verl框架:2. 对比OpenRLHF+colocate思路解析
SPMD->MPMD
SPMD设计范式:单程序多数据,所有进程/线程执行同一个程序的拷贝,通过环境变量差异自主确定行为模式,无需中心调度节点。主流并行框架(DDP/DeepSpeed/Megatron)均基于SPMD范式。
优点:SPMD由于没有controller,完全由worker自驱,在运行时更为高效;
缺点:由于各个worker上需要运行相同程序,灵活性不如single-controller模式;需要考虑各个rank之间的通信,增加编程复杂度。
经典代码如下:
1 | import torch |
torchrun执行以上脚本,启动多个进程;每个进程不同的环境变量,标识其所属的机器号和端口号,以及进程号和进程总数。torch.distributed.init_process_group根据环境变量构建通信组(一个阻塞操作,所有进程必须完成后才开始执行)set_device将当前进程绑定在一块GPU上。
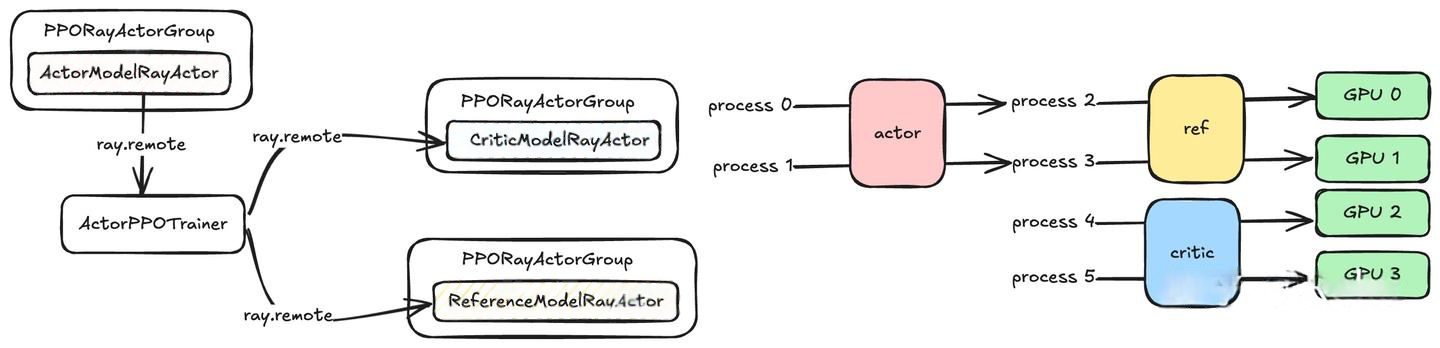
OpenRLHF SPMD ppo的系统架构如下:PPOTrainer负责整个PPO算法的控制逻辑。此时,不同的模型在同一组卡和同一组进程上,按照不同的时间片运行SPMD。这些共享同一组计算资源并按时间交替使用的模型被称为colocate models。
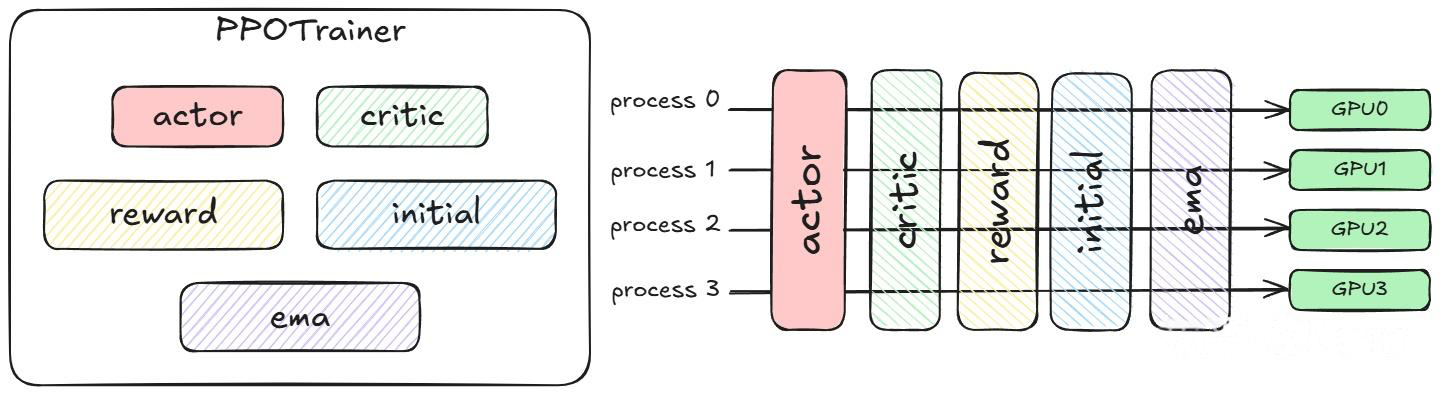
然而,SPMD要求不同的模型串行执行,即使没有数据依赖的模型也难以实现并发。如果模型不需要占用全部计算卡,就会导致部分计算资源的闲置;此外,SPMD需要将多个模型的参数同时加载到一张计算卡上,如果不结合offload等技术,很容易引发显存OOM问题。
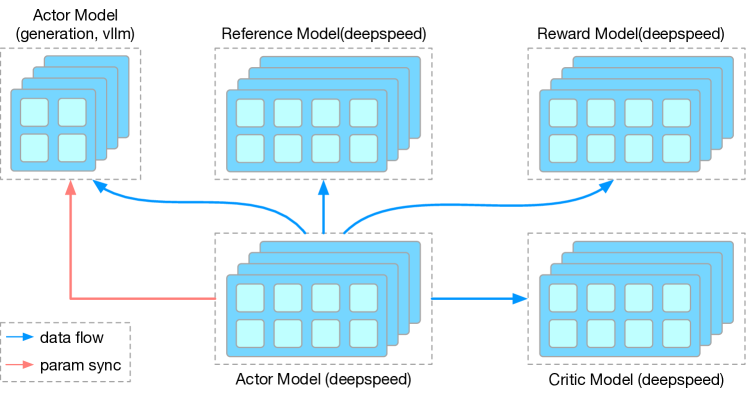
那么如何实现这一点呢?OpenRLHF的方案是:使用ray拉起。在 Ray 的抽象下,各个模块都可以看成是独立的 multi-process training / generate,通过配置不同的placement group,从而使模块绑定到不同的卡上;模块之间的交互通过 Object Store 和 Object Ref 做数据收发来实现。
OpenRLHF的Ray流程
OpenRLHF与Ray相关的架构图如下:
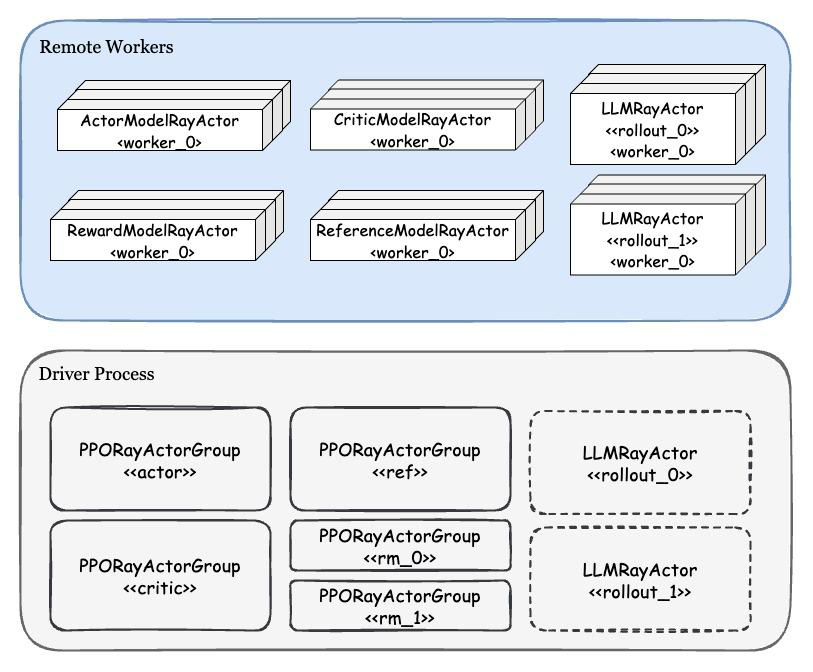
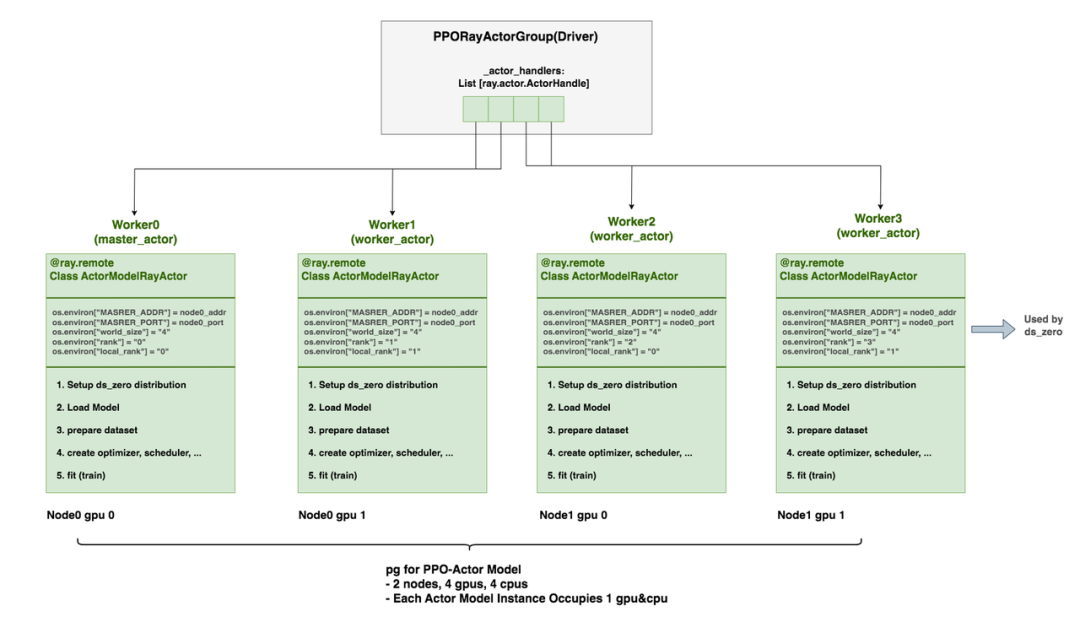
Driver Process
- 在Driver process中实例化多个PPORayActorGroup:每一个 Group 实例代表着一个PPO模块,包含1个Master Ray-Actor,多个Worker Ray-Actor;每个 Worker Ray-Actor是这个完整模型的 DP 分片。
1 | class PPORayActorGroup: |
创建PPORayActorGroup实例时,其__init__函数包括创建Ray Actor集群,过程如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
world_size = self._num_nodes * self._num_gpus_per_node # 总GPU数量
# 1. 创建 Placement Group(每个节点上GPU数量多于1个):默认每个Actor需要1GPU+1CPU
if self._num_gpus_per_node > 1 and pg is None:
bundles = [{"GPU": 1, "CPU": 1} for _ in range(self._num_nodes * self._num_gpus_per_node)]
if self._resources:
......
pg = placement_group(bundles, strategy="PACK")
ray.get(pg.ready())
# 2. 创建Master Ray-Actor(rank=0):
if pg:
master_actor = self.ray_actor_type.options(
......
).remote(world_size, 0, None, None) # None, None:Master 的地址和端口
else:
master_actor = self.ray_actor_type.options(
......
).remote(world_size, 0, None, None)
self._actor_handlers = [master_actor]
# 3. 创建 Worker Ray-Actor(rank=1 到 world_size-1)
if world_size > 1:
master_addr,master_port=ray.get(master_actor.get_master_addr_port.remote())
for rank in range(1, world_size):
if pg:
worker_actor = self.ray_actor_type.options(
......
),
).remote(world_size, rank, master_addr, master_port)
else:
worker_actor = self.ray_actor_type.options(
......
).remote(world_size, rank, master_addr, master_port)
self._actor_handlers.append(worker_actor)
PPORayActorGroup中维护列表self._actor_handlers,是一个List[ray.actor.ActorHandle],列表中每个元素表示某个远端Ray-Actor的引用(对应PPO-Actor/Ref/Critic/RM实例)。可以在Ray集群中的任何位置调用这个handler,来对相应的远端Ray-Actor执行操作。ActorModelRayActor:创建在远端worker进程上,是Ray-Actor。它包含了设置ds_zero分布式环境、加载模型权重、数据集准备、optimizer/scheduler准备、训练等一系列操作。
注意:PPORayActorGroup在Driver Process中完成实例化,但主进程中并不包括控制逻辑;算法逻辑在模块对应的PPORayActorGroup中,通过远程调用ActorPPOTrainer实现。
Ray远程调用fit,开始训练
完成参数初始化、各个模块建立和模型初始化后,控制逻辑交给了隶属于 Actor 的 Group,调用async_fit_actor_model,这个方法内会调用所有 Actor worker 的 fit方法,本质上是调用了PPOTrainer.fit。使得所有worker同时开始训练。
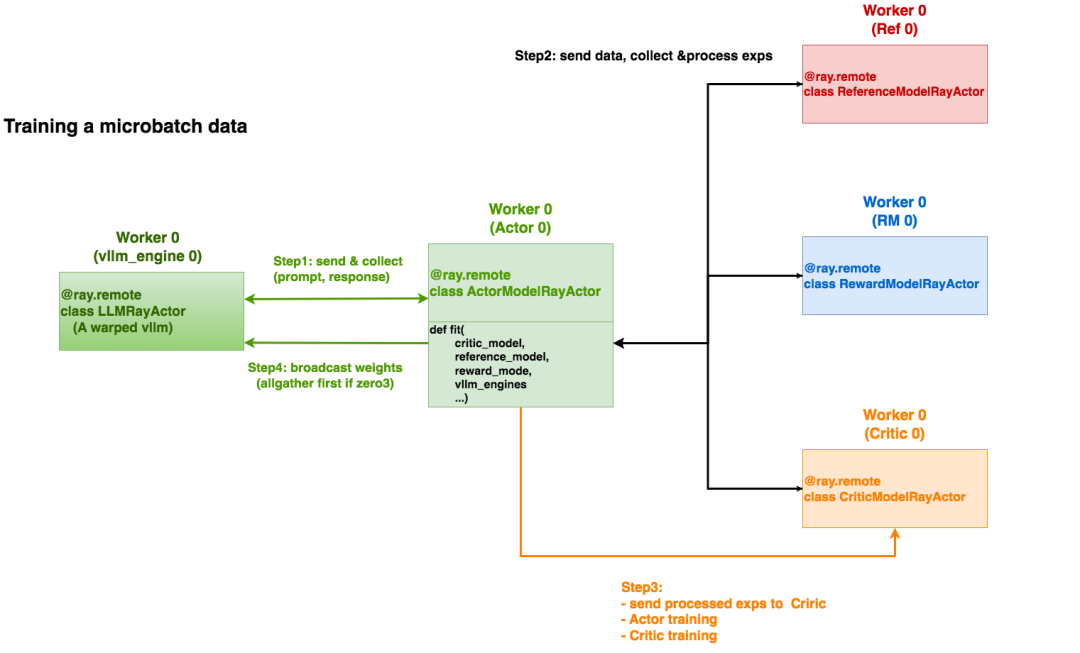
异步调用的实现方式:
async_run_method函数通过self._actor_handlers,实现在相应的远端Ray-Actor上异步调用任意指定的方法。
2
3
4
5
6
refs = []
for actor in self._actor_handlers:
method = getattr(actor, method_name)
refs.append(method.remote(*args, **kwargs))
return refs
初始化阶段:初始化训练参数,设置评估和模型保存频率。若未指定,默认每个epoch评估一次,且不自动保存检查点。
1
2
3
4def fit(self) -> None:
args = self.args
# 加载数据集
num_rollouts_per_episodes = len(self.prompts_dataloader)检查点加载与vLLM引擎唤醒:
- 检查检查点路径是否存在,若存在则加载;
- 若使用vLLM引擎且启用睡眠模式:先唤醒引擎再广播参数,完成后恢复睡眠以节省资源。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 广播初始检查点到vLLM引擎
ckpt_path = os.path.join(args.ckpt_path, "_actor")
if args.load_checkpoint and os.path.exists(ckpt_path) and not self.vllm_engines is None:
# 若启用vLLM睡眠模式,先唤醒引擎
if self.strategy.args.vllm_enable_sleep:
from openrlhf.trainer.ray.vllm_engine import batch_vllm_engine_call
batch_vllm_engine_call(self.vllm_engines, "wake_up")
# 异步广播模型参数到vLLM
ref = self.actor_model_group.async_run_method(method_name="broadcast_to_vllm")
ray.get(ref)
# 广播完成后重新进入睡眠模式
if self.strategy.args.vllm_enable_sleep:
batch_vllm_engine_call(self.vllm_engines, "sleep")恢复训练状态:从断点恢复训练进度,计算当前所处的episode和step
1
2
3
4
5# 获取已消耗的样本数和当前步数
consumed_samples = ray.get(self.actor_model_group.async_run_method(method_name="get_consumed_samples"))[0]
steps = consumed_samples // args.rollout_batch_size + 1
start_episode = consumed_samples // args.rollout_batch_size // num_rollouts_per_episodes
consumed_samples = consumed_samples % (num_rollouts_per_episodes * args.rollout_batch_size)训练主循环:
- 设置数据加载器的epoch和样本偏移,使用
tqdm显示当前episode进度条; - 核心步骤:
- 经验生成:根据输入prompts生成交互经验;
- 数据分发:将经验数据异步发送给Actor和Critic模型;
- PPO训练:调用
ppo_train更新模型参数;
- KL控制与日志记录:
- KL控制:动态调整KL散度惩罚系数;
- 保存日志/检查点内容:日志包括生成样本、奖励值、训练状态等;检查点按配置频率保存模型和训练状态。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36for episode in range(start_episode, args.num_episodes):
# 设置数据加载器的epoch和样本偏移
self.prompts_dataloader.sampler.set_epoch(
episode, consumed_samples=0 if episode > start_episode else consumed_samples
)
pbar = tqdm(range(self.prompts_dataloader.__len__()), desc=f"Episode [{episode + 1}/{args.num_episodes}]")
for _, rand_prompts, labels in self.prompts_dataloader:
# 生成经验数据(状态-动作-奖励序列)
experiences = self.experience_maker.make_experience_list(rand_prompts, labels, **self.generate_kwargs)
# 解码示例样本(用于日志)
sample0 = self.tokenizer.batch_decode(experiences[0].sequences[0].unsqueeze(0), skip_special_tokens=True)
print(sample0)
# 异步将经验数据分发到Actor和Critic模型组
refs = self.actor_model_group.async_run_method_batch(method_name="append", experience=experiences)
if self.critic_model_group is not None:
refs.extend(self.critic_model_group.async_run_method_batch(method_name="append", experience=experiences))
ray.get(refs)
# 执行PPO训练步骤
status = self.ppo_train(steps)
# 更新KL散度控制器
if "kl" in status:
self.kl_ctl.update(status["kl"], args.rollout_batch_size * args.n_samples_per_prompt)
pbar.set_postfix(status)
#记录生成样本和奖励
status["generated_samples"] = [sample0[0], experiences[0].info["reward"][0]]
# 保存日志和检查点
client_states = {"consumed_samples": steps * args.rollout_batch_size}
self.save_logs_and_checkpoints(args, steps, pbar, status, client_states)
pbar.update()
steps = steps + 1- 设置数据加载器的epoch和样本偏移,使用
训练终止:训练结束后关闭WandB/TensorBoard日志连接。
1
2
3
4if self._wandb is not None:
self._wandb.finish()
if self._tensorboard is not None:
self._tensorboard.close()
Step1. 样本生成:将这个 batch 的 prompts 输入给 Actor,rollout 得到 responses
从make_experience_list进入,调用链为:make_experience_list->generate_samples->_generate_vllm
初始化采样参数:
1
2
3
4
5
6sampling_params = SamplingParams(
temperature=kwargs.get("temperature", 1.0),
top_p=kwargs.get("top_p", 1.0),
max_tokens=kwargs.get("max_new_tokens", 1024),
...
)扩展prompts:采用数据增强,每个提示生成多份样本
1
2n_samples_per_prompt = kwargs.pop("n_samples_per_prompt", args.n_samples_per_prompt)
all_prompts = sum([[prompt] * n_samples_per_prompt for prompt in all_prompts], [])分布式请求分发:异步调用每个vllm引擎上的
add_requests方法Vllm engine上的
add_requests:收集所有Ray-Actor上的请求,统一生成responses1
2
3
4
5
6
7
8
9
10
11def add_requests(self, actor_rank, *, sampling_params, prompt_token_ids):
......
# 批量生成
responses = self.llm.generate(prompts=requests, sampling_params=sampling_params)
# 结果分发
offset = 0
self.responses = {}
for actor_rank, num in num_requests:
self.response_queues[actor_rank].put(responses[offset : offset + num])
offset += num
self.requests = {} # 状态重置调用
generate函数,完成基于PyTorch的文本生成:调用Pytorch的generate函数:1
2
3
4
5
6
7
8
9
10
11
12
def generate(self, input_ids: torch.Tensor, **kwargs) -> Union[
Tuple[torch.LongTensor, torch.LongTensor],
Tuple[torch.LongTensor, torch.LongTensor, torch.BoolTensor],
]:
......
# Call generate
sequences = self.model.generate(**generate_args)
# Prepare mask tensor
eos_token_id = generate_args["eos_token_id"]
pad_token_id = generate_args["pad_token_id"]
return process_sequences(sequences, input_ids.size(1), eos_token_id, pad_token_id)1
2
3
4
5batch_size = (len(all_prompt_token_ids) + len(llms) - 1) // len(llms)
for i, llm in enumerate(llms):
prompt_token_ids = all_prompt_token_ids[i*batch_size : (i+1)*batch_size]
refs.append(llm.add_requests.remote(...))
ray.get(refs)收集结果,进行批处理和标准化:
1
2
3
4all_outputs = sum(ray.get(all_output_refs), [])
sequences, attention_mask, action_mask = process_sequences(
sequences, batch_max_input_len, eos_token_id, pad_token_id
)
最后封装样本的数据结构如下:
1 | Samples( |
Step2. 收集experiences:从Ref/Reward/Critic上收集并处理exps
从make_experience_list进入,调用链为:make_experience_list->make_experience
数据准备:在一遍inference后,收集所有样本信息,为批处理做准备
1
2
3sequences_list = [s.sequences for s in samples_list]
attention_mask_list = [s.attention_mask for s in samples_list]
......计算Reward模型:
- 本地模式:直接调用模型组进行计算
- 远程模式:通过Ray分发到远程服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32r_refs = None
if not self.remote_rm_url: # 本地奖励模型:
r_refs = self.reward_model_group.async_run_method_batch(
......
)
else: # 远程奖励服务
queries_list = sum(
[self.tokenizer.batch_decode(seq, skip_special_tokens=False) for seq in sequences_list], []
)
if self.custom_reward_func: # 自定义奖励模型
......
for i in range(num_chunks):
......
r = self.custom_reward_func.remote(
queries_list[start_idx:end_idx],
prompts_list[start_idx:end_idx],
labels_list[start_idx:end_idx],
)
r_refs.append(r)
else: # 将数据分布在不同的远程奖励模型服务器上
num_servers = len(self.remote_rm_url)
batch_size = (len(queries_list) + num_servers - 1) // num_servers
r_refs = []
for i in range(num_servers):
......
r = remote_rm_fn_ray.remote(
rm,
queries=queries_list[start_idx:end_idx],
prompts=prompts_list[start_idx:end_idx],
labels=labels_list[start_idx:end_idx],
)
r_refs.append(r)从Ref/Critic上收集exps:
action_log_probs: 当前策略的动作概率value: 状态价值估计base_action_log_probs: 参考策略的动作概率(用于KL散度计算)
1
2
3
4
5
6
7
8# Actor模型(当前策略)
action_log_probs_ref = self.actor_model_group.async_run_method_batch(...)
# Critic模型(价值函数)
value_ref = self.critic_model_group.async_run_method_batch(...)
# 初始模型(参考策略)
base_action_log_probs_ref = self.initial_model_group.async_run_method_batch(...)结果整合:
1
2
3
4
5
6
7
8
9
10
11
12experience = Experience(
sequences, # 输入序列
action_log_probs, # 当前策略logprobs
base_action_log_probs, # 参考策略logprobs
value, # 价值函数输出
None, # 初始化为空的advantage
None, # 初始化为空的return
attention_mask, # 注意力掩码
samples.action_mask, # 动作掩码
info, # 元信息
kl # KL散度
)计算KL散度:衡量当前策略与参考策略的差异
1
2kl = compute_approx_kl(action_log_probs, base_action_log_probs)
kl_mean = masked_mean(kl, samples.action_mask)
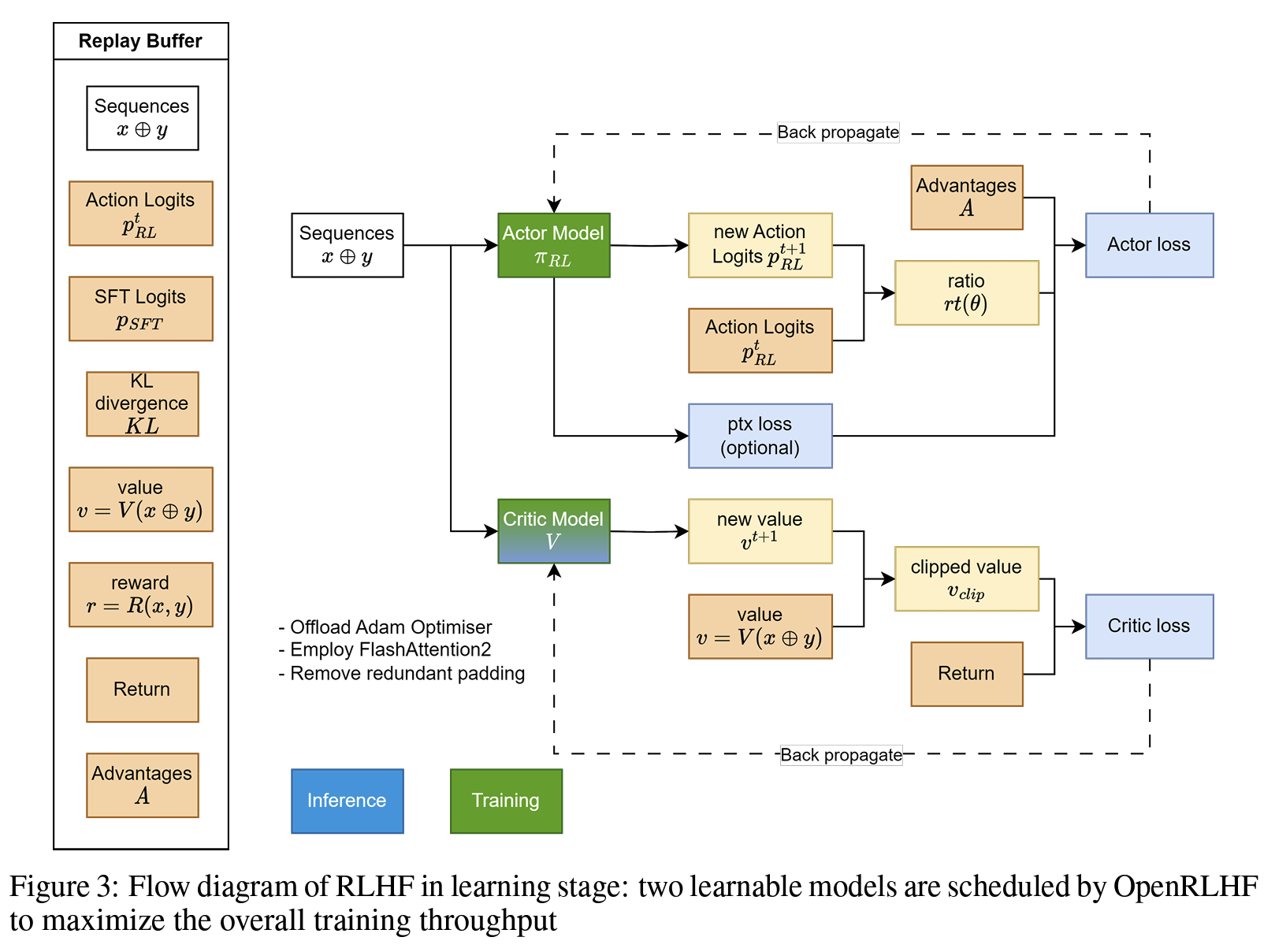
Step3. 确保将处理后的exps传送给Critic,并行执行Actor和Critic的训练
从PPOTrainer.ppo_train开始:这里critic_model_group,actor_model_group均为PPORayActorGroup,通过async_run_method远程调用Ray-Actor上的fit方法。
1 | def ppo_train(self, global_steps): |
ppo_critic,ppo_actor在Ray上分别有各自的ppo_train函数:
1
2
3
4
5
6if self.critic is not None:
for experience in experiences:
# send experience to critic
experience_cpu = deepcopy(experience)
experience_cpu.to_device("cpu")
self._ref = self.critic.append.remote(experience_cpu)Actor训练:调用链为:
PPOTrainer.ppo_train->ActorModelRayActor.fit->`ActorModelRayActor.ppo_trainCritic训练:调用链为:
PPOTrainer.ppo_train->CriticModelRayActor.fit->``CriticModelRayActor.ppo_train
Step4. vllm_engine权重更新
总流程
最后看看总流程:OpenRLHF/openrlhf/cli/train_ppo_ray.py
1 | def train(args): |
OpenRLHF的Colocate策略
原理
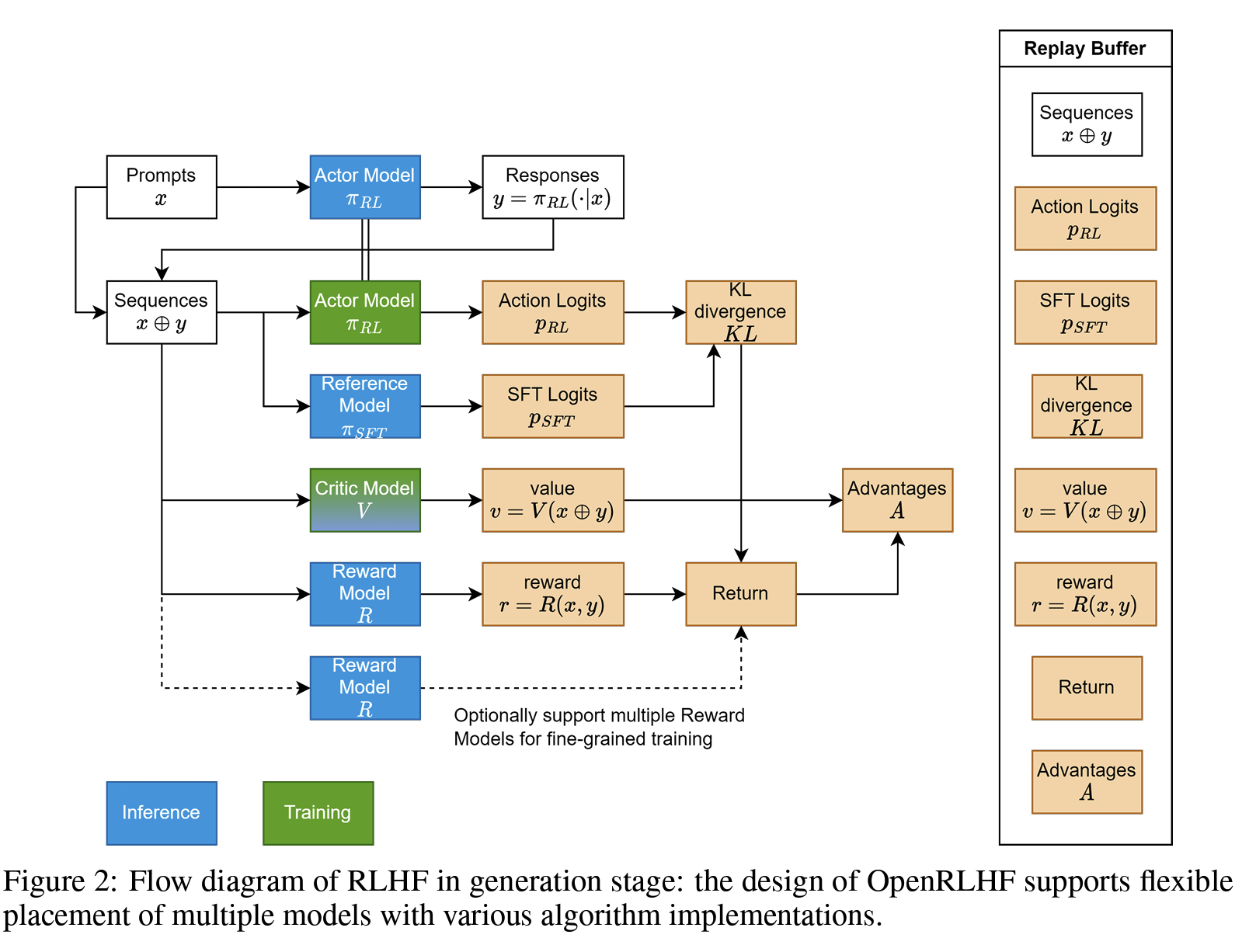
在进入colocate策略的分析前,先回顾一下PPO的工作流:
准备一个 batch 的 prompts;
将这个 batch 的 prompts 输入给 Actor,rollout 得到 responses;
将 prompt + responses 输入给 Critic/Reward/Reference,进行 inference,分别计算得得到 values、reward 和 log probs,将这些整合称为 experiences;

根据 experiences 多轮计算 actor loss 和 critic loss 并更新 Actor 和 Critic。
再纵向整理一次各个模块的工作流:
Actor:需要 training engine 和 rollout engine。前者使用现代 training engine,比如 Megatron 或者 FSDP,后者得用现代推理引擎,比如 SGLang 或者 vllm 作为 rollout engine。有一个小问题,为什么不能拿着 training engine 得到的 logits 做 sampling 然后 decode,貌似也可以用去 rollout?简单来说,太慢了,用训练引擎做 decode 的效果自然不如专用的推理引擎。
Critic:需要 training engine 和 inference engine。前者还是是现代的训练引擎,但是后者,可以用现代的推理引擎的高效 prefill 来得到 value 么?其实不能,critic model 的 inference 会直接复用 training engine 的 forward 来得到 value,所以 critic 的 inference engine 和 training engine 其实是同一个。
Reference 和 Reward:只需要 inference,因为二者不需要训练,但是用现代推理引擎得到的 log probs 和 reward 的精度不如用现代训练引擎得到的精度,所以这里选择用 training engine 的 forward 来做 inference,得到 log probs 和 reward。
collocate 策略:
- 将 actor 的 training engine 和 reference 的 inference engine 放置在同一个资源组上;
- 将 critic 的 training/inference engine 和 reward 的 inference engine 放置在同一个资源组上;
- 最后单独放置 actor 的 rollout engine。
部署Actor/Ref/Critic/RM实例
非共同部署
一个部署示例如下:
1 | actor_model = PPORayActorGroup( |
其中,num_gpus_per_actor等于1说明每个实例占满一张gpu,即“非共同部署”;小于1说明每个实例只占部分gpu,即“共同部署”。
共同部署
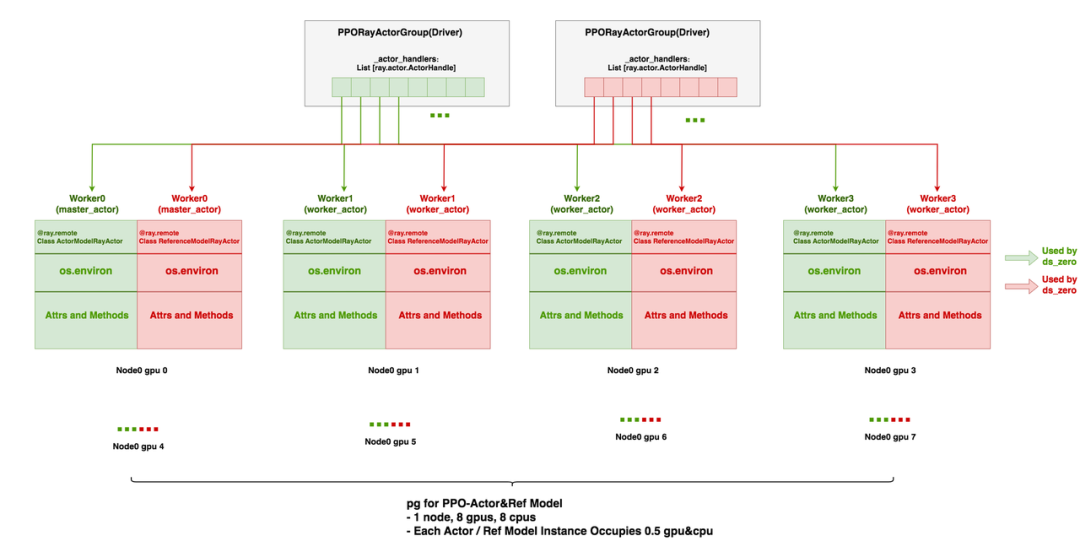
这里展示PPO-Actor和PPO-Reference的colocate策略:
创建一个PlacementGroup,接下来Actor和Reference实例均使用这个配置方案:
1
2bundles = [{"GPU": 1, "CPU": 1} for _ in range(args.actor_num_nodes * args.actor_num_gpus_per_node)]
pg = placement_group(bundles, strategy="PACK")PPO-Actor和PPO-Reference分别创建一个PPORayActorGroup。为了实现模块之间的colocate,往两个Group中传入同一个pg:
在Group内部,通过
num_gpus_per_actor分配每个worker的bundle
1 | ...... |
部署vllm_engines实例
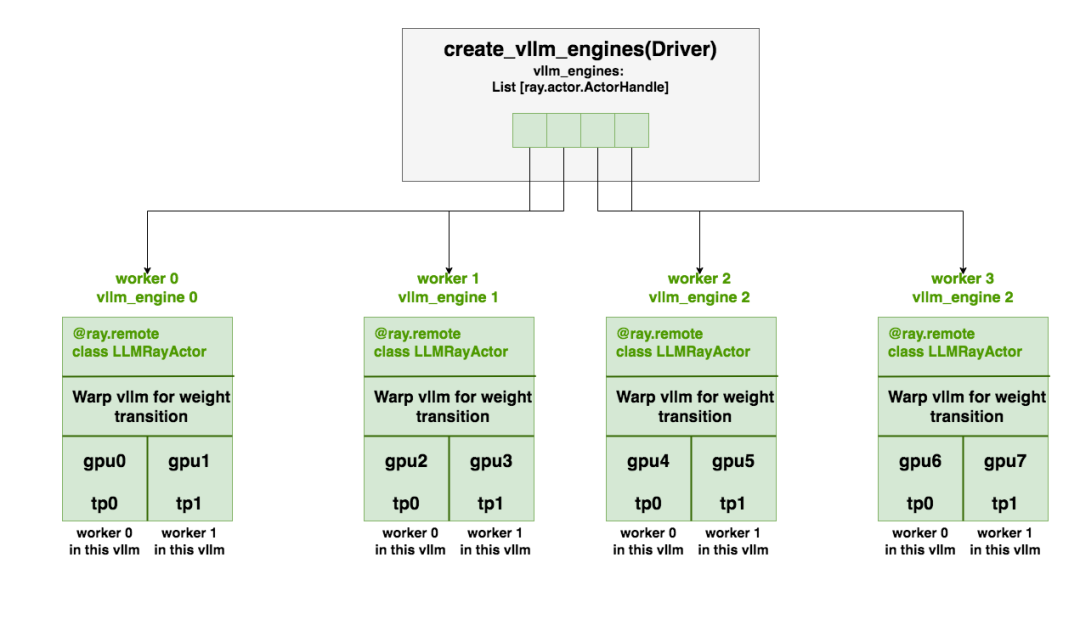
对于Rollout模块:
- Driver process中创建一个或多个LLMRayActor(worker端的Ray-Actor),每个代表一个 vLLM engine(一个完整的 DP 模型),由create_vllm_engines创建。
1 | # create_vllm_engines函数部分代码: |
每个 engine 内部通过 Ray 启动 TP Ray-Actor(这个 Ray-Actor 会 attach 到已有的 cluster,不会新建一个)。
ds_rank0与vllm_ranks之间的通信
假设DP分组如下:
- Actor0 / Ref0 / RM0 / Critic0 / vllm_engine0为一组
- Actor1 / Ref1 / RM1 / Critic1 / vllm_engine1为一组
- Actor2 / Ref2 / RM2 / Critic2 / vllm_engine2为一组
- Actor3 / Ref3 / RM3 / Critic3 / vllm_engine3为一组
每一组负责一个micro-batch的训练(一个DP分片)。
在OpenRLHF中,Actor和Rollout是两个独立的模块,前者放在deepseed训练引擎,后者放在vLLM中,需要保持权重同步。因此,当PPO-Actor更新时,ds_rank0需要和all_vllm_ranks进行通讯,最新的权重broadcast给所有vllm_ranks:
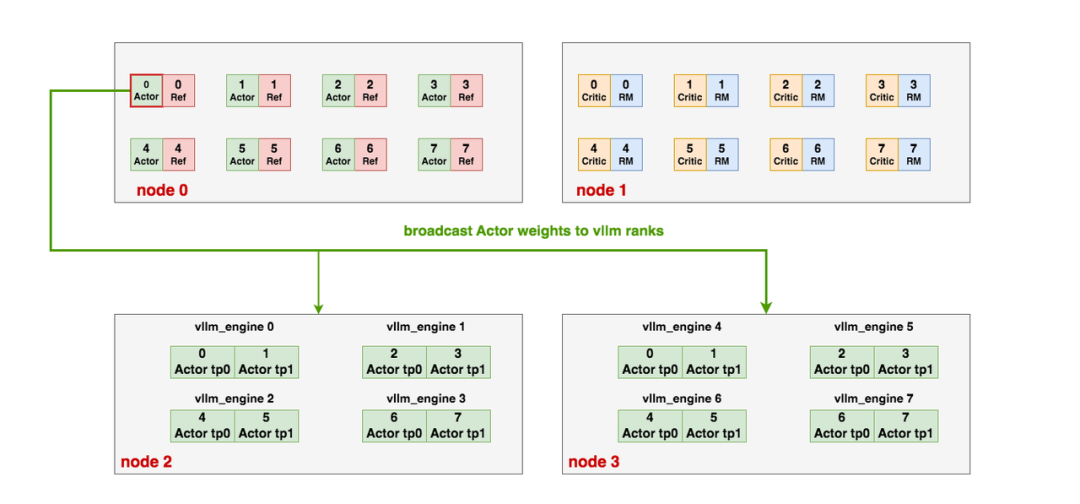
分成以下几个步骤:
创建通信组
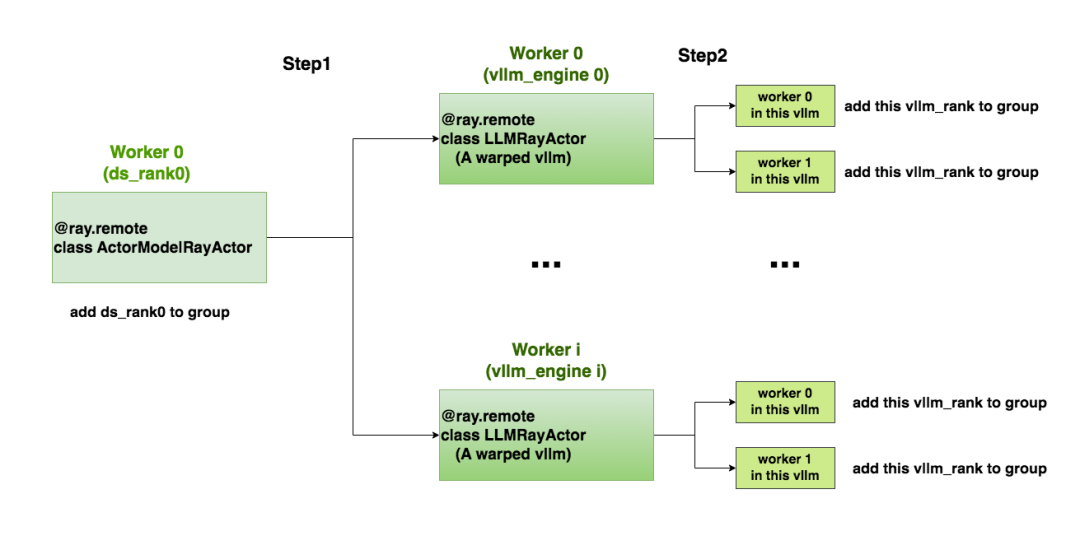
PPO-Actor0(ds_rank0)所在的worker进程:通过handler引用,触发远端每个vllm_engine上的init_process_group操作,并将ds_rank0纳入通讯组。code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55# Create torch group with deepspeed rank 0 and all vllm ranks
# to update vllm engine's weights after each training stage.
#
# Say we have 3 vllm engines and eache of them has 4 GPUs,
# then the torch group is:
# [ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
# |ds rank 0 | engine-0 | engine-1 | engine-2 |
#
# For ZeRO-1/2:
# 1. Broadcast parameters from rank 0 to all vllm engines
# For ZeRO-3:
# 1. AllGather paramters to rank 0
# 2. Broadcast parameters from rank 0 to all vllm engines
if self.vllm_engines is not None and torch.distributed.get_rank() == 0:
...
# world_size = num_of_all_vllm_ranks + 1 ds_rank0
world_size = vllm_num_engines * vllm_tensor_parallel_size + 1
...
# =====================================================================
# 遍历每个vllm_engines,将其下的每个vllm_rank添加进通讯组中,这里又分成两步:
# 1. engine.init_process_group.remote(...):
# 首先,触发远程vllm_engine的init_process_group方法
# 2. 远程vllm_engine是一个包装过的vllm实例,它的init_process_group
# 方法将进一步触发这个vllm实例下的各个worker进程(见4.4图例),
# 最终是在这些worker进程上执行“将每个vllm_rank"添加进ds_rank0通讯组的工作
# =====================================================================
refs = [
engine.init_process_group.remote(
# ds_rank0所在node addr
master_address,
# ds_rank0所在node port
master_port,
# 该vllm_engine的第一个rank在"ds_rank0 + all_vllm_ranks“中的global_rank,
# 该值将作为一个offset,以该值为起点,可以推算出该vllm_engine中其余vllm_rank的global_rank
i * vllm_tensor_parallel_size + 1,
world_size,
"openrlhf",
backend=backend,
)
for i, engine in enumerate(self.vllm_engines)
]
# =====================================================================
# 将ds_rank0添加进通讯组中
# =====================================================================
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=0,
group_name="openrlhf",
)
# =====================================================================
# 确保all_vllm_ranks都已添加进通讯组中
# =====================================================================
ray.get(refs)每个vllm_engine(即每个包装后的vllm实例)下的worker进程:code
- 例如tp_size=2,那么每个vllm实例下就有2个worker进程,这两个worker进程都会运行这段代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19class WorkerWrap(Worker):
def init_process_group(self, master_address, master_port, rank_offset, world_size, group_name, backend="nccl"):
assert torch.distributed.is_initialized(), f"default torch process group must be initialized"
assert group_name != "", f"group name must not be empty"
# =====================================================================
# torch.distributed.get_rank(): 在当前vllm_engine内部的rank,
# 例如在tp_size = 2时,这个值要么是0,要么是1
# rank_offset:当前vllm_engine中的第一个rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# 两者相加:最终得到当前rank在“ds_rank0 + all_vllm_ranks"中的global_rank
# =====================================================================
rank = torch.distributed.get_rank() + rank_offset
self._model_update_group = init_process_group(
backend=backend,
init_method=f"tcp://{master_address}:{master_port}",
world_size=world_size,
rank=rank,
group_name=group_name,
)
...
广播PPO-Actor权重到all_vllm_ranks
分成以下两步:
ds_rank0对应的worker进程中:PPO-Actor ds_rank0发送权重 code
准备工作:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15def _broadcast_to_vllm(self):
# 1. 前缀缓存清理:清空 vLLM 的 KV Cache,避免旧参数生成的缓存影响新结果
use_prefix_cache = getattr(self.strategy.args, "enable_prefix_caching", False)
cache_reset_refs = []
if use_prefix_cache and torch.distributed.get_rank() == 0:
# clear prefix cache
for engine in self.vllm_engines:
cache_reset_refs.append(engine.reset_prefix_cache.remote())
# 2. 清理GPU缓存,避免OOM
torch.cuda.empty_cache()
# 3. 遍历模型参数,记录当前参数序号(count)和总参数数(num_params)
model = self.actor.model.module # 获取底层模型(去掉 DP/DDP 包装)
count, num_params = 0, len(list(model.named_parameters()))
for name, param in model.named_parameters():
count += 1广播模式分为两种,通过
self.use_cuda_ipc切换:之后详细阐述每个vllm_engine(即每个包装后的vllm实例)下的worker进程:各个vllm_ranks接收权重 code
1
2
3
4
5
6
7
8
9
10
11
12
13def update_weight(self, name, dtype, shape, empty_cache=False):
if torch.distributed.get_rank() == 0:
print(f"update weight: {name}, dtype: {dtype}, shape: {shape}")
assert dtype == self.model_config.dtype, f"mismatch dtype: src {dtype}, dst {self.model_config.dtype}"
# 创建同尺寸空张量用于接收ds_rank0广播来的权重
weight = torch.empty(shape, dtype=dtype, device="cuda")
# 接收权重
torch.distributed.broadcast(weight, 0, group=self._model_update_group)
# 使用接收到的权重进行更新
self.model_runner.model.load_weights(weights=[(name, weight)])
del weight
默认:常规广播(Ray Collective 或 PyTorch DDP)
条件:self.use_cuda_ipc = False(初始化)
use_ray=True:使用ray.util.collective进行跨节点广播use_ray=False:使用 PyTorch 原生torch.distributed.broadcast
1 | if not self.use_cuda_ipc: |
CUDA IPC 高速通信
条件:Actor和Rollout colocate,即采用colocate_all_models策略
1 | if backend == "nccl" and self.strategy.args.colocate_all_models: |
当两个模块时 colocate 到一张卡上时,NCCL 无法做同一张卡上两个进程的通信,所以需要用 CUDA IPC 做进程间通信。
1 | else: |
ZeRO-3并行:
- 先在 Actor workers 内部 all_gather 权重;
- 再由 rank0 代表 Actor 向所有 Rollout 实例 broadcast 权重。
参考
OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework
HybridFlow: A Flexible and Efficient RLHF Framework
基于 Ray 的分离式架构:veRL、OpenRLHF 工程设计
