从 TCP 粘包到分帧
TCP/ IP 协议簇中:
- IP 协议解决了数据包(Packet)的路由和传输,上层的 TCP 协议无需关注路由和寻址;
- 传输层的 TCP 协议解决了数据段(Segment)的可靠性和顺序问题,上层无需关心数据能否传输到目标进程,只要写入 TCP 协议的缓冲区的数据,协议栈几乎都能保证数据的送达。
当应用层协议使用 TCP 协议传输数据时,TCP 协议可能会将应用层发送的数据分成多个包依次发送;当应用层从 TCP 缓冲区中读取数据时发现粘连的数据包时,需要对收到的数据进行拆分。
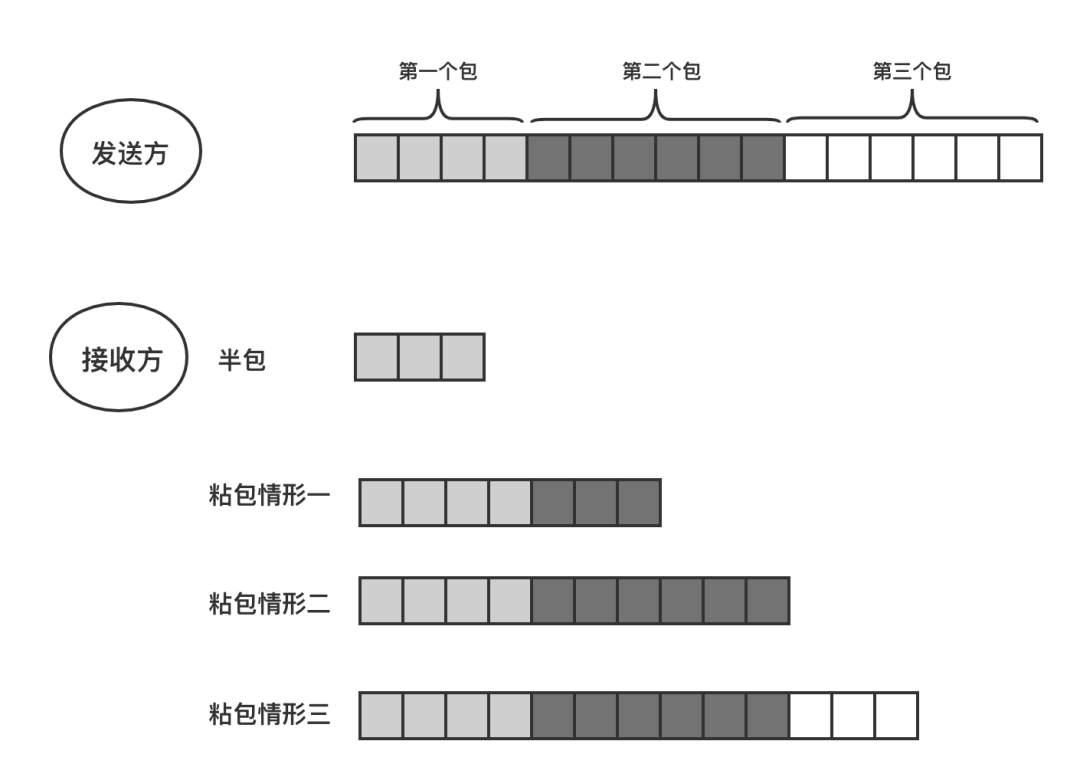
TCP 协议之所以存在所谓的"粘包"问题,本质上源于对 TCP 协议特性的误解和不当应用层协议设计。现在分析 TCP 协议中的粘包是如何发生的:
- TCP 协议是面向字节流的协议,它可能会组合或者拆分应用层协议的数据;
- 应用层协议的没有定义消息的边界导致数据的接收方无法拼接数据。
面向字节流
TCP 是一种面向字节流的传输层协议,其核心设计不包含数据包或消息的概念,而是将数据视为连续的字节流进行传输。TCP 协议本身的传输机制会对待发送数据进行组合或拆分。
Nagle 算法:TCP_NODELAY
Nagle 算法是一种通过减少数据包的方式提高 TCP 传输性能的算法。该优化机制会延迟发送小数据块,等待缓冲区中数据超过最大数据段(MSS)或者上一个数据段被 ACK 时才会发送缓冲区中的数据。 
Nagle 算法在 Linux 内核中的实现如下:
1 | static inline bool tcp_nagle_test(const struct tcp_sock *tp, const struct sk_buff *skb, |
在默认情况下,Linux 内核使用
TCP_NODELAY = 1关闭 Nagle 算法。
TCP_CORK
除了 Nagle 算法之外,TCP 协议栈中还有另一个用于延迟发送数据的选项 TCP_CORK,如果开启该选项,当发送的数据小于 MSS 时,TCP 协议会延迟 200ms 发送该数据或者等待缓冲区中的数据超过 MSS。
无论是 TCP_NODELAY 还是 TCP_CORK,都会通过延迟发送数据来提高带宽的利用率,它们会对应用层协议写入的数据进行拆分和重组,而这些机制和配置能够出现的最重要原因是:TCP 协议是基于字节流的协议,其本身没有数据包的概念,不会按照数据包发送数据。
消息边界
许多应用层协议开发者错误地认为 TCP 协议会保持消息的完整性,忽略了需要自行定义消息帧的必要性。正确的做法是:采用基于长度或基于终结符的消息边界方案。
基于长度的实现包括两种方式:
- 使用固定长度:所有的应用层消息都使用统一的大小;
- 使用不固定长度,在应用层协议的协议头中明确指定负载长度:
固定长度分帧
每个协议包的长度都是固定的。举个例子,例如我们可以规定每个协议包的大小是 64 个字节,每次收满 64 个字节,就取出来解析(如果不够,就先存起来)。
优点:协议格式简单;
缺点:灵活性差。
- 包内容不足指定的字节数:剩余的空间需要填充特殊的信息,如 \0(如果不填充特殊内容,如何区分包里面的正常内容与填充信息呢?);
- 包内容超过指定字节数:分包分片,需要增加额外处理逻辑,在发送端进行分包分片,在接收端重新组装包片。
长度前缀分帧
长度前缀分帧是指:在写入消息本身之前,写入长度信息,来表明每条消息的大小。
接下来看几个栗子:
HTTP/1.1: Content-Length
HTTP 协议使用Content-Length头表示 HTTP 消息 body 的字节数。
1 | HTTP/1.1 200 OK |
客户端读取到响应头后,发现 Content-Length: 138,它就会在接收完头部的两个CRLF()后,再读取138个字节。
HTTP/1.1 协议怎么升级到 HTTP/2 协议呢?
客户端发起一个 http URI 请求时,如果事前不知道下一跳是否支持 HTTP/2,需要使用 HTTP Upgrade 机制。客户端发起一个 HTTP/1.1 请求,其中包含 "h2c" 的 Upgrade 首部字段,该请求必须包含一个 HTTP2-Settings 首部字段。
2
3
4
5
Host: server.example.com
Connection: Upgrade, HTTP2-Settings
Upgrade: h2c
HTTP2-Settings: <base64url encoding of HTTP/2 SETTINGS payload>
如果服务器不同意升级或者不支持 Upgrade 升级,可以直接忽略,当成是 HTTP1.1 请求和响应就好了。
如果服务器同意升级,响应格式为:
2
3
4
Connection: Upgrade
Upgrade: h2c
[ HTTP/2 connection ...HTTP 响应升级的状态码是 101(Switching Protocols)。在结束 101 响应的空行后,服务端可以开始发送 HTTP2 数据帧了。
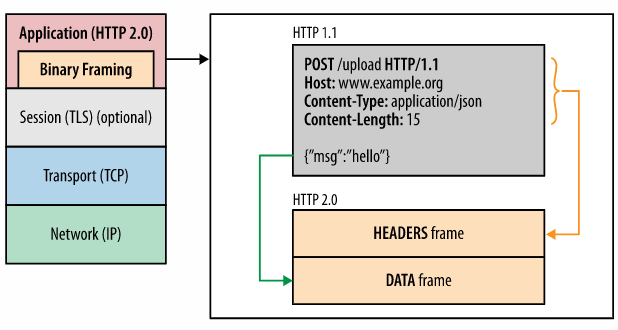
HTTP/2: Frame 帧头的 Length(定义了 Payload 的长度)
回顾一下 HTTP/2 中的几个重要概念:
- 帧 frame:HTTP/2 中最小通信数据单元,每个帧至少包含了一个标识(stream id)该帧所属的流。
- 消息 message:消息由一个或多个帧组成。
- 流 stream:存在于 HTTP2 连接中的一个“虚拟连接通道“,它是一个逻辑概念。流可以承载双向字节流,及是客户端和服务端可以进行双向通信的字节序列。每个流都有一个唯一的 stream id 标识,由发起流的一端分配给流。
单个 HTTP/2 连接可以包含多个同时打开的流,任何一个端点(客户端和服务端)都可以将多个流的消息进行传输。这也是多路复用关键所在。一个 TCP 连接里可以发送若干个流(stream),每个流中可以传输若干条消息(message),每条消息由若干二进制帧(frame)组成。
任何一端都可以关闭流。在流上发送消息的顺序很重要(特别是 HEADERS 帧和 DATA 帧的顺序在语义上非常重要),最后接收端会把 Stream id (同一个流) 相同的帧重新组装成完整的消息报文。
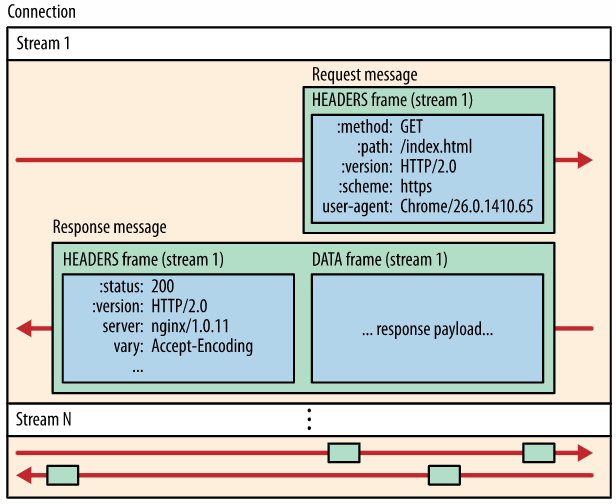 任何一端都可以关闭流。在流上发送消息的顺序很重要(特别是 HEADERS 帧和 DATA 帧的顺序在语义上非常重要),最后接收端会把 Stream id (同一个流) 相同的帧重新组装成完整的消息报文。
任何一端都可以关闭流。在流上发送消息的顺序很重要(特别是 HEADERS 帧和 DATA 帧的顺序在语义上非常重要),最后接收端会把 Stream id (同一个流) 相同的帧重新组装成完整的消息报文。所有 Frame 数据都是以一个固定的 9 字节开头(Frame Payload之前),后面跟一个可变长度的有效负载Frame Payload(这个可变长度的长度值由字段 Length 来表示)。接收方先读取9字节的帧头,解析出长度 N,然后再读取 N 字节的负载。这样就明确地分离出了一个帧。 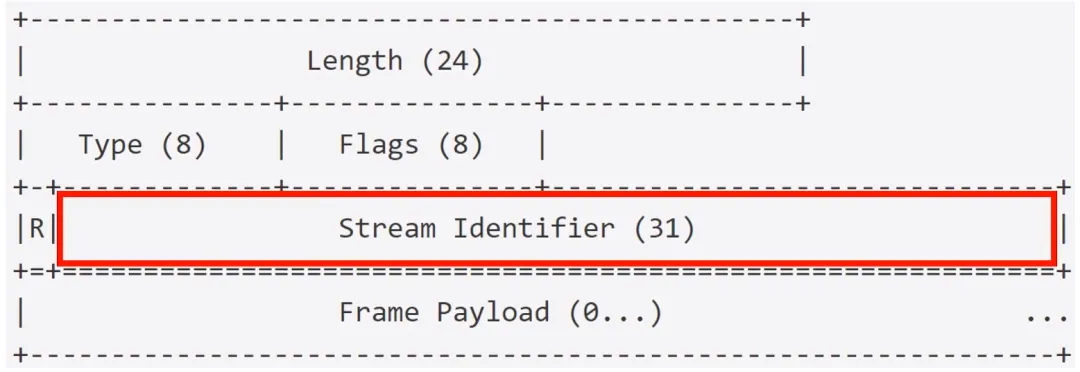
1 | HTTP Frame { |
Length:24 个 bit 的无符号整数,用来表示 Frame Payload 的长度占用字节数。这个Length值的范围为 0 - 16384(2^14)。触发接收方设置了一个更大的值SETTINGS_MAX_FRAME_SIZE。帧头的 9 字节不包含在这个Length值中。Type:定义 Frame 的类型,8 bits 表示。帧类型决定了帧的格式和语义。实现的话必须忽略或抛弃未知类型的帧。Flags:为帧 Frame 类型保留的 8 bit 的布尔值,这个标志用于特定的帧 Frame 类型语义。如果这个字段没有被标识为特定帧类型语义,那么接收时必须被忽略,并且发送时不设置(0x0)。- R(
Reserved):一个保留的 1 bit 字段,这个字段语义未定义。发送时必须保持未设置(0x0),接收时忽略。 - Stream Identifier:流标识,31 bit 的无符号整数。值 0x0 保留给与整个连接相关联的帧,而不是单个流。
- Frame Payload:内容主体,由帧的类型决定。
根据 Type 标识 10 种类型的 Frame: 
DATA Frame Payload
https://www.rfc-editor.org/rfc/rfc7540.html#section-6.1
2
3
4
5
6
7
|Pad Length? (8)|
+---------------+-----------------------------------------------+
| Data (*) ...
+---------------------------------------------------------------+
| Padding (*) ...
+---------------------------------------------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Length (24),
Type (8) = 0x00,
Unused Flags (4),
PADDED Flag (1),
Unused Flags (2),
END_STREAM Flag (1), // bit 的位 0 设置为 1,代表当前流的最后一帧
Reserved (1),
Stream Identifier (31),
[Pad Length (8)], // Padding 的长度(只有 Flags 设置为 PADDED 情况下才会出现)
Data (..), // 传递的应用程序数据
Padding (..2040), // 填充的字节
}DATA 帧的标识有:
- END_STREAM(0x01): bit 的位 0 设置为 1,代表当前流的最后一帧
- PADDED(0x08):bit 的位 3 设置为 1 代表存在 Padding
HEADERS Frame Payload
https://www.rfc-editor.org/rfc/rfc7540.html#section-6.2
2
3
4
5
6
7
8
9
10
11
|Pad Length? (8)|
+-+-------------+-----------------------------------------------+
|E| Stream Dependency? (31) |
+-+-------------+-----------------------------------------------+
| Weight? (8) |
+-+-------------+-----------------------------------------------+
| Header Block Fragment (*) ...
+---------------------------------------------------------------+
| Padding (*) ...
+---------------------------------------------------------------+
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Length (24),
Type (8) = 0x01,
Unused Flags (2),
PRIORITY Flag (1),
Unused Flag (1),
PADDED Flag (1),
END_HEADERS Flag (1),
Unused Flag (1),
END_STREAM Flag (1),
Reserved (1),
Stream Identifier (31),
[Pad Length (8)],
[Exclusive (1)],
[Stream Dependency (31)],
[Weight (8)],
Field Block Fragment (..),
Padding (..2040),
}HEADERS 帧的标识有:
END_STREAM(0x01):bit 的位 0 设置为 1,表示当前 header 块发送的最后一块,但是带有END_STREAM标识的 HEADERS 帧后面还可以跟 CONTINUATION 帧 (这里可以把 CONTINUATION 看作 HEADERS 的一部分)END_HEADERS(0x04):bit 的位 2 设置为 1,表示此帧包含整个字段块,并且后面没有 CONTINUATION 帧。没有设置 END_HEADERS 标识的 HEADERS 帧必须跟在同一流的 CONTINUATION 帧之后。PADDED(0x08):bit 的位 3 设置为 1,PADDED 设置后表示 Pad Length 字段以及它描述的 Padding 是存在的。PRIORITY(0x20):bit 的位 5 设置为 1,表示存在 Exclusive Flag (E), Stream Dependency 和 Weight 3 个字段。
gRPC
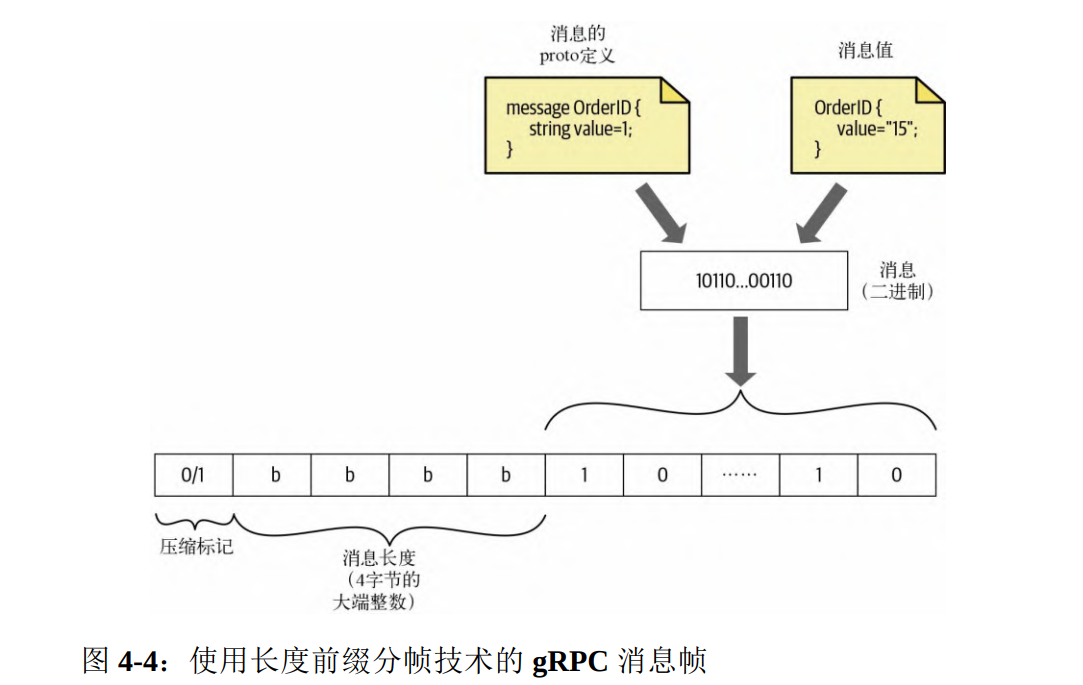
在 gRPC 通信中,每条消息都有额外的 4 字节用来设置其大小,也意味着 gRPC 通信可以处理大小不超过 4GB 的所有消息。
在收件方一侧,当收到消息之后,首先要读取其第一字节,来检查该消息是否经过压缩;然后,收件方读取接下来的 4 字节,以获取编码二进制消息的大小,接着就可以从流中精确地读取确切长度的字节了。
消息大小的生成方式:当消息使用 protocol buffers 编码时,会得到二进制格式的消息;然后,计算二进制内容的大小,并以大端格式将其添加到二进制内容的前面。
目前,gRPC 核心支持 3 种传输实现:HTTP/2、Cronet 和进程内(in process)。在这 3 种实现中,最常见的是 HTTP/2。
其他例子:Nito.Async.Sockets.SocketPacketProtocol
来看一个基于长度分帧策略实现的协议例子:Nito.Async.Sockets.SocketPacketProtocol
分帧策略:[4字节长度前缀] + [实际数据]
- 例子:消息 "Hello" 的传输格式:[0x05 0x00 0x00 0x00] + [0x48 0x65 0x6C 0x6C 0x6F]
协议使用两阶段状态机:接收长度前缀->接收消息数据
安全特性:防止负数长度攻击;防止超大消息 DoS 攻击;协议违规检测
1 | public class PacketProtocol |
终结符分帧
字节流中遇到特殊的符号值时,就认为到一个包的末尾了。例如:FTP 协议、发邮件的 SMTP 协议,一个命令或者一段数据后面加上""(即 CRLF)表示一个包的结束。对端收到后,每遇到一个”“就把之前的数据当做一个数据包。
注意:如果协议数据包内容部分需要使用包结束标志字符,则需要对这些字符做转码或者转义操作,以免被接收方错误地当成包结束标志而误解析。
HTTP/1.1(使用分块传输编码 Transfer-Encoding: chunked)
当响应体的长度未知时(例如动态生成的内容),HTTP 使用分块传输。每个块包含一个十六进制的块大小(以 CRLF 结尾)、数据块本身,以及另一个 CRLF。
整个消息使用负载大小为 0 的 HTTP 消息作为终结符表示消息的边界。(HTTP 头中不再包含 Content-Length)
1 | HTTP/1.1 200 OK |
这里的终结符是 0。客户端解析到 0 就知道后续没有数据块了。注意:每个块内部是使用长度分帧的,但整个消息的结束是使用终结符。
Redis 序列化协议 RESP
为了与 Redis 服务器通信,Redis 客户端使用一种称为 Redis 序列化协议(RESP)的协议:客户端创建一个 TCP 连接到 Redis 服务器的端口(默认是 6379),将请求以字符串数组的形式发送到 Redis 服务器(数组的内容是服务器应执行的命令及其参数);服务器处理命令并将回复发送回客户端。
RESP 是二进制安全协议,控制序列使用标准 ASCII 编码。例如,字符 A 用二进制字节 65 编码。类似地,字符 CR (、LF () 和 SP () 的二进制字节值分别为 13、10 和 32。
(CRLF)是协议的终止分隔符。
注意:RESP 仅用于客户端-服务器通信;Redis 集群用于节点之间交换消息时使用不同的二进制协议。
解包
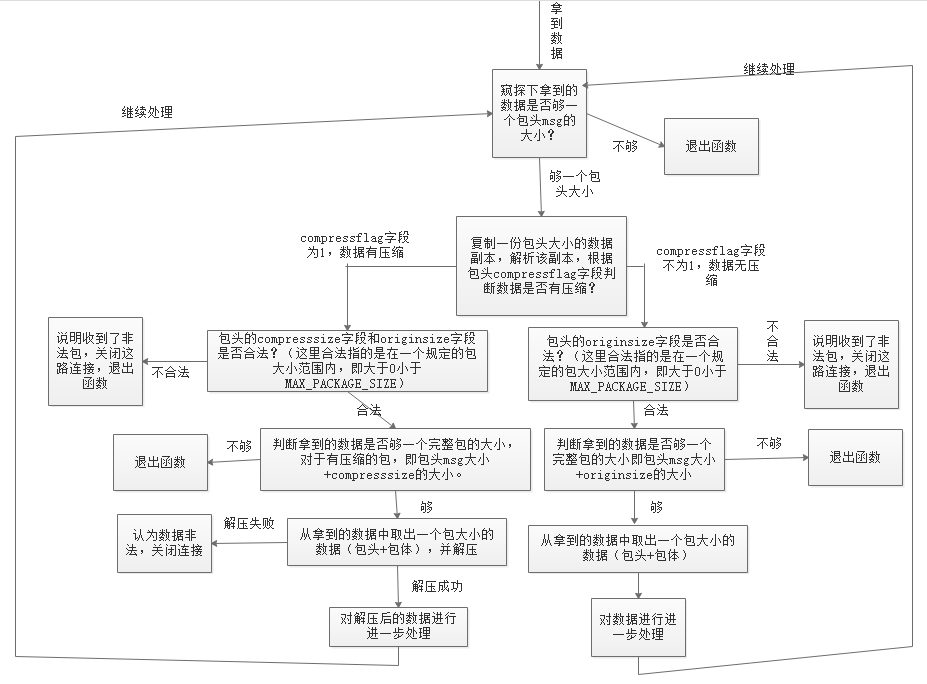
假设包头如下:
1 | #pragma pack(push, 1) |
编写解包逻辑时需考虑以下几个要点:
- 使用
peek查看缓冲区而非直接取出:使用peek()方法查看数据而不移除;只有确认完整包到达时,才一次性移除整个包的数据,防止因包体不完整而需要将包头重新放回缓冲区的低效操作。 - 严格的包体大小校验:校验 bodysize 必须处于合理区间(如 0-10MB);防范恶意客户端发送超大包耗尽服务器内存,并且应对网络丢包或解析错误导致的数据错位。
- 循环处理粘包:使用 while 循环确保单次数据到达能处理多个完整包;防止因等待新数据而延误已到达包的处理;一次性处理所有就绪包,提高吞吐量。
代码如下:
1 | //包最大字节数限制为10M |
