充足时再置换回来重新计算(swap in);FINISHED_STOPPED:正常执行完毕(例如:碰到符号,该seq的推理正常结束);FINISHED_LENGTH_CAPPED:因为seq的长度达到最大长度限制,而结束推理;FINISHED_ABORTED:因不正常状态,而被终止的推理。例如客户端断开连接,则服务器会终止相关seq的推理;FINISHED_IGNORED:因prompt过长而被终止执行的推理(本质上也是受到长度限制)
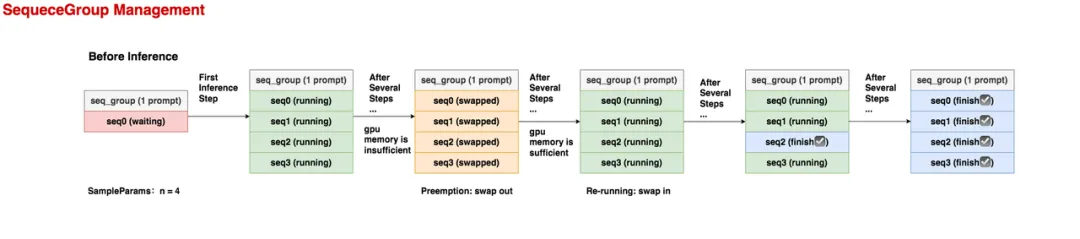
推理过程如下:
推理开始之前:seq_group下只有1条seq,它就是prompt,状态为waiting;
在第1个推理阶段:调度器选中了这个seq_group,由于它的采样参数中n = 4,所以在做完prefill之后,它会生成4个seq,它们的状态都是running;
在若干个推理阶段后,gpu上的资源不够了,这个seq_group不幸被调度器抢占:它相关的KV block也被swap out到cpu上。此时所有seq的状态变为swapped。注意:当一个seq_group被抢占时,对它的处理有两种方式:
Swap:如果该seq_group下的seq数量 > 1,此时会采取swap策略,即把seq_group下所有seq的KV block从gpu上卸载到cpu上。(seq数量比较多,直接抛弃已计算的KV block,不划算)Recomputation:如果该seq_group下的seq数量 = 1,此时采取recomputation策略,即释放该seq_group相关的物理块,将其重新放回waiting队列中。等下次它被选中推理时,从prefill阶段开始重新推理。(seq数量少,重新计算KV block的成本不高)
又过了若干个推理阶段,gpu上的资源又充足了,此时执行swap in操作,将卸载到cpu上的KV block重新读到gpu上,继续对该seq_group做推理,此时seq的状态又变为running;
又过了若干个推理阶段,该seq_group中有1个seq已经推理完成了,其状态被标记为finish,此后这条已经完成的seq将不参与调度;
又过了若干个推理阶段,这个seq_group下所有的seq都已经完成推理了,此时可作为最终output返回。
SequenceGroup结构
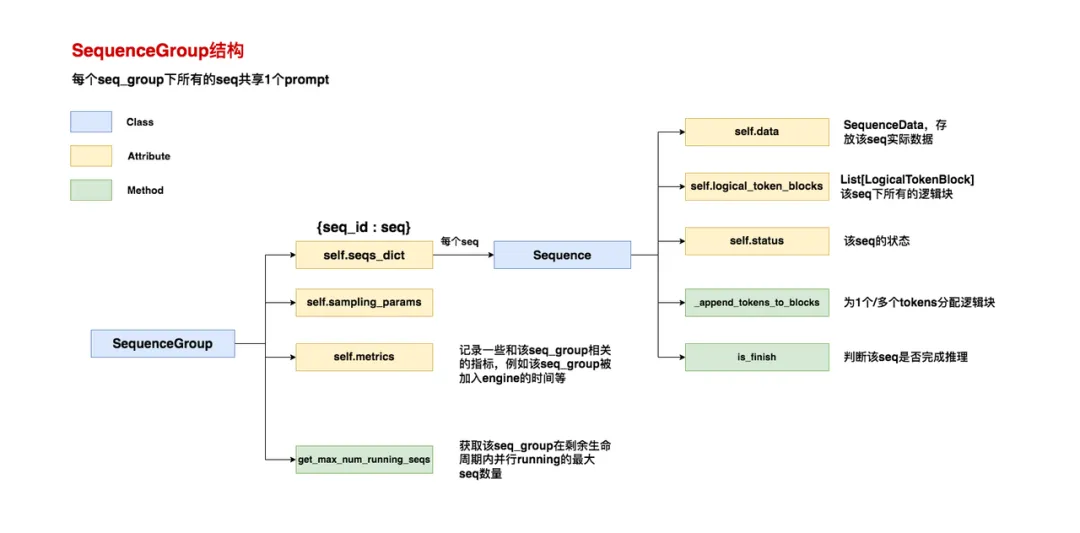
self.seqs_dict = {seq.seq_id: seq for seq in seqs}:一个seq_group下包含若干seqs,其中每个seq是一个Sequence对象;self.metrics:记录该seq_group相关的指标1
2
3
4
5
6self.metrics = RequestMetrics(arrival_time=arrival_time,
last_token_time=arrival_time,
first_scheduled_time=None,
first_token_time=None,
time_in_queue=None,
spec_token_acceptance_counts=[0] * draft_size)get_max_num_running_steps:该seq_group在剩余生命周期内,并行running的最大seq数量。“剩余生命周期”指从此刻一直到seq_group中所有的seq都做完推理。> 1.1
2
3
4def get_max_num_running_seqs(self) -> int:
if self.is_single_seq:
return 0 if self.first_seq.is_finished() else 1
return self.num_seqs() - self.num_finished_seqs()num_seqs()函数:获取符合指定status状态的所有序列,并返回其长度; > 2.get_finished_seqs():返回已经完成的序列的数量(包括:FINISHED_STOPPED,FINISHED_LENGTH_CAPPED,FINISHED_ABORTED,FINISHED_IGNORED共四种状态)
离线批推理中,脚本包括以下两个关键步骤:
llm = LLM(model="facebook/opt-125m"):实例化一个离线批处理的vLLM对象:LLMEngine执行一次模拟实验(profiling),来判断需要在gpu上预留多少的显存空间给KV Cache block;outputs = llm.generate(prompts, sampling_params):推理入口
入口函数:generate
1 | def generate( |
_validate_and_add_requests函数内:逐个添加请求到引擎;支持优先级调度(默认优先级为0)
2
3
4
5
6
7
8
9
self._add_request(
prompt,
params[i] if isinstance(params, Sequence) else params,
lora_request=lora_request[i] if isinstance(
lora_request, Sequence) else lora_request,
prompt_adapter_request=prompt_adapter_request,
priority=priority[i] if priority else 0,
)
_add_request函数:
2
3
4
5
6
7
8
9
10
11
self,
prompt: PromptType,
params: Union[SamplingParams, PoolingParams],
lora_request: Optional[LoRARequest] = None,
prompt_adapter_request: Optional[PromptAdapterRequest] = None,
priority: int = 0,
) -> None:
request_id = str(next(self.request_counter)) # 使用计数器 request_counter 生成唯一ID
self.llm_engine.add_request(
request_id, prompt, params, lora_request=lora_request, prompt_adapter_request=prompt_adapter_request, priority=priority,)调用案例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
self._add_request(
prompt={"text": "描述这张图片", "image": image_tensor},
params=SamplingParams(top_p=0.9),
prompt_adapter_request=ClipAdapterRequest()
)
# 高优先级实时对话
self._add_request(
prompt="生成下周会议摘要",params=SamplingParams(temperature=0.3),priority=100
)
# 低延迟场景
self._add_request(
prompt=[token1, token2, token3], # 预分词
params=PoolingParams(stride=128), # 池化模式
priority=0
)
当一条请求到来时,流程如下: 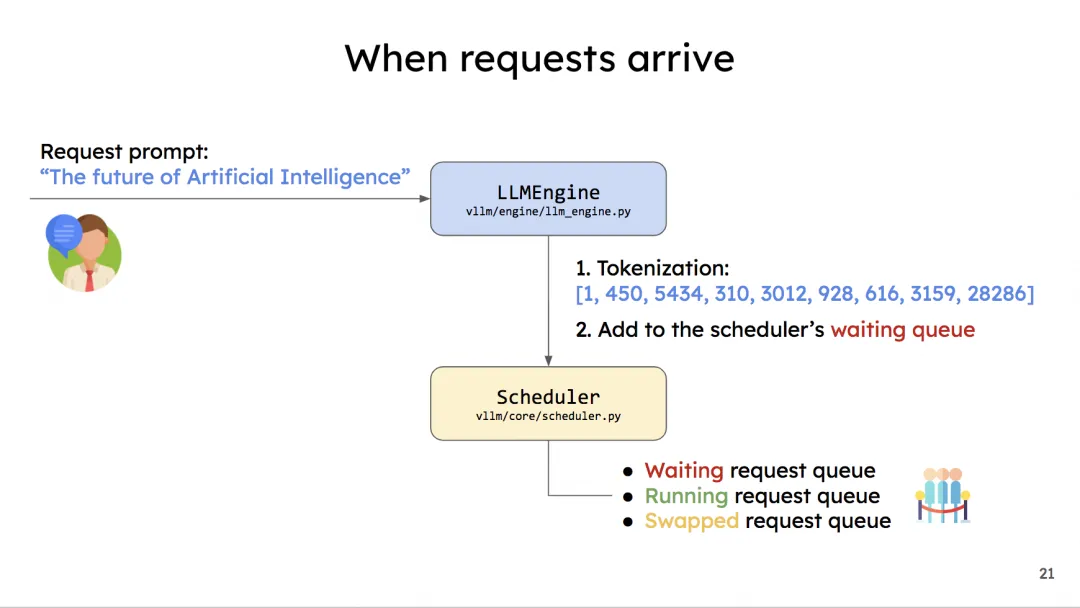
generate函数实际上做了两件事情:
_add_request:将输入数据传给LLMEngine:- 把每1个prompt包装成一个SequenceGroup对象:从客户端角度看,1个请求可能包含多个prompts,例如离线批处理场景下,可以将1个batch理解成1个请求;但是从LLMEngine的角度看,1个prompt是1个请求,所以它会对输入数据进行预处理;
- 把包装成SequenceGroup对象的数据加入调度器(Scheduler)的waiting队列,等待处理。
_run_engine:执行推理。只要调度器的waiting/running/swapped队列非空,就认为此时这批batch还没有做完推理,这时会调用LLMEngine的step()函数,来完成1次调度以决定要送哪些数据去做推理。
add_request:接收用户请求
- 功能:将请求添加到引擎的请求池中,并在调度器的
engine.step()被调用时,处理这些请求。
先做输入有效性检查(prompt和params不为None;lora_request请求出现时,配置中是否启用LoRA;是否支持优先级调度;是否启用引导解码等);设置请求到达时间(若无,则使用当前时间);进行分词器验证;使用input_preprocessor对传入的 prompt、lora_request 和 prompt_adapter_request 进行预处理,转为适合模型处理的格式。
最后,将请求添加到请求池:self._add_processed_request(...)
_add_processed_request:请求添加至请求池
- 功能:处理请求,生成相应的序列;根据当前调度器的负载情况(未完成的序列数量),选择最适合的调度器,将序列组添加到调度队列中。
处理多采样请求:如果采样请求需要多个序列(即
params.n > 1),将请求添加到ParallelSampleSequenceGroup中进行并行处理,方法直接返回None;1
2
3
4
5if isinstance(params, SamplingParams) and params.n > 1:
ParallelSampleSequenceGroup.add_request(
......
)
return None创建序列:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 1. 加载每个KV cache block的大小(默认为16);
block_size = self.cache_config.block_size
seq_id = next(self.seq_counter) # 当前seq的id
eos_token_id = self.input_preprocessor.get_eos_token_id(lora_request) # 结束符token ID
// 2. input拆分为:编码器、解码器输入
encoder_inputs, decoder_inputs = split_enc_dec_inputs(processed_inputs)
// 3. 创建序列:
seq = Sequence(seq_id, decoder_inputs, block_size, eos_token_id,
lora_request, prompt_adapter_request)
encoder_seq = (None if encoder_inputs is None else Sequence(
seq_id, encoder_inputs, block_size, eos_token_id, lora_request,
prompt_adapter_request))每个prompt被包装成一个
SequenceGroup实例:根据
params创建SequenceGroup:是SamplingParams,创建采样序列组;是PoolingParams,创建池化序列组。SamplingParams:调用_create_sequence_group_with_sampling函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35def _create_sequence_group_with_sampling(
self, request_id: str, seq: Sequence, sampling_params: SamplingParams, arrival_time: float, lora_request: Optional[LoRARequest], trace_headers: Optional[Mapping[str, str]] = None, prompt_adapter_request: Optional[PromptAdapterRequest] = None, encoder_seq: Optional[Sequence] = None, priority: int = 0,) -> SequenceGroup:
# 1. 验证Logprobs参数
max_logprobs = self.get_model_config().max_logprobs
if (sampling_params.logprobs
and sampling_params.logprobs > max_logprobs) or (
sampling_params.prompt_logprobs
and sampling_params.prompt_logprobs > max_logprobs):
raise ValueError(f"Cannot request more than {max_logprobs} logprobs.")
# 2. 构建Logits处理器:用于调整生成过程中的 logits 值
sampling_params = self._build_logits_processors(sampling_params, lora_request)
# 3. 复制采样参数:对 sampling_params 进行防御性复制(clone),确保在后续操作中不会修改原始的采样参数
sampling_params = sampling_params.clone()
# 4. 更新生成配置
sampling_params.update_from_generation_config(
self.generation_config_fields, seq.eos_token_id)
# 5. 创建序列组:
# 5.1 确定draft_size:如果配置中启用了推测性解码(speculative_config),则根据推测性解码的配置调整 draft_size
draft_size = 1
if self.vllm_config.speculative_config is not None:
draft_size = \
self.vllm_config.speculative_config.num_speculative_tokens + 1
# 5.2 创建 SequenceGroup 对象
seq_group = SequenceGroup(
request_id=request_id,
seqs=[seq],
arrival_time=arrival_time,
sampling_params=sampling_params,
lora_request=lora_request,
trace_headers=trace_headers,
prompt_adapter_request=prompt_adapter_request,
encoder_seq=encoder_seq,
priority=priority,
draft_size=draft_size)
return seq_group选择最空闲的调度器,添加序列组:
1
2
3
4
5
6costs = [
scheduler.get_num_unfinished_seq_groups()
for scheduler in self.scheduler
]
min_cost_scheduler = self.scheduler[costs.index(min(costs))]
min_cost_scheduler.add_seq_group(seq_group)
- 如何定义最空闲的调度器?
2
return len(self.waiting) + len(self.running) + len(self.swapped);
add_seq_group:将seq_group中所有序列,添加进scheduler的self.waiting队列中
2
self.swapped.append(seq_group)
回到入口函数generate,在_validate_and_add_requests函数之后,所有的seq_group都已经被送入调度器(Scheduler)的waiting队列中。
接下来通过_run_engine执行推理:在1个推理阶段中,调用一次step。
1 | def _run_engine( |
接下来的问题是:step()中如何决定送哪些seq_group去做推理呢?先来看看调度器的结构。
调度器Scheduler
调度器结构
调度器重要属性如下: 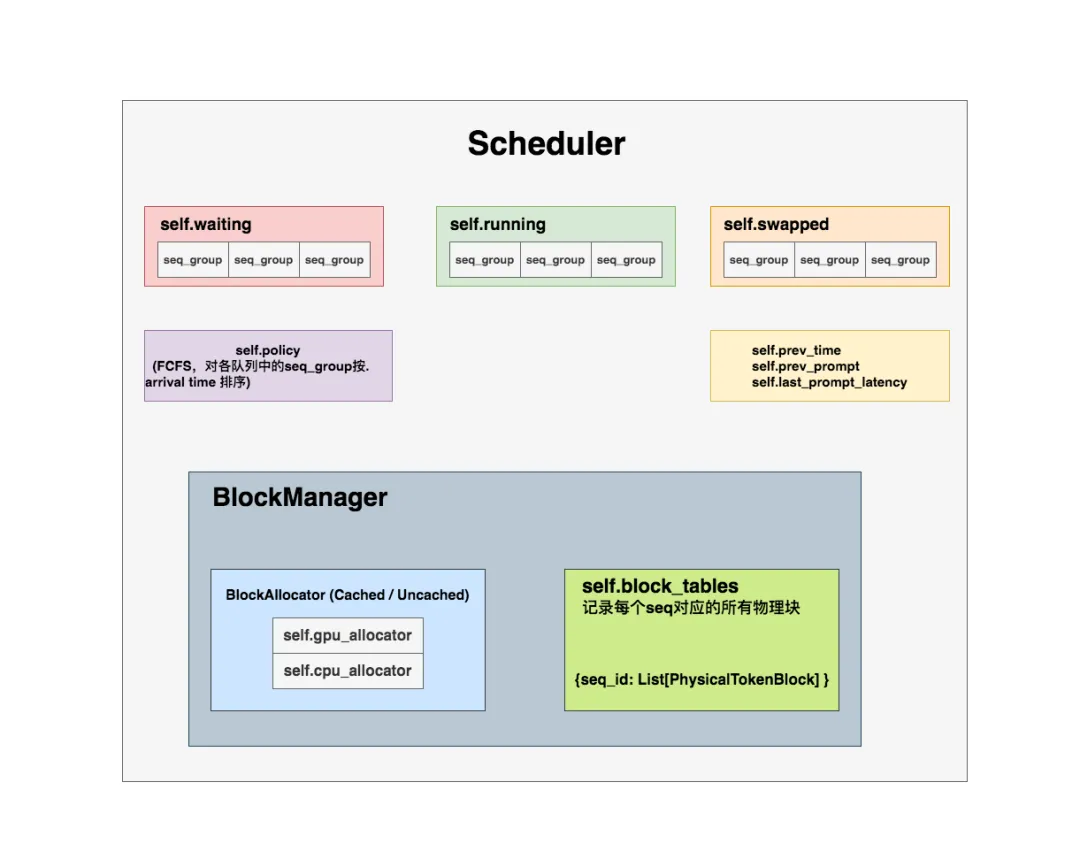
self.waiting, self.running, self.swapped(双端队列:均通过Deque[SequenceGroup] = deque()初始化):waiting队列:存放所有尚未开始推理(未经历prefill阶段)或被抢占的seq_group;初始化时,waiting队列中的seq_group只有一个seq,即原始的prompt;
running队列:存放当前正在做推理的seq_group。更准确地说,它存放的是:上1个推理阶段被送去推理的所有seq_group;在开始新一轮推理阶段时,调度器会根据本轮的筛选结果,更新running队列,即决定本轮要送哪些seq_group去做推理;
swapped队列:存放被抢占的seq_group。若一个seq_group被抢占,调度器会对它执行swap或recomputation操作,分别对应着将它送去swapped队列或waiting队列。
整体调度流程
_schedule_default: 调度待执行的SequenceGroup,在调度过程中根据当前的资源状况(例如 GPU 内存),优先处理prefill请求并按需调度decode请求。最终返回一个包含调度结果的 SchedulerOutputs 对象。
预算由SchedulingBudget定义:max_num_seqs,max_num_batched_tokens分别为1个推理阶段中,LLMEngine最多能处理的seq数量和最多能处理的token数量。
1 | budget = SchedulingBudget( |
如果当前swapped队列为空:检查是否能从waiting队列中调度seq_group(调用
_schedule_prefills),直到不满足调度条件为止(gpu空间不足,或waiting队列已为空等)。此时,1个推理阶段中,所有的seq_group都处在prefill阶段。####1
2
3
4if not self.swapped:
prefills = self._schedule_prefills(budget,
curr_loras,
enable_chunking=False)_schedule_prefills:从waiting队列中调度seq_group(调度的prefill) 初始化:1
2
3
4ignored_seq_groups: List[SequenceGroup] = []
seq_groups: List[ScheduledSequenceGroup] = []
waiting_queue = self.waiting
leftover_waiting_sequences: Deque[SequenceGroup] = deque()ignored_seq_groups:存储被忽略的seq_group,即某个seq_group无法在当前调度中被处理(例如,因为资源不足或超出了容量限制),包括以下两种情况:num_new_tokens > prompt_limitcan_allocate == AllocStatus.NEVER:block_manager无法分配物理块(容量不够)
seq_groups:存储已成功调度并开始执行的seq_group,每个seq_group在成功调度后,都会被包装为一个ScheduledSequenceGroup对象,并添加到这个列表中。同时,调度信息(例如新分配的 token 数量)也会被更新到budget中;leftover_waiting_sequences:存储因某些原因(partial_prefill_metadata非空且不支持调度;没有额外空间分配给新的LoRA请求)暂时无法调度的seq_group。最后,未能调度的seq_group被重新加入waiting_queue中,等待下次调度。waiting_queue:当前处于等待状态的seq_group队列。即已经进入调度系统,但还没有被分配资源来执行。在调度过程中,代码会逐个检查waiting_queue中的seq_group(以下while循环):- 成功调度:从队列中移除,从状态从
WAITING转为RUNNING; - 不能调度:留在队列中,直到符合调度条件为止。
- 成功调度:从队列中移除,从状态从
waiting队列循环:
- 当前时间到达waiting队列的调度间隔阈值,且waiting队列非空:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104while self._passed_delay(time.time()) and waiting_queue:
# 1. 取出最早到达的seq_group
seq_group = waiting_queue[0]
waiting_seqs = seq_group.get_seqs(status=SequenceStatus.WAITING)
'''......'''
'''计算给定seq_group中,缓存/未缓存的tokens数:
遍历seq_group中的每个seq:
1. 解码序列:当前序列每次生成一个新的未缓存的token;
2. 预填充序列:all_num_new_tokens_seq=seq总长度-该seq已计算的tokens数量
2.1 未启用前缀缓存:所有的新token都视为未缓存的token,直接计入;
即:num_uncached_new_tokens += all_num_new_tokens_seq
2.2 启用前缀缓存:获取当前seq缓存的tokens数量,即:
num_cached_tokens_seq = self.block_manager.get_num_cached_tokens(
seq)
'''
num_new_tokens_uncached, num_new_tokens_cached = (
self._get_num_new_uncached_and_cached_tokens(
seq_group,
SequenceStatus.WAITING,
enable_chunking,
budget,
partial_prefill_metadata=partial_prefill_metadata,
))
num_new_tokens = num_new_tokens_uncached + num_new_tokens_cached
'''...'''
# If the sequence group cannot be allocated, stop.
# 2. block_manager判断:是否有充足gpu空间,为该seq_group分配物理块,用于prefill
can_allocate = self.block_manager.can_allocate(
seq_group, num_lookahead_slots=num_lookahead_slots)
if can_allocate == AllocStatus.LATER:
break
elif can_allocate == AllocStatus.NEVER:
logger.warning(
"Input prompt (%d tokens) + lookahead slots (%d) is "
"too long and exceeds the capacity of block_manager",
num_new_tokens,
num_lookahead_slots,
)
for seq in waiting_seqs:
seq.status = SequenceStatus.FINISHED_IGNORED
ignored_seq_groups.append(seq_group)
waiting_queue.popleft()
continue
lora_int_id = 0
if self.lora_enabled:
lora_int_id = seq_group.lora_int_id
assert curr_loras is not None
assert self.lora_config is not None
if (self.lora_enabled and lora_int_id > 0
and lora_int_id not in curr_loras
and len(curr_loras) >= self.lora_config.max_loras):
# We don't have a space for another LoRA, so
# we ignore this request for now.
leftover_waiting_sequences.appendleft(seq_group)
waiting_queue.popleft()
continue
# 3. 本次调度的tokens和seq数是否满足:num_new_tokens_uncached, num_new_seqs最大数量的限制
if (budget.num_batched_tokens
>= self.scheduler_config.max_num_batched_tokens):
# We've reached the budget limit - since there might be
# continuous prefills in the running queue, we should break
# to avoid scheduling any new prefills.
break
num_new_seqs = seq_group.get_max_num_running_seqs()
if num_new_tokens_uncached == 0 or not budget.can_schedule(
num_new_tokens=num_new_tokens_uncached,
num_new_seqs=num_new_seqs,
):
break
# 4. 满足3中条件:开始调度
if curr_loras is not None and lora_int_id > 0:
curr_loras.add(lora_int_id)
# 4.1 从waiting_queue中移除队首元素
waiting_queue.popleft()
# 4.2 block_manager为该seq_group分配物理块,将每个seq的状态标为RUNNING
self._allocate_and_set_running(seq_group)
'''省略:
1. 若enable_chunking和调度器配置的is_multi_step为True,执行以下操作:
初始化一个空的 blocks_to_copy 列表。
调用 self._append_slots(seq_group, blocks_to_copy, enable_chunking) 来处理多步骤分配;
assert not blocks_to_copy 断言检查,确保 blocks_to_copy 在执行完后为空(避免副本写操作)。如果发生副本写操作,可能会引发此断言。
2.
'''
# 4.3 将seq_group包装为ScheduledSequenceGroup,添加到调度的序列组中
seq_groups.append(
ScheduledSequenceGroup(seq_group=seq_group,
token_chunk_size=num_new_tokens))
# 4.4 更新budget中的token使用情况和序列数
budget.add_num_batched_tokens(
seq_group.request_id,
num_batched_tokens=num_new_tokens_uncached,
num_cached_tokens=num_new_tokens_cached,
)
budget.add_num_seqs(seq_group.request_id, num_new_seqs)
- 当前时间到达waiting队列的调度间隔阈值,且waiting队列非空:
将
leftover_waiting_sequences重新加入waiting_queue队首,等待下一次调度:返回
SchedulerPrefillOutputs:1
2
3
4
5
6return SchedulerPrefillOutputs(
seq_groups=seq_groups,
ignored_seq_groups=ignored_seq_groups,
num_lookahead_slots=self._get_num_lookahead_slots(
is_prefill=True, enable_chunking=enable_chunking),
)
_passed_delay:判断调度waiting队列的时间点
模型在推理时,waiting队列中源源不断地有新的seq_group加入。一旦选择调度waiting队列,就会停下对running/swapped中seq_group的decode处理,转而去做waiting中seq_group的prefill(prefill和decode同一时期只有一个在处理中);也即vLLM必须在新来的seq_group和已经在做推理的seq_group之前达成平衡。“waiting队列调度间隔阈值”就是来控制这种均衡的:
调度间隔设置得太小:每次调度都只关心waiting中的新请求,这样发送旧请求的用户迟迟得不到反馈结果;此时waiting队列中积累的新请求数量可能比较少,不利于batching,浪费了并发处理的能力。
调度间隔设置得太大:waiting中的请求持续挤压,对vLLM推理的整体吞吐有影响。
self.prev_prompt:记录上一次调度中,是否从选择了waiting队列中调度seq; *Scheduler初始化时设置为False;若wating队列中有可调度的seq_group(_schedule_prefills中len(seq_groups) > 0),设置为True。self.prev_time:上一次调度的时间点
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 1. 若上一次从waiting队列中调度:计算两次调度的时间间隔
if self.prev_prompt:
self.last_prompt_latency = now - self.prev_time
self.prev_time, self.prev_prompt = now, False
# 2. 延迟调度,使得waiting队列尽量填满(delay_factor自定义)
if self.scheduler_config.delay_factor > 0 and self.waiting:
# 2.1 计算waiting队列中,seq_group的最早到达时间
# now - earliest_arrival_time: seq_group实际等待的时间
# self.scheduler_config.delay_factor * self.last_prompt_latency:seq_group应该等待的时间
earliest_arrival_time = min(
[e.metrics.arrival_time for e in self.waiting])
passed_delay = ((now - earliest_arrival_time)
> (self.scheduler_config.delay_factor *
self.last_prompt_latency) or not self.running)
else:
passed_delay = True
return passed_delay
can_allocate:block_manager判断能否为seq_group分配物理块做prefill
当前我们已从waiting队列中取出了一个seq_group,将对它进行prefill操作。因此需要判断:gpu上是否有充足的物理块分配给该seq_group做prefill呢?
- 这里假设:seq_group中的所有sequences共用同一个prompt(在preempted sequences中不一定成立)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38def can_allocate(self,
seq_group: SequenceGroup,
num_lookahead_slots: int = 0) -> AllocStatus:
check_no_caching_or_swa_for_blockmgr_encdec(self, seq_group)
# 1. 取出这个seq_group下处于waiting状态的序列
seq = seq_group.get_seqs(status=SequenceStatus.WAITING)[0]
# 2. 计算seq所需的逻辑块数量
num_required_blocks = BlockTable.get_num_required_blocks(
seq.get_token_ids(),
block_size=self.block_size,
num_lookahead_slots=num_lookahead_slots,
)
# 3. 如果是encoder-decoder模型(通常是Transformer架构),计算编码器的逻辑块数量:
if seq_group.is_encoder_decoder():
encoder_seq = seq_group.get_encoder_seq()
assert encoder_seq is not None
num_required_blocks += BlockTable.get_num_required_blocks(
encoder_seq.get_token_ids(),
block_size=self.block_size,
)
# 4. 考虑最大块滑动窗口:确保逻辑块数量不会请求超过最大窗口的块数
if self.max_block_sliding_window is not None:
num_required_blocks = min(num_required_blocks,
self.max_block_sliding_window)
# 5. 获取当前GPU上可用的空闲块数量
num_free_gpu_blocks = self.block_allocator.get_num_free_blocks(
device=Device.GPU)
# 6. 检查是否有足够的块可以分配:
if (self.num_total_gpu_blocks - num_required_blocks
< self.watermark_blocks):
return AllocStatus.NEVER # 不分配
if num_free_gpu_blocks - num_required_blocks >= self.watermark_blocks:
return AllocStatus.OK # 立即分配
else:
return AllocStatus.LATER # 稍后分配
watermark_blocks:水位线block数量,起到缓冲作用,防止在1次调度中把gpu上预留给KV Cache的显存空间基本占满,出现一些意外风险(因为预留的显存空间也是估计值)。NEVER和LATER
- 相同点:都是因为当前显存空间不够,而无法继续调度seq_group;
- 不同点:
NEVER是因为seq过长(即prompt太长),以至于gpu上所有的block(num_total_gpu_blocks)都无法完成处理,因此后续步骤中直接将该seq标记为完成,不再处理;LATER是因为之前调度的seq_group占据相当一部分显存空间,导致gpu上剩余的可用block(num_free_gpu_blocks)不够,因此延迟处理。
_schedule_running:
running队列包含:decode和chunked prefill请求
初始化:
1 | decode_seq_groups: List[ScheduledSequenceGroup] = ret.decode_seq_groups |
- running队列循环:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93while running_queue:
# 1. 取出当前running队列中,最早到达的seq_group
seq_group = running_queue[0]
''' 可以丢弃缓存tokens的信息:
1. 如果seq采用chunked prefill,cached tokens info在第一次prefill已使用;
2. 如果seq采用non-chunked prefill,有解码序列,与cached tokens info无关。
'''
num_uncached_new_tokens, _ = \
self._get_num_new_uncached_and_cached_tokens(
seq_group,
SequenceStatus.RUNNING,
enable_chunking,
budget,
partial_prefill_metadata,
)
num_running_tokens = num_uncached_new_tokens
if num_running_tokens == 0:
# No budget => Stop
break
running_queue.popleft()
'''如果启用异步输出处理 (use_async_output_proc),在序列长度超过最大模型长度时:暂停当前序列并加入 _async_stopped 列表,以避免内存溢出。'''
if (self.use_async_output_proc and seq_group.seqs[0].get_len()
> self.scheduler_config.max_model_len):
self._async_stopped.append(seq_group)
continue
# 2. block_manager循环判断:是否有足够的KV cache空间分配给该seq_group做decode
while not self._can_append_slots(seq_group, enable_chunking):
# 没有充足空闲物理块:执行抢占
budget.subtract_num_batched_tokens(seq_group.request_id,
num_running_tokens)
num_running_seqs = seq_group.get_max_num_running_seqs()
budget.subtract_num_seqs(seq_group.request_id,
num_running_seqs)
if (curr_loras is not None and seq_group.lora_int_id > 0
and seq_group.lora_int_id in curr_loras):
curr_loras.remove(seq_group.lora_int_id)
# 2.1 决定被抢占的seq_group:抢占running队列最低优先级的seq_group(队首,FCFS);若running队列为空,抢占当前seq_group(此时跳出循环,因为没有seq_group可供抢占)
cont_loop = True
if running_queue:
victim_seq_group = running_queue.pop()
else:
victim_seq_group = seq_group
cont_loop = False
'''3. 省略:抢占前确定没有正在进行的异步后处理任务'''
# 2.2 执行抢占:两种模式
# swap模式:被抢占的seq_group进入swap队列
# recomputation模式:被抢占的seq_group进入waiting队列
if do_preempt:
preempted_mode = self._preempt(victim_seq_group,
blocks_to_swap_out)
if preempted_mode == PreemptionMode.RECOMPUTE:
preempted.append(victim_seq_group)
else:
swapped_out.append(victim_seq_group)
if not cont_loop:
break
# 有充足空闲物理块:进行分配
else:
self._append_slots(seq_group, blocks_to_copy, enable_chunking)
is_prefill = seq_group.is_prefill()
scheduled_seq_group: ScheduledSequenceGroup = (
self._scheduled_seq_group_cache[
self.cache_id].get_object())
scheduled_seq_group.seq_group = seq_group
if is_prefill:
scheduled_seq_group.token_chunk_size = num_running_tokens
prefill_seq_groups.append(scheduled_seq_group)
ret.prefill_seq_groups_list.append(seq_group)
else:
scheduled_seq_group.token_chunk_size = 1
decode_seq_groups.append(scheduled_seq_group)
ret.decode_seq_groups_list.append(seq_group)
budget.add_num_batched_tokens(seq_group.request_id,
num_running_tokens)
'''优化:get_max_num_running_seqs()是计算昂贵的,对于默认调度阶段,如果enable_chunking==num_seqs在调用该方法前已更新,因此这里不再更新'''
if enable_chunking:
num_running_seqs = seq_group.get_max_num_running_seqs()
budget.add_num_seqs(seq_group.request_id, num_running_seqs)
if curr_loras is not None and seq_group.lora_int_id > 0:
curr_loras.add(seq_group.lora_int_id)
1 | def _schedule_running( |
_can_append_slots:block_+manager判断是否能为seq_group分配充足物理块做decode
做decode时,给每个seq分配1个token的位置;那么running队列中,seq_group下的n个seqs在上1个推理阶段共生成了n个token。本次调度中,先为这n个token分配物理空间,存放其在本次调度中即将产生的KV值。
当往1个seq的物理块上添加1个token时,可能有两种情况: * 之前的物理块已满,新分配一个物理块; * 之前的物理块没满,直接添加在最后一个物理块的空槽位上;
因此对于n个seqs来说,最坏的情况就是添加n个物理块。
考虑最坏情况:判断当前可用的物理块数量,是否至少为n
1 | def can_append_slots(self, seq_group: SequenceGroup, |
块管理器BlockManager
step():完成一次调度
step()方法:执行一次解码迭代,并返回新生成的结果。
- 调度在下一次迭代中执行的序列,以及需要交换、复制或移入/移出的 token 块:
- 如果seq group中还有剩余的步骤,则不调用
Scheduler,保证Scheduler只在当前batch完成后调用; - 如果单个请求导致上一步引擎执行失败,那么
Scheduler也会被跳过,之前的调度需要重新执行。
1 | if not self._has_remaining_steps( |
调用分布式执行器,
execute_model执行模型:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46if not scheduler_outputs.is_empty():
# Check if we have a cached last_output from the previous iteration.
# For supporting PP this is probably the best way to pass the
# sampled_token_ids, as a separate broadcast over all the PP stages
# will cause one virtual engine's microbatch to block the pipeline.
last_sampled_token_ids = \
self._get_last_sampled_token_ids(virtual_engine)
execute_model_req = ExecuteModelRequest(
seq_group_metadata_list=seq_group_metadata_list,
blocks_to_swap_in=scheduler_outputs.blocks_to_swap_in,
blocks_to_swap_out=scheduler_outputs.blocks_to_swap_out,
blocks_to_copy=scheduler_outputs.blocks_to_copy,
num_lookahead_slots=scheduler_outputs.num_lookahead_slots,
running_queue_size=scheduler_outputs.running_queue_size,
finished_requests_ids=finished_requests_ids,
# We use ExecuteModelRequest to pass the last sampled_token_ids
# to each of the non-last PP stages for in-place prepare_input.
last_sampled_token_ids=last_sampled_token_ids)
if allow_async_output_proc:
execute_model_req.async_callback = self.async_callbacks[
virtual_engine]
try:
outputs = self.model_executor.execute_model(
execute_model_req=execute_model_req)
self._skip_scheduling_next_step = False
except InputProcessingError as e:
# The input for this request cannot be processed, so we must
# abort it. If there are remaining requests in the batch that
# have been scheduled, they will be retried on the next step.
invalid_request_id = e.request_id
self._abort_and_cache_schedule(
request_id=invalid_request_id,
virtual_engine=virtual_engine,
seq_group_metadata_list=seq_group_metadata_list,
scheduler_outputs=scheduler_outputs,
allow_async_output_proc=allow_async_output_proc)
# Raise so the caller is notified that this request failed
raise
# We need to do this here so that last step's sampled_token_ids can
# be passed to the next iteration for PP.
if self.scheduler_config.is_multi_step:
self._update_cached_scheduler_output(virtual_engine, outputs)处理输出
致谢
部分图转自:
