深入 Parquet:从 Dremel 论文到列式存储的工程权衡
parquet(列式存储)在 OLAP 场景广泛使用,空闲时间阅读了 paper 和相关源码。
paper 原文阅读:Dremel
Dremel是一个可扩展的交互式查询系统,专门用于分析 read-only 的嵌套数据。它结合了多级执行树和列式数据布局,能够在几秒钟内对万亿行的表运行聚合查询。Dremel 可以扩展到数千个 CPU 和 PB 级数据,并且在 Google 内部有数千名用户。Dremel 并不是用来替代 MapReduce的,而是经常与 MR 结合使用,用于分析 MR 管道的输出或快速原型化更大的计算。
数据模型
Dremel 的数据模型是基于强类型的嵌套记录,抽象语法: \[ t = dom | <A1:t[*|?], ..., An:t[*|?]> \] t 是原子类型或一个记录类型,原子类型包括整型、浮点数、字符串等;Ai 为记录的第 i 个字段,其后的 [*|?] 表示其重复类型。
*表示该字段为Repeated;?表示该字段为Optional;- 无标记则表示该字段为
Required
这一数据模型正是代码生成工具(如Protocol Buffers)的处理对象。
设计用于大规模数据交换和处理的序列化系统需考虑以下因素:
- 跨语言操作:系统设计的首要目标是让不同编程语言(如 C++、Java)编写的模块能够无缝地交换数据。一个 C++ 库产生的数据,应该能被一个 Java 写的 MapReduce 程序直接读取,反之亦然。
- 可扩展性:数据结构(即“记录”)的格式定义是可以演进的,比如添加新字段,而不会完全破坏旧代码的兼容性。
实现机制:嵌套数据模型 + 代码生成工具(比如
Protocol Buffer)+ 标准二进制线格式(将内存中的对象转换成字节流的规则)举个栗子:假设我们有一个用模式定义的语言描述的
User记录:
2
3
4
5
int64 id = 1;
string name = 2;
string email = 3;
}
- 代码生成:工具会生成
User类(C++)或User类(Java),其中有getId(),setName(),serializeToByteArray()等方法。- 序列化:一个 C++ 程序创建一个
User对象,设置其字段;然后调用SerializeToString()。产生的二进制数据流大致是:[id的值][name的长度][name的字符][email的长度][email的字符]。- 跨语言消费:这个二进制数据可以被写入文件或通过网络发送。一个 Java 写的 MapReduce 程序读取这个二进制流,使用生成的 Java
User类中的parseFrom()方法,就能重建出内存中的User对象,并访问其id,name等字段。- 列式存储场景:如果成千上万个
User记录被以列式存储,所有id在一个数据块,所有name在另一个数据块。要处理这些数据,系统必须快速地从id块读取一个id,从name块读取对应的name,从User记录,再交给 MR 任务处理。
无损列式表示
下图中包含 Schema 和两条符合 Schema 的记录(r1和r2) 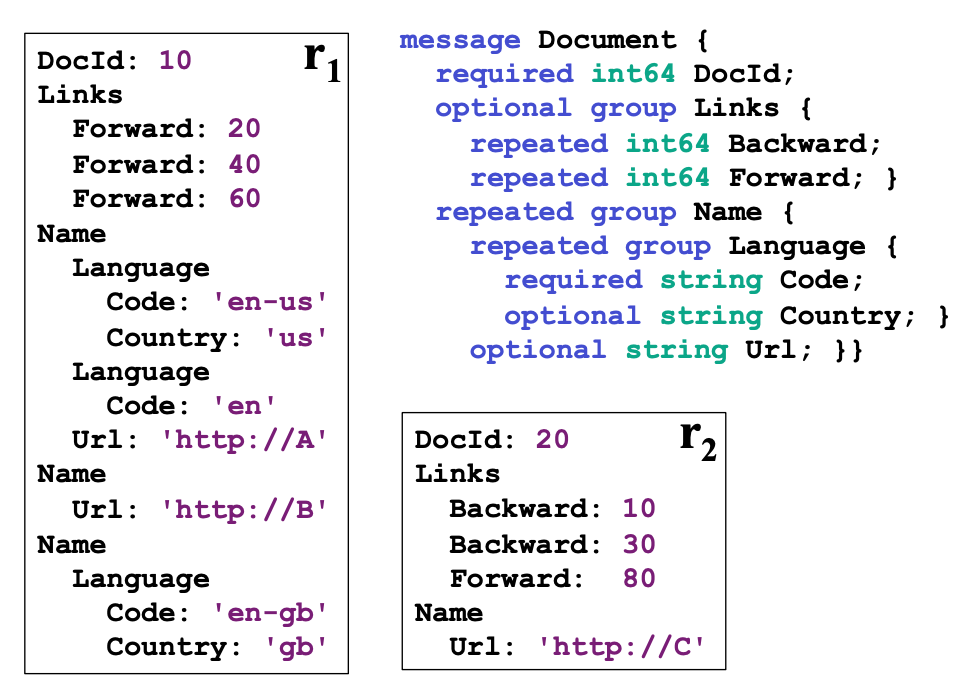
对于这种嵌套模式,如果单纯将同一字段的数据连续存储,不能确定一个数据属于哪条记录。Dremel 引入 Repetition Level 和 Definition Level 来解决。
重复级别(Repetition Level):这个值是从哪个重复节点开始的新实例?
Repetiton Level 记录该值在 full path 的哪一级重复(只有 repeated 字段会增加重复级别)。以Name.Language.Code为例,其 full path 中包含两个重复字段:Name和Language,因此Code的 Repetition Level 范围是0到2:
- 0 表示一个新行;
- 1 表示该值最近的重复级别为
Name; - 2 表示该值最近的重复级别为
Language.
对 r1标注 Repetition Level:
1 | Repetition Level |
以
Name.Language.Code的3个记录为例:
en-us:Repetition Level 是 0;en:Language字段重复,Repetition Level 是 2;en-gb:Name字段重复(Language只出现了一次),Repetition Level 是 1.
空值处理:注意到r1中的第二个Name不包含Code值。但为了表示 en-gb 是属于第三个 Name,在 Code 列中插入了一条 NULL(repetition level 为 1)。Code 在 Language 中属于 Required 字段,因此需要额外的信息来数据属于哪个级别。
定义级别(Definition Level):为了访问这个值,我们需要经过多少个可选的或重复的节点?
Definition Level 记录 full path 上的 optional 或 repeated 字段实际存在的个数;对于同列非 NULL 的所有记录,其值是相同的。
对 r1 标注 Definition Level:
1 | Repetition Level Definition Level |
Definition Level 主要对 NULL 有意义,在恢复数据的时候可以避免恢复出多余的结构。下图是 r1、r2 全量的列存结构: 
假设没有 Definition Level,尝试恢复 r1 的数据结构,会得到如下的结果:
读第一行
en-us:
2
3
4
Name
Language
code: 'en-us'读第二行
en:
2
3
4
5
6
Name
Language
code: 'en-us'
Language
code: 'en'读第三行 NULL:
2
3
4
5
6
7
8
Name
Language
code: 'en-us'
Language
code: 'en'
Name
Language读第四行 en-gb:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Name
Language
code: 'en-us'
Language
code: 'en'
Name
Language
Name
Language
code: 'en-gb'
````
可以看出第二个 `Name` 中构造出了 `Language`,这在 `r1` 中不存在。但如果有了 Definition Level,在读取第三行的时候就能知道实际只存在一个字段,也就是 `Name`,这样在构造的时候就不会构造 `Language` 结构:
读第三行 NULL:
```yaml
Document
Name
Language
code: 'en-us'
Language
code: 'en'
Name在实际的编码中会对上面的结构进行编码以减少不必要的存储空间。
快速编码
下一个挑战是:将嵌套的、重复的记录(如 JSON、Protocol Buffers)转换为扁平的 column stripes,并能在查询时重新组装。(尤其是在处理大规模稀疏数据时)
参见:The striping and assembly algorithms from the Dremel paper 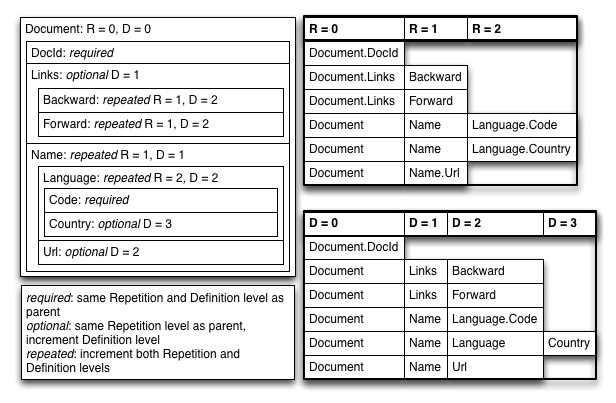
执行查询
Dremel 使用 multi-level serving tree 来执行查询,根节点接受客户端查询请求,读取 metadata 并将查询重写后分发给下一级服务器;中间节点执行与根节点类似的操作,进一步将查询分发到更下一级,并聚合来自下级的结果;叶子节点直接与存储层(如 GFS 或 Colossus)通信,或访问本地磁盘上的数据,处理之后逐级汇总到根节点。
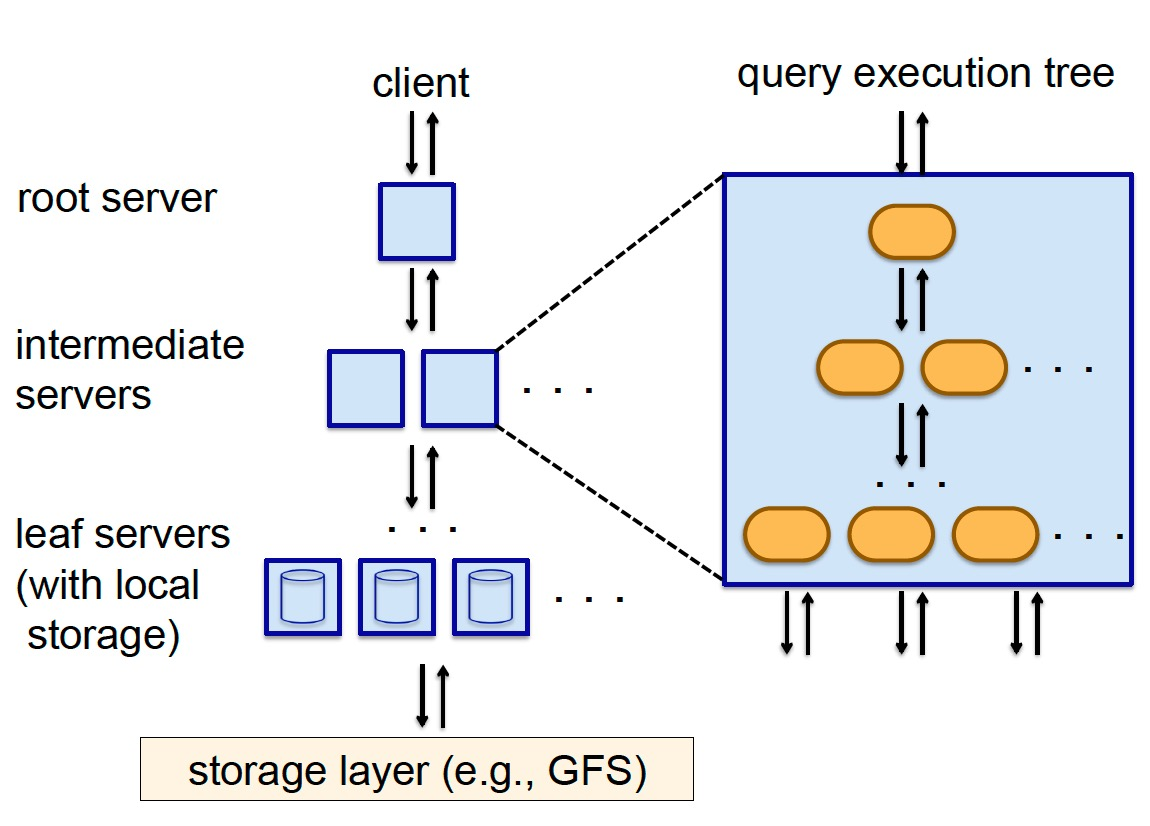
对于查询重写,举个栗子:查询
SELECT A, COUNT(B) FROM T GROUP BY A:
- 根服务器将其重写为:
其中
R1_i是来自第一级中间服务器的部分聚合结果。
- 中间服务器 (
i) 执行:
其中
T_i是分配给该服务器处理的数据分片。
- 叶子服务器 并行扫描其负责的数据分片。
Dremel 是一个多用户系统,其 query dispatcher 会根据任务优先级和负载均衡进行调度。通过设置返回结果时必须扫描 tablets 的百分比(比如 98%),牺牲一定精确性来换取性能。
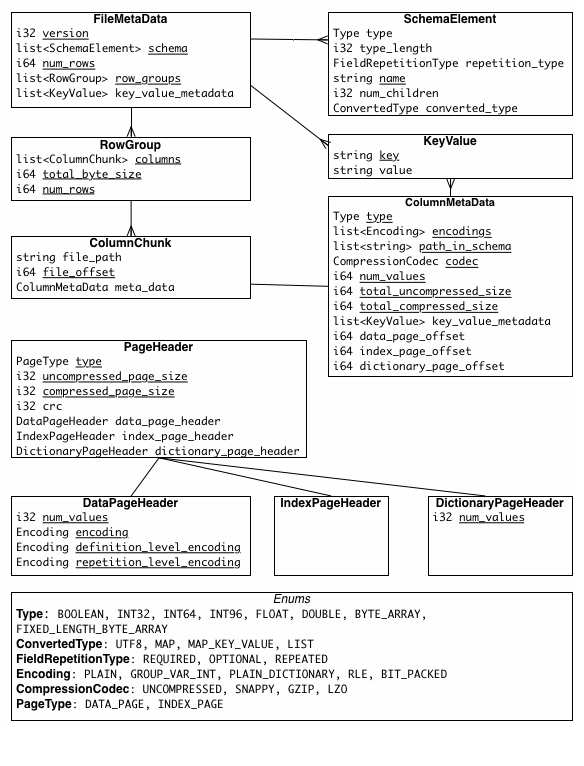
Parquet Format
https://github.com/apache/parquet-format/blob/master/src/main/thrift/parquet.thrift
Parquet 文件格式是自解析的,采用 thrift 格式定义的文件 schema 以及其他元数据信息一起存储在文件的末尾。文件 = 数据块(故事正文) + 元数据(目录) + 文件页脚(书末的目录页码)。内容如下:
1 | 4-byte magic number "PAR1" |
- 文件头(一个 4 字节的魔数 "PAR1"):作为文件的唯一标识,用于快速判断一个文件是否是合法的 Parquet 文件。
- 数据(“行组 -> 列块”):
- 行组:数据的水平分区(它是并行处理、数据跳过和谓词下推的基本单位;查询引擎可以并发地处理不同的行组)
- 列块:一个行组内,单个列的所有数据
- Metadata(紧接在最后一个数据列块之后;查询引擎在读取文件时,首先读取元数据),包含:
- 整个文件的 Schema(列名、数据类型、嵌套结构等);
- 每个行组的信息;
- 每个列块的精确起始位置(在文件中的偏移量)、压缩后的大小、未压缩的大小、编码方式、统计信息(如最小值、最大值、空值数量)等。
- 元数据长度 + 文件尾:读者可以从文件末尾向前读取 8 个字节(4字节长度 + 4字节魔数);通过魔数验证找到文件尾,然后读取元数据长度,再据此读取整个元数据块;这使得文件读取非常高效,无需扫描整个文件。

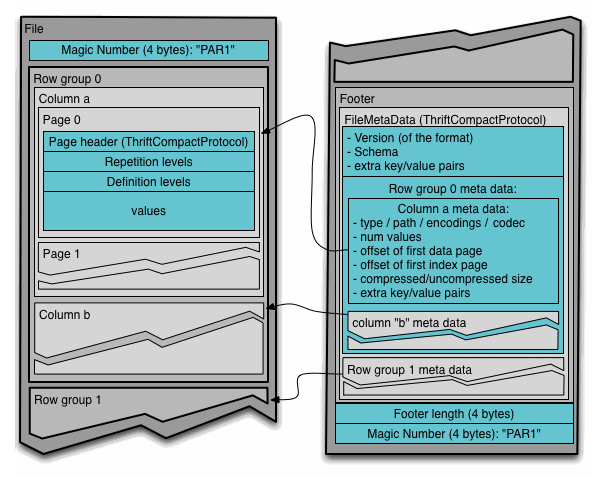
并行化执行的单元:
- MapReduce - File/Row Group(一个任务对应一个文件或一个行组)
- IO - Column chunk(任务中的 IO 以列块为单位读取)
- Encoding/Compression - Page(编码和压缩以页面为单位执行)
Parquet 推荐配置:
- 行组大小(Row group size):更大的行组允许更大的列块,这使得可以执行更大的顺序 IO;但更大的行组需要更大的写缓存。Parquet 建议使用较大的行组(512MB-1GB)。此外由于可能需要读取整个行组,因此最好一个行组能完全适配一个 HDFS Block。一个较优的读取配置为:行组大小 1GB,HDFS 块大小 1GB,每个 HDFS 文件对应 1 个 HDFS 块。
- 数据页大小(Data page size):数据页视为不可分割,因此较小的数据页可实现更细粒度的读取(例如单行查找);但较大的页面可以减少空间的开销(减少 page header 数量)和潜在的较少的解析开销(处理 headers)。Parquet 建议的页面大小为 8KB。
Parquet java 实现
https://github.com/apache/parquet-java#
Parquet 写入流程
调用链路:应用程序层 -> ParquetWriter (用户接口) -> InternalParquetRecordWriter (核心协调器) -> MessageColumnIO (记录路由) -> ColumnWriteStore (列管理) -> ColumnWriter (列写入) -> PageWriter (页面管理) -> 文件系统层
应用程序接口层:构建 ParquetWriter
1 | // 用户应用程序调用 |
传入的 Schema 结构是什么呢?
一个支持嵌套的MessageType字段(继承自GroupType),举个栗子:
1 | // 使用Types构建器创建复杂模式 |
CompressionCodecName 支持哪些压缩方式呢?
1 | public enum CompressionCodecName { |
压缩算法:
UNCOMPRESSED: 无压缩,最快读写,文件大小等于原始数据大小SNAPPY: 基于 LZ77 算法的快速压缩(2-4倍压缩比)GZIP: 基于 LZ77 和 Huffman 编码(3-10倍压缩比)ZSTD: 使用 zstd-jni 库进行底层压缩BROTLI: 通常比 GZIP 压缩率高20-26%,专为网络传输优化LZ4: 去除 Hadoop LZ4 的帧头结构
builder.build() 的构建过程是怎样的呢?
1 | public abstract static class Builder<T, SELF extends Builder<T, SELF>> { |
配置参数流转如下:用户配置层 -> Builder配置层 (withSchema, withCompressionCodec等) -> ParquetProperties层 (编码、压缩、统计等属性) -> ParquetConfiguration层 (Hadoop配置) -> CodecFactory层 (压缩编解码器管理) -> 实际写入器层 (InternalParquetRecordWriter)
核心协调器层:InternalParquetRecordWriter
核心协调器的架构如下:
1 | public class InternalParquetRecordWriter<T> { |
调用write方法:
1 | // InternalParquetRecordWriter - 核心协调器 |
写入性能优化:按行组批量写入,减少I/O次数;在行组级别压缩,提高压缩效率;支持多线程写入(通过不同的WriteSupport实例);
WriteSupport作为数据转换的抽象层,作用机制是怎样的呢?
1 | public abstract class WriteSupport<T> { |
转换流程:用户对象 (T) -> WriteSupport.write() -> RecordConsumer (Parquet 内部表示) -> ColumnWriteStore (列式存储) -> PageWriter (页面写入) -> 文件系统
看一个具体的实现栗子:GroupWriteSupport 的实现
1 | public class GroupWriteSupport extends WriteSupport<Group> { |
行组刷新策略如何实现的呢?
- 预测性刷新:在接近阈值前2个记录时刷新;
- 动态检查间隔:根据数据特征调整检查频率;
- 资源及时释放:行组刷新后立即释放相关资源。
基于双重阈值控制机制.
| 参数 | 默认值 | 作用 | 影响 |
|---|---|---|---|
| rowGroupSizeThreshold | 128MB | 行组大小限制 | 控制单个行组的最大大小 |
| rowGroupRecordCountThreshold | 2^31-1 | 记录数限制 | 防止单个行组记录数过多 |
| minRowCountForPageSizeCheck | 100 | 最小检查间隔 | 避免频繁检查内存 |
| maxRowCountForPageSizeCheck | 10000 | 最大检查间隔 | 确保及时检查内存 |
1 | private void checkBlockSizeReached() throws IOException { |
行组刷新流程如下:
1 | private void flushRowGroupToStore() throws IOException { |
记录路由层
1 | // MessageColumnIO - 记录到列的映射 |
列管理层:ColumnWriteStoreBase
ColumnWriteStoreBase负责同步多个列写入器的状态,并协调各列的刷新时机:
1 | // ColumnWriteStoreBase - 列存储管理器 |
页面大小控制策略是如何实现的呢?
| 参数 | 默认值 | 作用 | 影响 |
|---|---|---|---|
| pageSizeThreshold | 1MB | 页面大小阈值 | 控制单个页面的最大字节数 |
| pageRowCountLimit | 20,000 | 页面行数限制 | 防止单页包含过多行 |
| pageValueCountThreshold | 2^31-1 | 页面值数量限制 | 防止单页包含过多值 |
| thresholdTolerance | 10% | 阈值容忍度 | 允许页面略超阈值 |
| minRowCountForPageSizeCheck | 100 | 最小检查间隔 | 避免频繁检查 |
| maxRowCountForPageSizeCheck | 10,000 | 最大检查间隔 | 确保及时检查 |
采用三重阈值控制机制:内存大小->行数->值数量
1 | private void sizeCheck() { |
列写入层:ColumnWriterBase
每个列都有三个独立的编码流:支持延迟聚合(数据在写入时分离,在读取时重新组合成完整记录);支持每个流使用不同的编码策略以实现独立优化。
1 | // ColumnWriterBase - 列写入器基类 |
页面管理层:PageWriter
1 | // PageWriter - 页面写入器接口 |
Parquet 适用场景
Parquet 是在数据复杂性与查询性能之间的一种工程权衡。它旨在为半结构化数据提供接近纯分析模型的性能,同时避免彻底的扁平化 ETL。
优点:
- 原生处理复杂数据:直接高效存储 JSON、Protobuf 等嵌套结构,无需预先扁平化(完美契合了日志存储场景);
- 卓越查询性能与存储效率:
- 列式存储:可以只读取查询所需的“子列”,大幅减少 I/O;
- 高效压缩:同一列的数据具有更高的相似性,压缩率远高于行存(RLE、字典编码等在 Parquet 中得到了广泛应用);
- 谓词下推:利用列块的统计信息(如 min/max),在读取数据前就能跳过整个不相干的行组。
- 架构简化:允许只维护一份 “原始数据”(如嵌套的日志文件),同时服务于数据分析(OLAP)和(有限的)数据检索场景;简化了数据架构,避免了维护多份数据和复杂 ETL 管道的成本。
- 生态成熟:作为 Hadoop/Spark 生态系统的默认列式格式,被几乎所有主流数据处理框架(Presto, Hive, Impala, Flink等)深度支持。
缺点:
- 逻辑模型复杂:嵌套模型本身不利于大多数关系型查询优化,重复/定义级别的存储方案增加了复杂性;
- 写入成本高:不适合流式写入或频繁更新,是典型的批处理导向格式。
- 点查询性能差:缺乏索引,随机访问单条记录效率极低(不如数据库索引)。
| 场景 | 推荐度 | 说明 |
|---|---|---|
| 数据湖与分析 | ✅ 极度适用 | 对数仓中的原始、半结构化数据进行低成本存储和高性能即席查询 |
| 传统数仓 | ⚠️ 次优选择 | 对于高度结构化、可预定义的数据,专门的星型/雪花模型性能更佳 |
| 实时点查询 | ❌ 绝不适用 | 需要毫秒级响应的记录检索场景 |
参考
Dremel: Interactive Analysis of Web-Scale Datasets
The striping and assembly algorithms from the Dremel paper
论文阅读笔记: Dremel: Interactive Analysis of Web-Scale Datasets
