RL 系列:5. 从 TRPO 到 PPO 算法
上一篇记录了策略梯度算法的目标:通过梯度上升的方法执行策略更新,目标是最大化期望奖励,数学形式为:
\[ \nabla\overline{R_\theta}=\mathbb{E}_{\tau\sim p_\theta(\tau)}[R(\tau)\nabla\log p_\theta(\tau)] \]
由于策略梯度算法是 on-policy 的,因此要求行为策略\(\mu\)和目标策略\(\pi_\theta\)相同。每次将策略\(\theta\)更新为\(\theta'\)时,来源于上一轮采样数据的概率\(p_\theta(\tau)\)不能再使用,需要重新采样;这说明 on-policy 算法每次采样的数据在更新参数时只能使用一次。耗时巨大。能不能转为 off-policy 算法呢?
一个想法是使用冻结的策略\(\pi_{\theta'}\)专门与环境交互,使用\(\theta'\)采样的数据训练优化目标\(\pi_\theta\). 引入重要性采样(importance sampling)的概念。
重要性采样
“采样是概率密度函数的逆向应用。”对于具备分布\(p\) 的随机变量\(x\),可以通过从\(p\)中采样若干数据\(x^i\)后代入\(f(x)\),用于近似\(\mathbb{E}[f(x)]\).
可不可以通过从分布\(q\)中采样的数据\(x^i\),计算符合分布\(p\)的\(\mathbb{E}[f(x)]\)呢?(on-policy 转向 off-policy)有:
\[ \mathbb{E}_{x\sim p}[f(x)]=\int f(x)p(x)dx=\int f(x)\frac{p(x)}{q(x)}q(x)dx=\mathbb{E}_{x\sim q}[f(x)\frac{p(x)}{q(x)}] \]
上式通过 重要性权重\(\frac{p(x)}{q(x)}\) 修正两个分布的差异。
虽然上式左右两端的期望值在数学上等价,但是方差随着\(p\)和\(q\)的差异而变化。有:
\[ Var_{x\sim p}[f(x)]=\mathbb{E}_{x\sim p}[f(x)^2]-(\mathbb{E}_{x\sim p}[f(x)])^2 \]
\[ \begin{align*} Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]&=\mathbb{E}_{x\sim q}[(f(x)\frac{p(x)}{q(x)})^2]-(\mathbb{E}_{x\sim q}[f(x)\frac{p(x)}{q(x)}])^2 \\ &=\mathbb{E}_{x\sim p}[f(x)^2\frac{p(x)}{q(x)}]-(\mathbb{E}_{x\sim p}[f(x)])^2 \end{align*} \]
\(Var_{x\sim p}[f(x)]\) 和 \(Var_{x\sim q}[f(x)\frac{p(x)}{q(x)}]\)的差异在于第一项:如果\(\frac{p(x)}{q(x)}\)的差距较大,则方差较大;当采样次数不足够多时,可能得到差距非常大的结果,此时该近似方法不准确。
使用重要性采样将 on-policy 算法改为 off-policy.
假设有另外一个 Actor 采用策略\(\pi_{\theta'}\)做采样,有:
\[ \nabla\overline{R_\theta}=\mathbb{E}_{\tau\sim p_\theta'(\tau)}[\frac{p_\theta(\tau)}{p_\theta'(\tau)}R(\tau)\nabla\log p_\theta(\tau)] \]
重要性权重为\(\frac{p_\theta(\tau)}{p_\theta'(\tau)}\). 采用\(\theta'\)与环境交互采样大量的数据,用于更新\(\theta\).
优势函数
价值函数\(V_{\pi_\theta}(s)\) 的含义为:在某个状态\(s\)一直与环境交互直至游戏结束的期望奖励。有:
\[ R(\theta)=\mathbb{E}[V_{\pi_\theta}(s_0)]=\mathbb{E}_{\pi_\theta}[\sum_{t=0}^\infty\gamma^t r(s_t, a_t)] \]
在策略\(\pi_\theta\)下的优化目标写成在\(\pi_{\theta'}\)下的形式(初始状态\(s_0\)的分布与策略无关):
\[ \begin{align*} R(\theta)&=\mathbb{E}[V_{\pi_\theta}(s_0)] \\ &=\mathbb{E}_{\pi_{\theta'}}[\sum_{t=0}^\infty\gamma^t V_{\pi_\theta}(s_t)-\sum_{t=1}^\infty\gamma^t V_{\pi_\theta}(s_t)] \\ &=-\mathbb{E}_{\pi_{\theta'}}[\sum_{t=0}^\infty\gamma^t(\gamma V_{\pi_\theta}(s_{t+1})-V_{\pi_\theta}(s_t))] \end{align*} \]
策略\(\theta\)和\(\theta'\)的目标函数差距为:
\[ \begin{align*} R(\theta')-R(\theta)&=\mathbb{E}[V_{\pi_\theta'}(s_0)]-\mathbb{E}[V_{\pi_\theta}(s_0)] \\ &=\mathbb{E}_{\pi_\theta'}[\sum_{t=0}^\infty\gamma^t r(s_t, a_t)]+\mathbb{E}_{\pi_{\theta'}}[\sum_{t=0}^\infty\gamma^t(\gamma V_{\pi_\theta}(s_{t+1})-V_{\pi_\theta}(s_t))] \\ &=\mathbb{E}_{\pi_\theta'}[\sum_{t=0}^\infty\gamma^t[r(s_t, a_t)+\gamma V_{\pi_\theta}(s_{t+1})-V_{\pi_\theta}(s_t)]] \end{align*} \]
当前状态-动作对的优势函数(Advantage)\(A^\theta(s_t, a_t)\) 定义为:
\[ A=r(s_t, a_t)+\gamma V_{\pi_\theta}(s_{t+1})-V_{\pi_\theta}(s_t) \]
这一项为时序差分残差,使用累积奖励减去 baseline,用于估测:在状态\(s_t\)采取动作\(a_t\)的优劣。
梯度更新过程为:
\[ \mathbb{E}_{(s_t, a_t)\sim\pi_\theta}[A^\theta(s_t, a_t)\nabla\log p_\theta(a_t^n|s_t^n)] \]
如果\(A^\theta(s_t, a_t)\)为正,增加概率;反之则降低概率。
使用重要性采样技术将 on-policy 转为 off-policy 时:
\[ \mathbb{E}_{(s_t, a_t)\sim\pi_\theta'}[\frac{p_\theta(s_t, a_t)}{p_{\theta'}(s_t, a_t)}A^\theta(s_t, a_t)\nabla\log p_\theta(a_t^n|s_t^n)] \]
这里采用\(A^{\theta'}(s_t, a_t)\)近似\(A^{\theta}(s_t, a_t)\).
继续转化为:
\[ \mathbb{E}_{(s_t, a_t)\sim\pi_\theta'}[\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}\frac{p_\theta(s_t)}{p_{\theta'}(s_t)}A^{\theta'}(s_t, a_t)\nabla\log p_\theta(a_t^n|s_t^n)] \]
这里采用\(p_{\theta'}(s_t)\)近似\(p_\theta(s_t)\).
从以上梯度更新的公式反推待优化的目标函数:
\[ R^{\theta'}(\theta)=\mathbb{E}_{(s_t, a_t)\sim\pi_{\theta'}}[\frac{p_\theta(a_t|s_t)}{p_{\theta'}(a_t|s_t)}A^{\theta'}(s_t, a_t)] \]
其含义为:使用\(\theta'\)与环境交互,采样得到\(s_t\), \(a_t\),计算优势\(A^{\theta}(s_t, a_t)\);最后用于更新\(\theta\).
也即:
\[ R^{\theta'}(\theta)=\mathbb{E}_{s\sim\nu^{\pi_{\theta'}}}\mathbb{E}_{a\sim\pi_{\theta'}(·|s)}[\frac{\pi_{\theta}(a|s)}{\pi_{\theta'}(a|s)}A^{\pi_{\theta'}}(s, a)] \]
广义优势估计(GAE)
优势函数衡量某个动作相对于其他动作的好坏程度,即:在某个状态下采取某个动作,是否比策略中其他动作表现地更好。通常定义为:
\[ A(s, a)=Q(s, a)-V(s) \]
采用蒙特卡洛方法估计优势:采样完整轨迹,利用从状态\(s\) 到结束的总回报\(R(s,a)\)进行无偏估计,即:
\[ A(s, a)=R(s, a)-V(s) \]
方差大,单次采样容易受到偶然因素的影响。
采用时序差分方法估计优势:采用一步/多步预测估计,即:
\[ A(s, a)=r+\gamma V(s')-V(s) \]
其中\(V(s')\)是下一个状态\(s'\)的价值。方差小(依赖多个小步骤的估计),偏差大(使用估计的价值函数更新)
广义优势估计(GAE)同时结合蒙特卡洛和时序差分,引入一个混合系数\(\lambda\)在方差和偏差之间灵活调节。GAE 的核心思想是:利用多个 TD 步骤的加权和估计优势。定义为:
\[ A_t^{GAE}=\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l} \]
其中,\(\delta_t=r_t+\gamma V(s_{t+1})-V(s_t)\)是时序差分误差。当\(\lambda=1\)时,退化为蒙特卡洛,方差较大但无偏;当\(\lambda=0\)时,退化为时序差分,偏差大但方差小。
根据多步时序差分思想,有:
\[ \begin{align*} A_t^{(1)}=\delta_t &=-V(s_t)+r_t+\gamma V(s_{t+1}) \\ A_t^{(2)}=\delta_t+\gamma\delta_{t+1} &=-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 V(s_{t+2}) \\ A_t^{(2)}=\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2} &=-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2r_{t+2}+ \gamma^3V(s_{t+3}) \\ A_t^{(k)}=\sum_{l=0}^{k-1}\gamma^l\delta_{t+l} &=-V(s_t)+r_t+\gamma r_{t+1}+...+\gamma^{k-1}r_{t+k-1}+\gamma^k V(s_{t+k}) \end{align*} \]
将不同步数的优势估计进行指数加权平均:
\[ \begin{align*} A_t^{GAE}&=(1-\lambda)(A_t^{(1)}+\lambda A_t^{(2)}+\lambda^2 A_t^{(3)}+...) \\ &=(1-\lambda)(\delta_t+\lambda(\delta_t+\gamma\delta_{t+1})+\lambda^2(\delta_t+\gamma\delta_{t+1}+\gamma^2\delta_{t+2})...) \\ &=(1-\lambda)(\delta_t(1+\lambda+\lambda^2+...)+\gamma\delta_{t+1}(\lambda+\lambda^2+\lambda^3+...)+\gamma^2\delta_{t+2}(\lambda^2+\lambda^3+\lambda^4+...)) \\ &=(1-\lambda)(\delta_t\frac{1}{1-\lambda}+\gamma\delta_{t+1}\frac{\lambda}{1-\lambda}+\gamma^2\delta_{t+2}\frac{\lambda^2}{1-\lambda}+...) \\ &=\sum_{l=0}^\infty(\gamma\lambda)^l\delta_{t+l} \end{align*} \]
当\(\lambda=0\)时,\(A_t^{GAE}=\delta_t=r_t+\gamma V(s_{t+1})-V(s_t)\),只看一步差分;当\(\lambda=1\)时,\(A_t^{GAE}=\sum_{l=0}^\infty\gamma^l\delta_{t+l}=\sum_{l=0}^\infty\gamma^lr_{t+l}-V(s_t)\),看每一步差分的完全平均值。
KL 散度
回到重要性采样谈到的一个观点:使用\(\theta'\)近似\(\theta\)时,其分布不宜相差太多;这里意为:最新策略\(\pi_\theta\) 不宜离采样策略\(\pi_{\theta'}\)太远,否则影响重要性采样的拟合效果。因此需要在训练时加一个约束项。
TRPO 采用 KL 散度衡量策略之间的距离,整体优化公式为:
\[ \max_{\theta}R^{\theta'}(\theta) \\ s.t. \\ \mathbb{E}_{s\sim\nu^{\pi_{\theta_k}}}[D_{KL}(\pi_{\theta_k}(·|s), \pi_{\theta}(·|s))]\leq \delta \]
其中,\(\nu^{\pi}(s)=(1-\gamma)\sum_{t=0}^\infty\gamma^t P_t^\pi(s)\)是状态分布的定义。
上述优化目标中的 KL 约束定义了策略空间中的一个 KL 球,称为信任区域。
近似求解:
假设\(\theta_k\)为第\(k\)次迭代后的目标策略。对目标函数和 KL 约束分别在\(\theta_k\)处执行泰勒展开,分别使用一阶、二阶近似:
\[ R^{\theta'}(\theta)\approx g^T(\theta-\theta_k) \\ \mathbb{E}_{s\sim\nu^{\pi_{\theta_k}}}[D_{KL}(\pi_{\theta_k}(·|s), \pi_{\theta}(·|s))]\approx \frac{1}{2}(\theta-\theta_k)^T H(\theta-\theta_k) \]
其中:\(g=\nabla_{\theta}\mathbb{E}_{s\sim\nu^{\pi_{\theta_k}}}\mathbb{E}_{a\sim\pi_{\theta_k}(·|s)}[\frac{\pi_{\theta}(a|s)}{\pi_{\theta_k}(a|s)}A^{\pi_{\theta_k}}(s, a)]\),即目标函数的梯度;\(H=\bold{H}[\mathbb{E}_{s\sim\nu^{\pi_{\theta_k}}}[D_{KL}(\pi_{\theta_k}(·|s), \pi_{\theta}(·|s))]]\)表示策略之间平均 KL 距离的黑塞矩阵。
优化目标转为: \[ \theta_{k+1}=\argmax_{\theta}g^T(\theta-\theta_k) \\ s.t. \\ \frac{1}{2}(\theta-\theta_k)^T H(\theta-\theta_k)\leq\delta \]
可以用 KKT 条件直接导出上述问题的解。
TRPO 的约束并不好处理。如果放在目标函数中呢?这就是 PPO.
\[ R_{PPO}^{\theta'}(\theta)=R^{\theta'}(\theta)-\beta KL(\theta, \theta') \]
注意:这里的\(KL(\theta, \theta')\)并非参数上的距离,而是行为上的距离(给定相同状态,输出动作的差距)
PPO
PPO-penalty
对于 off-policy 策略,使用\(\theta_k\)采样一次得到的数据,多次用于目标策略\(\theta\)的更新。即:
\[ R_{PPO}^{\theta_k}(\theta)=R^{\theta_k}(\theta)-\beta KL(\theta, \theta_k) \]
采用自适应 KL 散度(动态调整\(\beta\))。假设优化完成后, KL 散度值太大,说明惩罚项\(\beta KL(\theta, \theta_k)\)没有发挥作用,应该增大\(\beta\);如果优化后 KL 散度值太小,说明惩罚项太强,应该减小\(\beta\).即:
- 如果 \(KL(\theta, \theta_k)>KL_{max}\),增大\(\beta\);
- 如果 \(KL(\theta, \theta_k)<KL_{min}\),减小\(\beta\).
优化目标为:
\[ R_{PPO}^{\theta_k}=R_{PPO}^{\theta}-\beta KL(\theta, \theta_k) \\ R^{\theta_k}(\theta)\approx\sum_{(s_t, a_t)}\frac{p_\theta(a_t|s_t)}{p_{\theta_k}(a_t|s_t)}A^{\theta_k}(s_t, a_t) \]
PPO-clip
计算 KL 散度太复杂,目标函数改写为:
\[ R_{PPO}^{\theta_k}(\theta)\approx\sum_{(s_t, a_t)}\min(\frac{p_\theta(a_t|s_t)}{p_{\theta_k}(a_t|s_t)}A^{\theta_k}(s_t, a_t), clip(\frac{p_\theta(a_t|s_t)}{p_{\theta_k}(a_t|s_t)}, 1-\epsilon, 1+\epsilon)A^{\theta_k}(s_t, a_t)) \]
clip 的意义是使得\(p_\theta(a_t|s_t)\)与\(p_{\theta_k}(a_t|s_t)\)尽可能接近,优化后差距不太大。
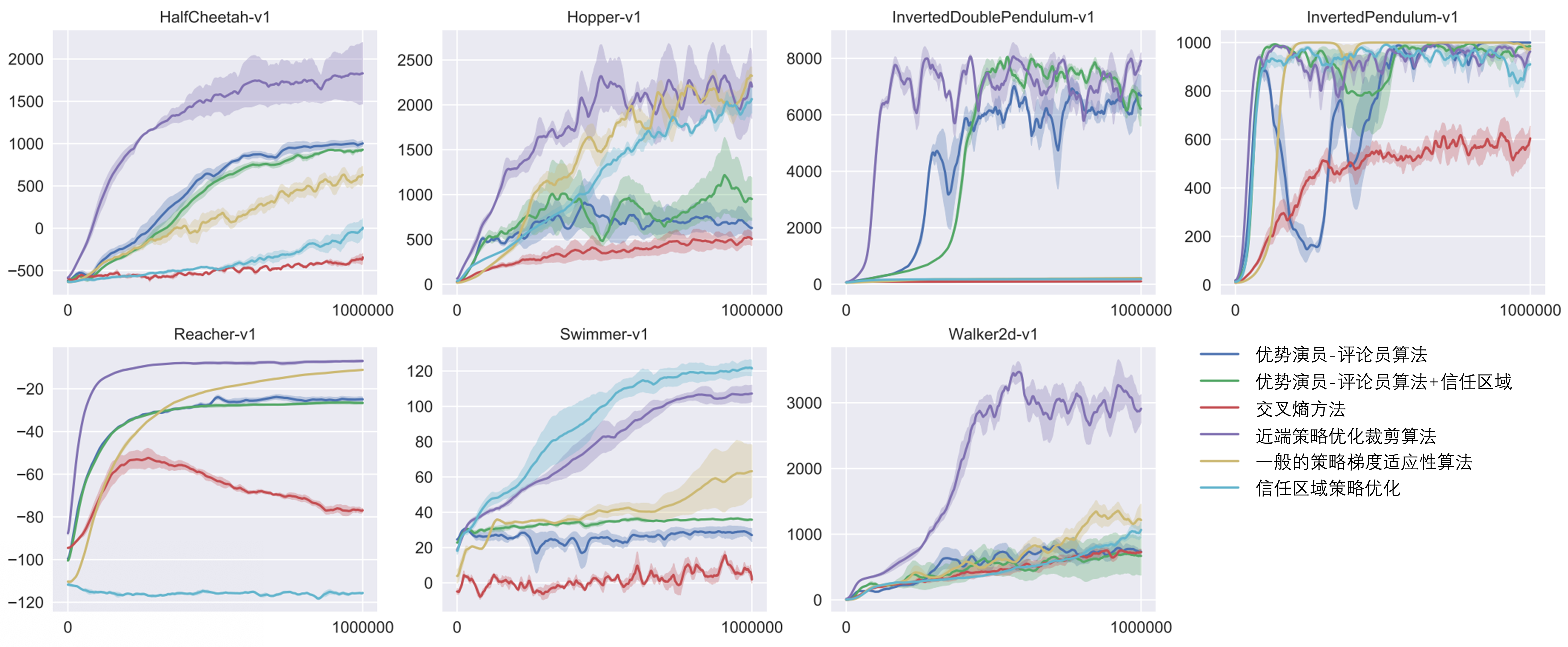 如上图,在大多数 RL 任务中,PPO 算法效果较好。
如上图,在大多数 RL 任务中,PPO 算法效果较好。
