C++泛型算法
本篇隶属C++ Primer中C++标准库专题,当前关注范型算法。
标准库容器只定义了很少的操作;因此提供了一组范型算法,其中大多数独立于特定的容器,具备通用性。
范型算法
概述
大多数算法在头文件algorithm中;头文件numeric中定义了一组数值范型算法。
范型算法本身不会执行容器的操作;只会运行于迭代器之上,执行迭代器的操作。
只读算法
只读取输入范围的元素,从不改变元素
find
1 | int val=42; |
find前两个参数:表示元素范围的迭代器;第三个参数:一个值。将范围中每个元素与给定值比较:- 返回指向第一个等于给定值元素的迭代器;
- 若范围内无匹配元素,返回第二个参数,表示搜索失败。
accumulate
1 | int sum=accumulate(vec.cbegin(), vec.cend(), 0); // 将sum设置为:vec中元素之和 |
第三个参数指定保存和的对象类型,在该类型上必须定义了"+"运算符
1
2// 错误:const char*上没有定义+
string sum=accumulate(v.cbegin(),v.end(),"");
equal
1 | euqal(roster1.cbegin(), roster1.cend(), rster2.cbegin()); |
equal确定两个序列是否保存相同的值(三个参数均为迭代器):前两个表示第一个序列中的元素范围;第三个表示第二个序列的首元素- 假设:第二个序列的长度,不小于第一个序列
两个序列中元素类型,不要求严格匹配:构成两个序列的元素,可来自不同容器(例:第一个序列保存在
vector中;第二个序列保存在deque中)
写容器元素的算法
要求:序列原大小不小于要写入的元素数目。
算法不执行容器操作,因此不改变容器大小。
算法不检查写操作:例如
fill_n假定写入操作安全,没有检查vec是否为空1
2vector<int> vec; // 空vector
fill_n(vec.begin(), vec.size(), 0); // 未定义操作
back_inserter:插入迭代器
定义在头文件iterator中。
通过此迭代器添加元素时,会调用push_back将一个具备给定值的元素添加到容器中。
1 | vector<int> vec; // 空vector |
Copy:拷贝算法
1 | int a1[]={0,1,2,3,4}; |
- 返回值
ret指向拷贝到a2尾元素之后的位置
1 | replace(lst.begin(), lst.end(), 0, 42); // 将所有值为0的元素,替换为42 |
重排容器元素的算法
消除重复元素:unique
1 | sort(words.begin(), words.end()); |
标准库算法对迭代器操作,不对容器操作;因此无法添加、删除元素。
删除元素:erase
定制操作
sort算法默认使用元素类型的<运算符。
向算法传递函数:使用谓词
标准库算法使用两类谓词:一元谓词(接受单一参数)、二元谓词(接受两个参数)。
1 | bool isShorter(const string &s1, const string &s2){ |
lambda表达式
一个lambda表达式表示:一个可调用的代码单元,可理解为:一个未命名的内联函数。一个lambda具有:一个返回类型、一个参数列表、一个函数体,可定义在函数内部。形式如下:
1 | [capture list](parameter list) -> return type {function body} |
- 捕获列表(capture list):使用的所在函数中的局部变量
若lambda函数体包含任何单一return语句之外的内容,且未指定返回类型,则返回void.
向lambda传递参数
lambda不能有默认参数;其调用的实参数目永远与形参数目相等。
调用find_if
1 | auto wc=find_if(words.begin(), words.end(), [sz](const string &a{return a.size()>=sz;})); |
for_each算法
1 | for_each(wc, words.end(), [](cosnt string &s){cout<<s<<" ";}); |
lambda捕获和返回
捕获列表只用于局部非static变量;lambda可直接使用局部static变量,和所在函数之外声明的名字。
当定义一个lambda时,编译器生成一个与lambda对应的新的(未命名的)类类型,以及该类型的一个对象。
值捕获
- 前提:变量可拷贝,被捕获的变量的值在lambda创建时拷贝,不是调用时拷贝
1 | void fcn(){ |
引用捕获
在lambda函数体中使用捕获变量时,使用的是引用绑定的对象。
用引用方式捕获变量时,必须保证:lambda执行时,引用所指的对象存在。
1 | void fcn2(){ |
隐式捕获
- 指示编译器:&表示引用捕获,=表示值捕获
1 | void biggies(vector<string>& words, vector<string>::size_type sz, ostream &os=cout, char c=' '){ |

可变lambda
值捕获:默认情况下,对于一个值被拷贝的变量,lambda内不改变其值;若要改变被捕获变量的值,须在参数列表首加关键字mutable:
1 | void fcn3(){ |
引用捕获:传递非const类型
指定lambda返回类型
默认情况下,若lambda体包含return之外的任何语句,编译器假定其返回void。
1 | transform(vi.begin(), vi.end(), vi.begin(), |
参数绑定
若lambda的捕获列表为空,可以使用函数替代;
若lambda的捕获列表非空,用函数替换不方便(要捕获局部变量)
bind函数
头文件functional中定义函数bind:一个通用的函数适配器,接受一个可调用对象,生成一个新的可调用对象以适应原对象的参数列表。
1 | auto newCallable=bind(callable, arg_list); |
1 | auto g=bind(f, a, b, _2, c, _1); |
例子:
1 | // 按单词长度从短到长排序:调用isShorter(A, B) |
引用参数无法拷贝,应使用
ref1
2
3
4
5
6
7
8
9
10for_each(words.begin(), words.end(), [&os, c](const string &s){os<<s<<c;});
// 要替换以上lambda,编写一个相同功能的函数:
ostream &print(ostream &os, const string &s, char c){
return os<<s<<c;
}
// 错误:bind不能拷贝引用参数os
for_each(words.begin(),words.end(),bind(print, os, _1, ' '));
// 正确:使用ref函数,ref返回一个对象,包含给定的引用
for_each(words.begin(),words.end(),bind(print,ref(os),_1, ' '));
迭代器
iterator中定义了以下迭代器:
- 插入迭代器:绑定到一个容器上,用于向容器中插入元素;
- 流迭代器:绑定到输入/输出流上,用于遍历关联的IO流;
- 反向迭代器:向后移动,除了forward_list外都有反向迭代器;
- 移动迭代器
插入迭代器:back_inserter,front_inserter,inserter
接受一个容器,生成一个迭代器,实现:向给定容器中添加元素。

三种类型,区别在于元素插入的位置:
back_inserter:创建一个使用push_back的迭代器;front_inserter:创建一个使用push_front的迭代器;inserter:创建一个使用insert的迭代器;1
2
3
4
5
6
7
8
9
10
11
12// it是由inserter生成的迭代器
*it=val;
// 以上等价于:
it=c.insert(it, val); // it指向新插入的元素
++it; // 指向原元素
list<int> lst={1,2,3,4};
list<int> lst2, lst3; // 空lst
// 拷贝后:lst2包含4,3,2,1
copy(lst.cbegin(), lst.cend(), front_inserter(lst2));
// 拷贝后:lst3包含4,3,2,1
copy(lst.cbegin(), lst.cend(), inserter(lst3, lst.begin()));
流迭代器:istream_iterator,ostream_iterator
读取输入流:istream_iterator
1 | issteram_iterator<int> in_iter(cin), eof; // in_iter绑定至输入流cin,eof为默认初始化的尾后迭代器 |

istream_iterator允许lazy求值:绑定后,不保证立即从流中读取数据,可推迟;保证的是:在第一次解引用迭代器之前,从流中读取数据已完成
写入输出流:ostream_iterator

1 | ostream_iterator<int> out_iter(cout, " "); |
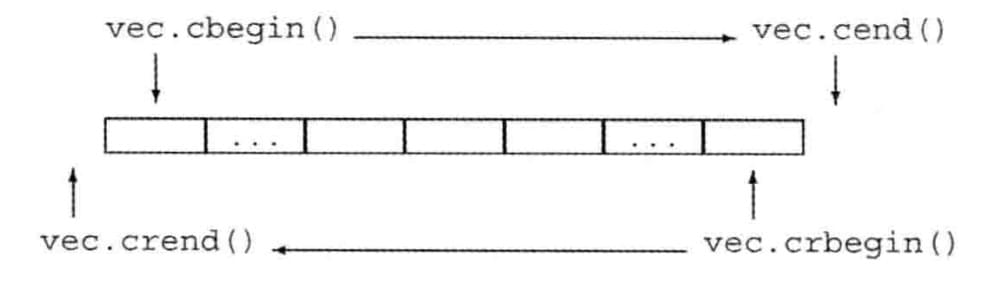
反向迭代器
在容器中,从尾元素向首元素反向移动的迭代器(除了forward_list外,其他容器都支持)
1 | sort(vec.begin(), vec.end()); // 升序排序 |
- 只能从同时支持++和--的迭代器定义反向迭代器:forward_list和流迭代器不行,因为不支持--
范型算法结构
5类迭代器

输入迭代器:可读取序列中的元素,必须支持:
- 比较运算符:==, !=
- 前置/后置递增运算符:++
- 解引用运算符*(读取元素):只出现在赋值运算符右侧
- 箭头运算符,等价于(*it).member
只能用于单遍扫描,
find和accumulate支持输入迭代器;istream_iterator是输入迭代器输出迭代器:只写不读元素,必须支持:
- 前置/后置递增运算符:++
- 解引用运算符*(写入元素):只出现在赋值运算符左侧
只能用于单遍扫描,
copy支持输入迭代器;ostream_iterator是输入迭代器随机访问迭代器:提供在常量时间内访问序列中任意元素的能力,支持双向迭代器的所有功能,必须支持:
- 比较相对位置的关系运算符:<, <=, >, >=
- 和整数值的加减运算,前进/后退给定整数个元素的位置:+, +=, -, -=
- 迭代器的-:两个迭代器距离
- 下标运算符:iter[n]
sort要求随机访问迭代器
算法形参模式

- 接受单个目标迭代器的算法:
- 假定:目标空间足够容纳写入的数据
- 接受第二个输入序列的算法:
- 假定:
beg2开始的序列,与beg和end所表示的范围至少一样大
- 假定:
算法命名规范
使用重载形式,传递一个谓词
1 | unique(beg, end); // 使用==运算比较元素 |
_if版本
1 | find(beg, end, val); // 查找范围中val第一次出现的位置 |
拷贝&不拷贝版本
1 | reverse(beg, end); // 反转后,写回给定的输入序列 |
特定容器算法


splice成员
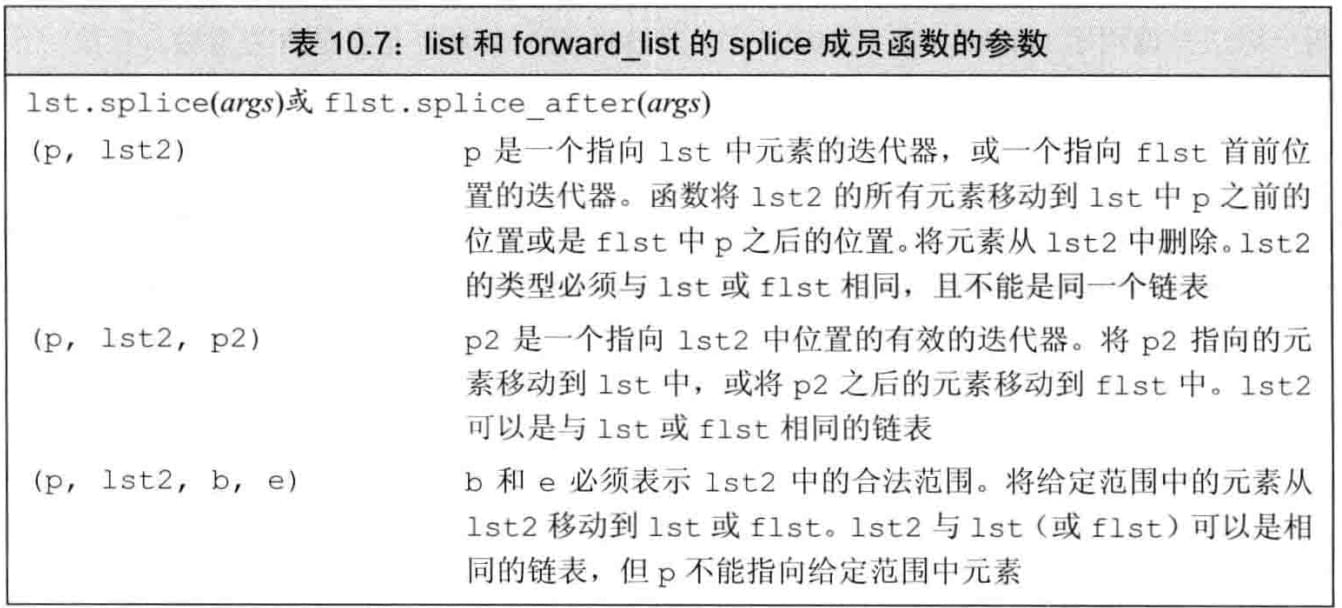
- 链表特有版本与通用版本的区别:链表版本改变底层的容器
例:通用版merge不改变两个原有输入参数序列;链表版merge销毁给定链表
