VLM-R1源码解析
VLM-R1基于TRL框架。
GROP方法
GRPO 是一种在线学习算法,它通过使用训练模型本身在训练期间生成的数据进行迭代改进。其理念是:最大程度利用生成补全,同时确保模型始终接近参考策略。
分为4个步骤:生成补全、计算奖励、估计KL散度、计算损失。 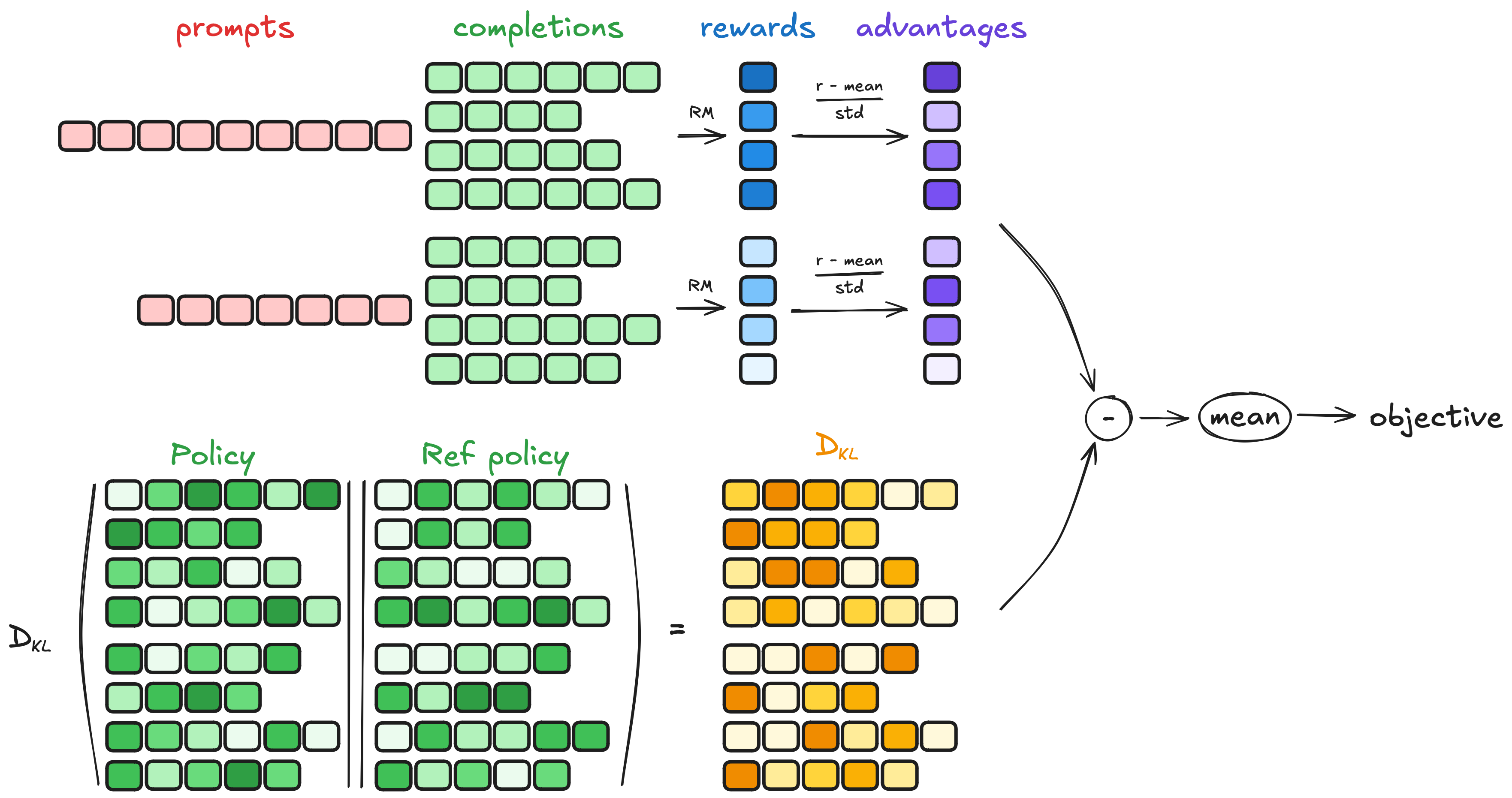
要点
引入critic:使用预测baseline改进奖励
使用绝对奖励,单纯比较大小,会导致:奖励波动大,以及对部分改进的激励不足;因此引入Critic:使用“预测baseline”来改进奖励
对于给定状态(\(s_t\))和动作(\(o_t\)),该baseline为价值函数\((V_\psi(s))\);训练目标由单纯的reward,转为超过该baseline的程度,由优势函数表示为: \[ A_t=r_t-V_\psi(s_t) \] 即训练中优化内容为: \[ \mathcal{J}_{adv}(\theta)=\mathbb{E}[A(o)] \\ where A(o)=r(o)-V_\psi(o) \] 通过减去baseline,降低了训练中的方差,为超出预期的动作提供更高的梯度信号;并对未达标的动作进行惩罚。
添加裁剪和最小值操作:防止过度更新
适度控制学习策略的更新程度:若单次更新太多,则可能走向极端值;若单次更新太少,则动力不足。应找到一个平衡点。
在Proximal Policy Optimization (PPO)中最大化以下目标函数: \[ \mathcal{J}_{adv}(\theta)=\mathbb{E}[q\sim P(Q), o\sim\pi_{\theta_{old}}(O|q)]\frac{1}{|o|}\sum_{t=1}^{|o|}\min[r_t(\theta)A_t, clip(r_t(\theta),1-\epsilon,1+\epsilon)A_t] \] 其中: \[ r_t(\theta)=\frac{\pi_{\theta}(o_t|q,o_{<t})}{\pi_{\theta_{old}}(o_t|q,o_{<t})} \] \(\pi_{\theta}\)和\(\pi_{\theta_{old}}\)分别是:当前策略模型、旧策略模型;\(q\)和\(o\)是从问题数据集和旧策略\(\pi_{\theta_{old}}\)中采样的问题和输出;超参数\(\epsilon\)用于稳定训练过程;优势\(A_i\)通过广义优势估计(GAE)计算。
防止作弊和极端策略:使用KL散度
如果只专注于最大化目标函数,可能会采用可疑手段,即生成有害或虚假内容,以人为提高某些奖励指标。为了减轻对奖励模型的过度优化,标准方法是:在每个标记的奖励中,添加一个来自参考模型(初始策略)的每个标记的KL惩罚,即: \[ r_t=r_\varphi(q,o_{\leq t})-\beta\log\frac{\pi_\theta(o_t|q,o_{<t})}{\pi_{ref}(o_t|q,o_{<t})} \] 其中,\(r\)是奖励模型,\(\pi_{ref}\)是参考模型,通常是初始的监督微调(SFT)模型,而\(\beta\)是KL惩罚项的系数。
然而,PPO 中的Critic(值函数)通常是一个与Actor(策略模型)大小相当的模型,这带来了显著的内存和计算负担;此外,在 LLMs 的上下文中,Critic在训练过程中被用作优势计算中的Baseline,但通常只有最后一个 token 会被奖励模型赋予奖励分数,这可能使得Critic的训练变得复杂。
为了解决这些问题,提出了 Group Relative Policy Optimization (GRPO),不再需要像PPO那样加入额外的Critic近似,而是直接使用多个采样输出的平均奖励作为Baseline,显著减少了训练资源的使用。
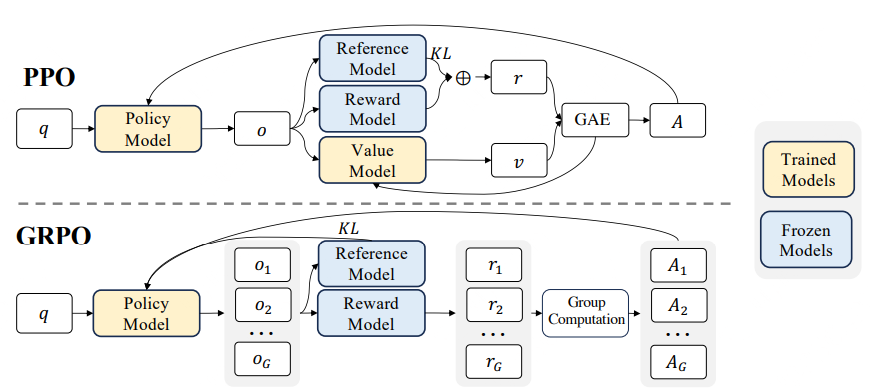
对于每个问题\(i\),GRPO从旧策略\(\pi_{\theta_{old}}\)中,采样出一组输出{\(i_1\),...,\(i_A\)},通过最大化以下目标函数优化策略模型: 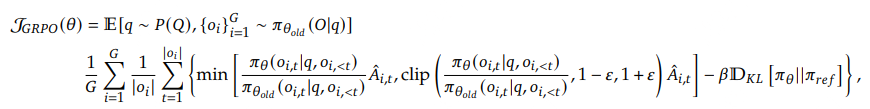
其中,\(\epsilon\) 和 \(\beta\) 是超参数,\(\hat{A}_{i,t}\) 是基于组内奖励的相对优势估计。
与 PPO 不同,GRPO: 1. 直接使用奖励模型的输出来估计baseline,避免了训练一个复杂的Critic; 2. 直接在损失函数中加入策略模型和参考模型之间的 KL 散度来正则化,而不是在奖励中加入 KL 惩罚项,从而简化了训练过程。

使用下面的无偏估计来估计 KL 散度: 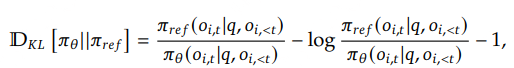
GRPO核心思想: 1. 无需为 Critic 设置单独的价值网络; 2. 对同一问题或状态,从旧策略中采样多个输出; 3. 将这些输出的平均奖励视为基准; 4. 任何高于平均值的都产生“正优势”,任何低于平均值的都产生“负优势”。
同时,GRPO保留了 PPO 的裁剪和 KL 机制,以确保稳定、合规的更新。
自定义训练器VLMGRPOTrainer
基于 Trainer 类扩展,实现了 Group Relative Policy Optimization (GRPO) 方法的训练,该方法首次在论文DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models中提出。
初始化
默认:
2
torch_dtype: str = "bfloat16",
加载预训练模型:
1
2model_cls = self.vlm_module.get_model_class(model_id, model_init_kwargs)
model = model_cls.from_pretrained(model_id, **model_init_kwargs)PEFT配置:如果提供了 PEFT 配置,查找模型中的所有线性层(不包括视觉模块),并将它们应用于 LoRA微调。
1
2
3
4if peft_config is not None:
target_modules = find_all_linear_names(model, self.vision_modules_keywords)
peft_config.target_modules = target_modules
model = get_peft_model(model, peft_config)
寻找Pytorch中的线性层:
2
3
4
5
6
7
8
9
10
11
12
13
cls = torch.nn.Linear
lora_module_names = set()
for name, module in model.named_modules():
# 不在视觉模块上应用LoRA微调
if any(mm_keyword in name for mm_keyword in multimodal_keywords):
continue
if isinstance(module, cls): # 检查是否为线性层(全连接层)
lora_module_names.add(name)
for m in lora_module_names: # 移除嵌入层
if "embed_tokens" in m:
lora_module_names.remove(m)
return list(lora_module_names)
冻结视觉模块:如果
freeze_vision_modules为True,冻结所有视觉模块的参数,不进行梯度更新;启用梯度检查点(如果需要):在反向传播时,仅存储部分中间激活值,来减少训练过程中对内存的需求。
1
2if args.gradient_checkpointing:
model = self._enable_gradient_checkpointing(model, args)
看看启用梯度检查点的函数:_enable_gradient_checkpointing
1 | def _enable_gradient_checkpointing(self, model: PreTrainedModel, args: GRPOConfig) -> PreTrainedModel: |
- 加载参考模型:
1
2
3
4
5
6
7
8
9if is_deepspeed_zero3_enabled():
self.ref_model = model_cls.from_pretrained(model_id, **model_init_kwargs)
elif peft_config is None: # 不使用PEFT配置,从初始模型创建一个参考模型
# If PEFT configuration is not provided, create a reference model based on the initial model.
self.ref_model = create_reference_model(model)
else:
# If PEFT is used, the reference model is not needed since the adapter can be disabled
# to revert to the initial model.
self.ref_model = None
create_reference_model在TRL框架中定义:创建一个静态的参考模型(参考模型是原始模型的副本),其部分参数被冻结,以便在训练过程中不再更新。
冻结参数: * 冻结所有参数:如果没有指定共享层数(
num_shared_layers为None),则函数会冻结所有的参数。这意味着参考模型的所有参数都不会在训练中被更新,通常这种方法用于构建一个固定的基准模型或用于知识蒸馏等场景。 * 冻结部分参数(共享层):如果指定了num_shared_layers,则函数会根据该值冻结模型的前几个层(根据层数或指定的层名模式)。这意味着这些层的参数不会更新,从而让模型只对后面的层进行训练。
我们一起看看:trl/trl/models /modeling_base.py
1 | def create_reference_model( |
- 处理类(
processing_class)初始化:
如果
processing_class参数为空:从vlm_module模块中获取相应的处理类,并从预训练模型中加载。随后,处理类根据
kwargs设置自定义的处理关键词:- 如果该处理类有 tokenizer,则设置其填充和结束标记 ID;
- 否则进行类型检查,确保该处理类是
PreTrainedTokenizerBase类型。
- 对主模型、参考模型进行初始化:
Qwen2VLModule无需处理;InvernVLModule需要从模型中提取并赋值到当前对象中,并且将图像上下文的 token ID 处理并存储到模型。1
2self.vlm_module.post_model_init(model, processing_class)
self.vlm_module.post_model_init(self.ref_model, processing_class)
奖励函数
reward_funcs,奖励处理类reward_processing_classes初始化处理奖励函数的 Tokenizer
1
2
3
4
5
6
7
8
9
10for i, (reward_processing_class, reward_func) in enumerate(zip(reward_processing_classes, reward_funcs)):
if isinstance(reward_func, PreTrainedModel):
if reward_processing_class is None:
reward_processing_class = AutoTokenizer.from_pretrained(reward_func.config._name_or_path)
if reward_processing_class.pad_token_id is None:
reward_processing_class.pad_token = reward_processing_class.eos_token
# 计算输入序列中:最新non-padded token的奖励
reward_func.config.pad_token_id = reward_processing_class.pad_token_id
reward_processing_classes[i] = reward_processing_class
self.reward_processing_classes = reward_processing_classes训练参数的初始化:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25self.max_prompt_length = args.max_prompt_length
self.max_prompt_length = None
if args.max_prompt_length is not None:
warnings.warn("Setting max_prompt_length is currently not supported, it has been set to None")
self.max_completion_length = args.max_completion_length # = |o_i| in the GRPO paper
self.num_generations = args.num_generations # = G in the GRPO paper
self.generation_config = GenerationConfig(
max_new_tokens=self.max_completion_length,
do_sample=True,
temperature=1,
pad_token_id=pad_token_id,
)
if hasattr(self.vlm_module, "get_eos_token_id"): # For InternVL
self.generation_config.eos_token_id = self.vlm_module.get_eos_token_id(processing_class)
print(222, self.vlm_module.get_eos_token_id(processing_class))
self.beta = args.beta
self.epsilon = args.
# 多步
self.num_iterations = args.num_iterations # = 𝜇 in the GRPO paper
# 迭代步数(前向+反向传播)
self._step = 0
# _buffered_inputs缓存批次中的输入,避免重复生成
self._buffered_inputs = [None] * args.gradient_accumulation_steps设置随机种子
初始化参考模型
ref_model准备奖励函数
训练过程
从脚本grpo_rec.sh开始:
1 | torchrun --nproc_per_node="8" \ // 每个节点上运行的进程数:使用的 GPU 数量 |
grpo_rec.py入口函数:
加载VLM模型:
vlm_module_cls = get_vlm_module(model_args.model_name_or_path),支持:Qwen2VLModule和InvernVLModule加载奖励函数:
1
2
3
4reward_funcs_registry = {
"accuracy": vlm_module_cls.iou_reward,
"format": vlm_module_cls.format_reward_rec,
}
检查模型输出格式:
format_reward_rec* 检查是否包含think和answer标签; *answer标签中内容符合一个特定的边界框格式(如[x, y, w, h]); * 符合格式的输出奖励为 1.0,不符合格式的输出奖励为 0.0.
2
3
4
5
6
import re
pattern = r"<think>.*?</think>\s*<answer>.*?\{.*\[\d+,\s*\d+,\s*\d+,\s*\d+\].*\}.*?</answer>"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.search(pattern, content, re.DOTALL) is not None for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]
- 加载数据集:
LazySupervisedDataset(符合Pytorch格式)
数据应为.yaml文件,文件内容包含一个 datasets 字段,其中列出了多个数据源的路径以及相应的采样策略,示例如下:
1 | datasets: |
一共支持3种采样策略:
- "first":取前 sampling_number 个样本;
- "end":取最后 sampling_number 个样本;
- "random":随机打乱数据并取前 sampling_number 个样本。
奖励函数:iou_reward
Qwen2VLModule的reward
计算预测的边界框与真实边界框之间的IoU奖励:比较预测的边界框和真实边界框的重叠部分(交集)与它们的并集的比值
IOU函数定义:inter为交集面积;union为并集面积;比值为IOU1
2
3
4
5
6
7
8
9
10
11def iou(box1, box2):
inter_x1 = max(box1[0], box2[0])
inter_y1 = max(box1[1], box2[1])
inter_x2 = min(box1[2]-1, box2[2]-1)
inter_y2 = min(box1[3]-1, box2[3]-1)
if inter_x1 < inter_x2 and inter_y1 < inter_y2:
inter = (inter_x2-inter_x1+1)*(inter_y2-inter_y1+1)
else:
inter = 0
union = (box1[2]-box1[0])*(box1[3]-box1[1]) + (box2[2]-box2[0])*(box2[3]-box2[1]) - inter
return float(inter)/union主要逻辑:遍历每个预测值,提取出边界框,计算预测和真实边界框的 IoU 值作为奖励
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# 从 completions 中提取出每个预测结果的 content 字段
contents = [completion[0]["content"] for completion in completions]
rewards = [] # 存储每个预测的奖励值(IoU 值)
current_time = datetime.now().strftime("%d-%H-%M-%S-%f")
answer_tag_pattern = r'<answer>(.*?)</answer>'
bbox_pattern = r'\[(\d+),\s*(\d+),\s*(\d+),\s*(\d+)]'
for content, sol in zip(contents, solution):
reward = 0.0
try:
# content_answer_match:查找 <answer>...</answer> 标签,并提取其中的答案
content_answer_match = re.search(answer_tag_pattern, content, re.DOTALL)
if content_answer_match:
content_answer = content_answer_match.group(1).strip()
# bbox_match:在答案中提取边界框,使用正则表达式 [x1, y1, x2, y2]
bbox_match = re.search(bbox_pattern, content_answer)
if bbox_match:
bbox = [int(bbox_match.group(1)), int(bbox_match.group(2)), int(bbox_match.group(3)), int(bbox_match.group(4))]
# if iou(bbox, sol) > 0.5:
# reward = 1.0
# reward = iou(bbox, sol):计算预测的边界框 bbox 和真实边界框 sol 之间的 IoU 值,作为奖励
reward = iou(bbox, sol)
except Exception:
pass
rewards.append(reward)
if os.getenv("DEBUG_MODE") == "true":
log_path = os.getenv("LOG_PATH")
# local_rank = int(os.getenv("LOCAL_RANK", 0))
with open(log_path, "a", encoding='utf-8') as f:
f.write(f"------------- {current_time} Accuracy reward: {reward} -------------\n")
f.write(f"Content: {content}\n")
f.write(f"Solution: {sol}\n")
GRPO Config参数
数据预处理参数
remove_unused_columns (Optional[bool]):如果设置为True,则仅保留数据集中的 "prompt" 列,默认值为False。用于计算自定义奖励函数;max_prompt_length (Optional[int]): prompt 的最大长度,默认值为512(如果 prompt 长度超过此值,将会从左侧进行截断)num_generations (Optional[int]):每个 prompt 生成的样本数量。全局批次大小(num_processes * per_device_batch_size)必须能被此值整除,默认值为8;temperature (Optional[float]):采样的温度值。温度越高,生成样本的随机性越高,默认值为0.9;max_completion_length (Optional[int]):生成的完成部分的最大长度,默认值为256;ds3_gather_for_generation (bool):针对 DeepSpeed ZeRO-3 的设置。启用时,生成时会收集策略模型的权重,提升生成速度;如果禁用此选项,能够训练超过单个 GPU VRAM 容量的模型,但生成速度会更慢,并且与 vLLM 生成不兼容。默认值为True。
生成加速相关参数(vLLM)
use_vllm (Optional[bool]):是否使用 vLLM(一个用于生成的加速库)进行生成,如果设置为True,则需要确保有一个 GPU 用于生成,而不是训练;默认为Falsevllm_device (Optional[str]):指定 vLLM 生成将运行的设备,例如 "cuda:1"。如果设置为 "auto"(默认值),系统会自动选择下一个可用的 GPU;vllm_gpu_memory_utilization (float):该值指定要为 vLLM 生成预留的 GPU 内存比例。数值范围为 0 到 1,较高的数值会增加 KV 缓存大小,从而提高模型的吞吐量,但如果过高,可能会导致内存不足(OOM)错误。默认值为0.9;vllm_dtype (Optional[str]):设置 vLLM 生成的数值类型。如果设置为 "auto",将基于模型配置自动选择数据类型;vllm_max_model_len (Optional[int]):设置 vLLM 使用的最大模型长度。这对于减少vllm_gpu_memory_utilization的情况下,可能会减少 KV 缓存大小。如果未设置,vLLM 将使用模型的上下文大小;vllm_enable_prefix_caching (Optional[bool]):是否启用 vLLM 中的前缀缓存。若为True(默认),确保模型和硬件支持此功能;vllm_guided_decoding_regex (Optional[str]):用于 vLLM 指导解码的正则表达式。如果为None(默认),则禁用指导解码。
训练控制参数
learning_rate (float):初始学习率,使用 AdamW 优化器。默认值为1e-6,它替换了transformers.TrainingArguments中的默认学习率;beta (float):KL 系数。值为0.0时,参考模型不会加载,从而减少内存使用和提高训练速度。默认值为0.04;num_iterations (int):每个批次的迭代次数(在算法中表示为\(\mu\))。默认值为 1;epsilon (float):用于裁剪的 epsilon 值。默认值为0.2;reward_weights (Optional[list[float]]):每个奖励函数的权重。如果为None,则所有奖励函数的权重均为1.0,默认值为None;sync_ref_model (bool):是否每ref_model_sync_steps步同步参考模型和活动模型,使用ref_model_mixup_alpha参数进行混合。默认值为False;ref_model_mixup_alpha (float):参考模型更新时的 \(\alpha\) 参数,控制当前策略和前一个参考策略之间的混合。默认值为0.6。此参数必须与sync_ref_model=True一起使用;ref_model_sync_steps (int):确定当前策略与参考策略同步的频率,单位为步数。默认值为512,此参数必须与sync_ref_model=True一起使用。
大规模GRPO:在多个节点上训练 70B+ 模型
在训练 Qwen2.5-72B 等大型模型时,需要进行几项关键优化,以提高训练效率并在多个 GPU 和节点之间扩展。包括: ### DeepSpeed ZeRO 第 3 阶段 利用数据并行性,在多个 GPU 和 CPU 之间分配模型状态(权重、梯度、优化器状态)
