Transformer 系列:3. Encoder 和 Decoder 的架构
背景
此前的模型(如ByteNet, ConvS2S)使用 CNN 并行计算,但处理长距离依赖关系的能力随着位置间距的增加而减弱(线性或对数增长)。
Transformer 利用自注意力机制,使得关联任意两个位置所需的操作次数降至常数级,极大改善了处理长距离依赖的能力;引入 Multi-Head Attention 抵消因注意力位置平均化可能导致的"有效分辨率"下降问题。
Transformer 是第一个只依赖 Self-Attnetion 来实现 Encoder-Decoder 架构的模型。
模型架构
在 GPT 之前,大部分神经序列转换模型都采用 Encoder-Decoder 结构,Transformer 模型也不例外。Encoder 将输入的符号序列\((x_1,...,x_n)\)映射为一个连续序列\(z=(z_1,...,z_n)\);得到编码后的序列\(z\),Decoder 逐个元素生成输出序列\((y_1,...,y_m)\)。Decoder 每一步输出是 auto-regressive 的,将当前 step 的输出和输入拼接,作为下一个 step 的输入。
![]() Transformer 架构由 Encoder 和 Decoder 两个部分组成:其中 Encoder 和 Decoder 都是由 N=6 个相同的层堆叠而成。
Transformer 架构由 Encoder 和 Decoder 两个部分组成:其中 Encoder 和 Decoder 都是由 N=6 个相同的层堆叠而成。 ![]()
![]()
Encoder
![]() Encoder 结构由 N=6 个相同的 encoder block 堆叠而成,每一层( layer)主要有两个子层(sub-layers): 第一个子层是多头注意力机制(Multi-Head Attention),第二个是简单的位置全连接前馈网络(Positionwise Feed Forward)。
Encoder 结构由 N=6 个相同的 encoder block 堆叠而成,每一层( layer)主要有两个子层(sub-layers): 第一个子层是多头注意力机制(Multi-Head Attention),第二个是简单的位置全连接前馈网络(Positionwise Feed Forward)。
Tensor 形状变化
Encoder 的输入是待推理的句子序列X: [batch_size, seq_len, d_model]。其中:d_model为 embedding vector 的维度。 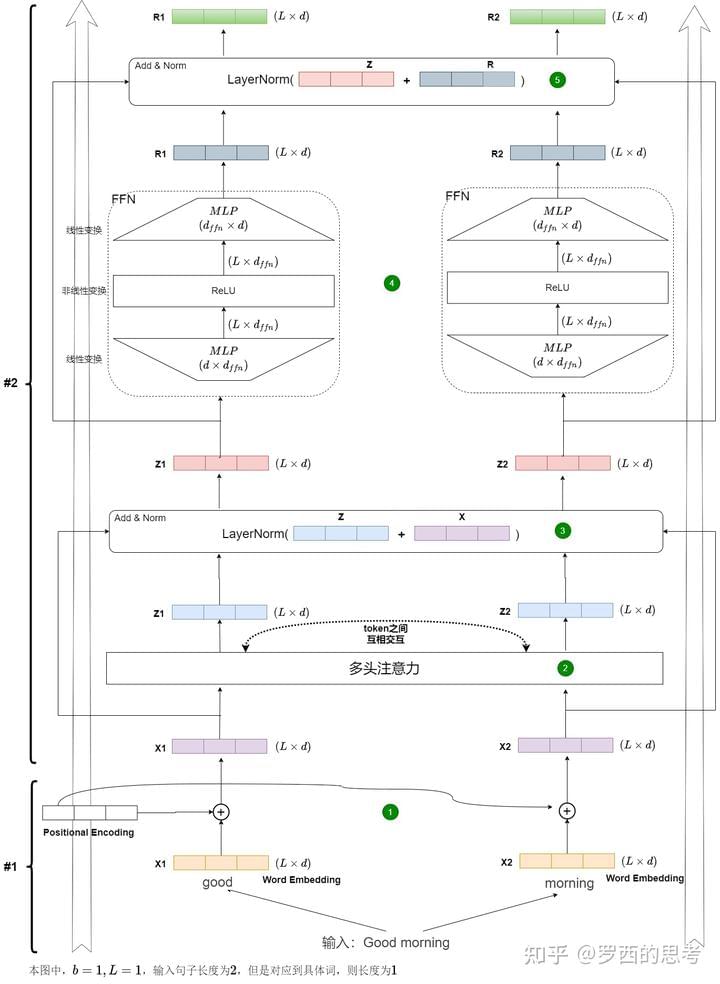
| 操作层级 | 具体操作 | 操作结果张量形状 |
|---|---|---|
| 输入层 | X(token index) | [batch_size, seq_len] |
| 输入层 | X = Embedding(X) | [batch_size, seq_len, d_model] |
| 输入层 | X = X + PositionalEncoding(PE) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X_attn = MultiHeadAttention(X) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X = X + X_attn(残差连接) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X = LayerNorm(X) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X_ffn = FeedForwardNetwork(X) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X = X + X_ffn(残差连接) | [batch_size, seq_len, d_model] |
| 编码器层内部 | X = LayerNorm(X) | [batch_size, seq_len, d_model] |
| 编码器层 | X = EncoderLayer(X) | [batch_size, seq_len, d_model] |
| 编码器 | X = Encoder(X) = 6 × EncoderLayer(X) | [batch_size, seq_len, d_model] |
Add & Norm
Add & Norm 层由 Add 和 Norm 两部分组成:
- Add 指 \(x + \mathrm{Sublayer}(x)\),将多头注意力机制产生的新数据和最开始输入的原始数据合并在一起(采用简单加法),是一种残差连接;
- Norm 是 Layer Normalization,对每个样本在特征维度上进行归一化,使得其均值为0,方差为1。
Add & Norm 层计算过程用数学公式可表达为: \(\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))\)
为什么需要归一化(Normalization)?
- 解决梯度消失,加速收敛:网络加深时,层间输入分布易进入激活函数(如Sigmoid、Tanh)的饱和区,导致梯度变小甚至消失;归一化将输入重新中心化为均值为0、方差为1的分布,使其落在激活函数的敏感(线性)区域,从而稳定和加速训练。
- 满足独立同分布假设:机器学习模型有效的一个基本假设是训练数据和测试数据来自相同的分布;对网络中间层的输出进行归一化,可以稳定其分布,使后续层的学习更有效,提升模型的泛化能力。
BatchNorm 是“跨样本归一化”,而 LayerNorm 是“跨特征归一化”;CV领域多用 BatchNorm,NLP领域多用 LayerNorm。
LayerNorm 基于公式: \[ y=\frac{x-E[x]}{\sqrt{Var[x]+\epsilon}}*\gamma \] LayerNorm 在 Pytorch 中的表示:[LayerNorm
](https://docs.pytorch.org/docs/stable/generated/torch.nn.LayerNorm.html)
2
3
4
5
6
7
"""
1. normalized_shape: 要进行归一化的维度形状,可以是int(最后一维)或list/tuple(表示要归一化的形状,从最后一维开始);
2. eps: 为了数值稳定性添加到分母的小常数,防止除零错误;
3. elementwise_affine: 是否使用可学习的逐元素仿射参数(gamma和beta);
4. bias: 如果为False,则不会学习加性偏置(即beta为0,仅当elementwise_affine为True时有效)
"""例子:
- NLP例子:归一化维度为embedding_dim,即对每个token的embedding向量做归一化;
- 图像例子:归一化维度为[C, H, W],即对每个通道和空间位置做归一化。
LayerNorm 层的 Pytorch 实现代码如下:
1 | class LayerNorm(nn.Module): |
Feed Forward
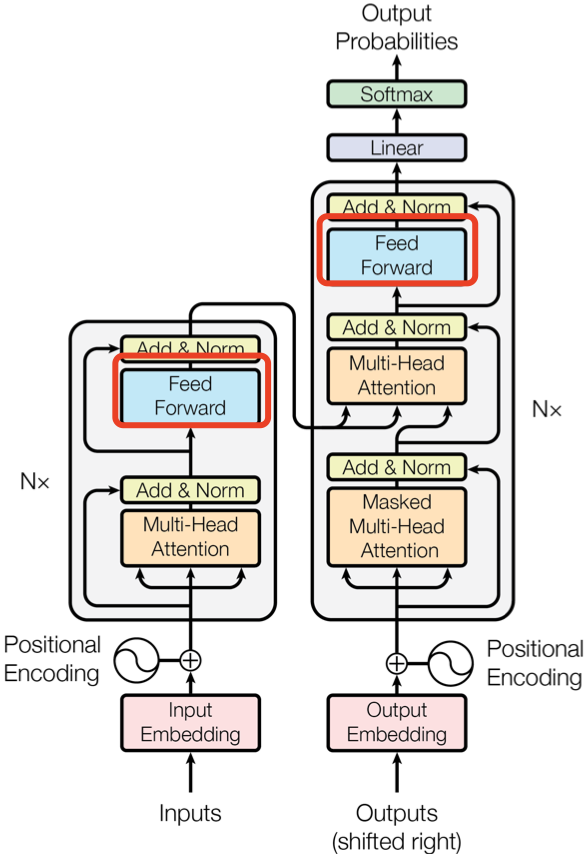
Feed Forward 层全称是 Position-wise Feed-Forward Networks,其本质是一个两层的全连接层,第一层的激活函数为 Relu;第二层不使用激活函数,计算过程用数学公式可表达为:\(FFN(x)=max(0,XW_1+b_1)W_2+b_2\).
除了使用两个全连接层来完成线性变换,另外一种方式是使用 kernal_size = 1 的两个\(1\times 1\)的卷积层,输入输出维度不变,都是 512,中间维度是 2048。
PositionwiseFeedForward 层的 Pytorch 实现代码如下:
1 | class PositionwiseFeedForward(nn.Module): |
实现
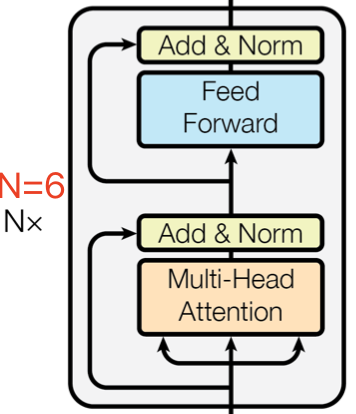
Encoder
Encoder类是编码器的实现:forward()函数返回的是编码之后的向量。
1 | # 使用Encoder类来实现编码器,它继承了 nn.Module 类 |
EncoderLayer
EncoderLayer类是编码器层的实现;作为编码器的组成单元, 每个 EncoderLayer 完成一次对输入的特征提取过程。
1 | class EncoderLayer(nn.Module): |
SublayerConnection
paper 的实现(post LN):\(\mathrm{LayerNorm}(x + \mathrm{Sublayer}(x))\)
SublayerConnection的实现(pre LN):\(x+\mathrm{LayerNorm}(\mathrm{Sublayer}(x))\)
1 | class SublayerConnection(nn.Module): |
Decoder
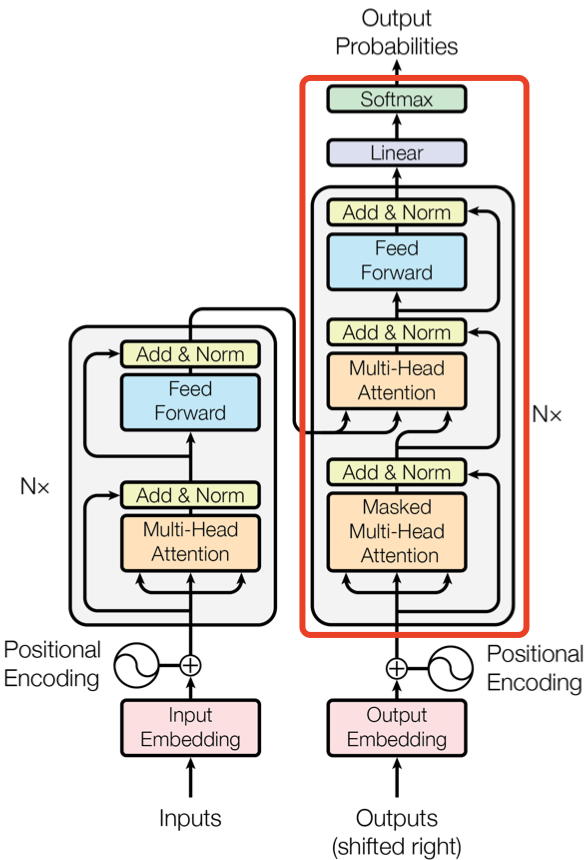 Decoder 组件也是由 N=6 个相同的 Decoder block 堆叠而成。Decoder block 与 Encoder block 相似,但是存在一些区别:
Decoder 组件也是由 N=6 个相同的 Decoder block 堆叠而成。Decoder block 与 Encoder block 相似,但是存在一些区别:
包含两个 Multi-Head Attention 层。
- 第一个 Multi-Head Attention 层采用了 Masked 操作;
- 第二个 Multi-Head Attention 层的 K, V 矩阵使用 Encoder 的编码信息矩阵 C 进行计算,而 Q 使用上一个 Decoder block 的输出计算。这样做的好处是在 Decoder 的时候,每一位单词都可以利用到 Encoder 所有单词的信息 (这些信息无需 Mask)
Tensor 形状变化
解码器的输入是一个长度变化的张量Y:[batch_size, seq_len, d_model],初始时,这个张量中,每个矩阵只有1行(即seq_len=1),即开始字符的编码。
| 操作步骤 | 操作 | 结果张量的形状 |
|---|---|---|
| 输入层 | Y(token index) | [batch_size, seq_len] |
| 输入层 | Y = embedding(Y) | [batch_size, seq_len, d_model] |
| 输入层 | Y = Y + PE | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = Masked-MHA(Y) | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = LayerNorm(Y + Masked-MHA(Y)) | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = Cross-MHA(Y, M, M) | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = LayerNorm(Y + Cross-MHA(Y, M, M)) | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = FFN(Y) | [batch_size, seq_len, d_model] |
| 解码器层内部 | Y = LayerNorm(Y + FFN(Y)) | [batch_size, seq_len, d_model] |
| 解码器层 | Y = DecoderLayer(Y) | [batch_size, seq_len, d_model] |
| 解码器 | Y = Decoder(Y) = N × DecoderLayer(Y) | [batch_size, seq_len, d_model] |
| 输出层 | logits = Linear(Y) | [batch_size, seq_len, d_voc] |
| 输出层 | prob = softmax(logits) | [batch_size, seq_len, d_voc] |
实现
Decoder
Decoder类是解码器的实现,是 N 个解码层堆叠的栈:Decoder类根据当前翻译过的第i个单词,翻译下一个单词(i+1);在解码过程中,翻译到第i+1个单词的时候,需要通过 Mask 操作遮盖住(i+1)之后的单词。代码如下:
1 | class Decoder(nn.Module): |
DecoderLayer
DecoderLayer类是解码器层的实现:作为解码器的组成单元,每个解码器层根据给定的输入向目标方向进行特征提取操作,即解码。
DecoderLayer和EncoderLayer的内部相似,区别在于:EncoderLayer只有一个多头自注意力模块,而DecoderLayer有两个多头自注意力模块(比EncoderLayer多了一个src_attn成员变量;self_attn和src_attn的实现完全一样,只不过使用的Query,Key 和 Value 的输入不同)。
1 | class DecoderLayer(nn.Module): |
参考
探秘Transformer系列之(4)--- 编码器 & 解码器
[大语言模型中的归一化技术:LayerNorm与RMSNorm的深入研究
](https://mp.weixin.qq.com/s/IN_94xagIYOqWsR7KWLivQ)
