并行训练系列:1. Overview
该篇摘自The Ultra-Scale Playbook: Training LLMs on GPU Clusters.
在单个GPU上训练
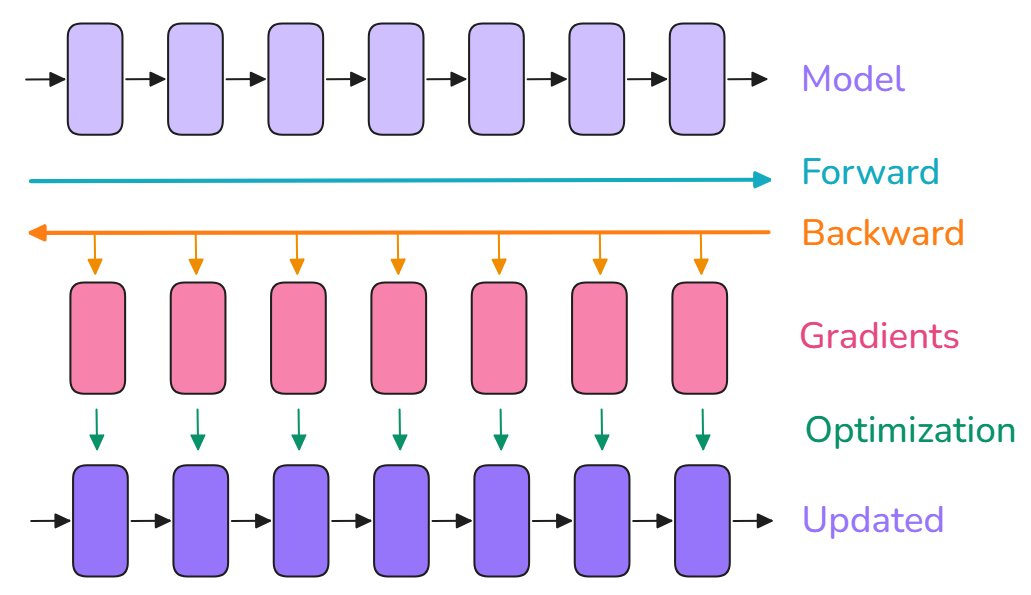
在单个GPU上训练,通常包括三个步骤: 1. forward pass:将输入传入模型,产生输出; 2. backward pass:计算梯度; 3. optimization:使用梯度更新参数。
batch size的影响
超参数batch size:小的batch size在训练初期有助于快速完成训练过程,达到一个较优learning point;但在训练后期,小的batch size导致梯度噪声增大,模型难以收敛至最优性能点;大的batch size虽然能给出精确的梯度估计,但会降低每个训练样本的利用效率,从而导致收敛变慢,并可能浪费计算资源。
batch size影响在给定dataset上的训练时间:小的batch size在相同数量样本上,需要更多的优化步骤(优化步骤是计算密集型的,导致训练时间比大的batch size更长)。但是,batch size大小通常可以在最优值附近大幅调整,而不会对模型的最终性能产生重大影响(前提是在最优值附近)。
在LLM的预训练中,batch size通常定义为:token的数量(bst:Batch Size Tokens),使得训练次数和训练中使用的输入序列长度基本独立。在单个机器上训练,bs(样本计数)和bst(token计数)可由下计算: \[ bst=bs * seq \] 其中,seq为输入序列长度。
近期 LLM 训练的理想批量大小通常在每批次 400 万到 6000 万个 token 之间。批量大小和训练语料库的规模近年来一直在稳步增加:Llama 1 的训练使用了大约 400 万个 token 的批量大小,训练了 1.4 万亿个 tokens,而 DeepSeek 则使用了大约 6000 万个 token 的批量大小,训练了 14 万亿个 tokens。
然而,一个挑战是在将模型训练扩展到大的batch size时,将遇到显存不足的问题:当 GPU 的显存不足以容纳目标batch size的完整批次时,该怎么办?
Transformer上的内存使用
当训练一个神经网络时,将以下内容存储在内存中:模型权重、模型梯度、优化器状态、(用于计算梯度的)激活值。
以上内容作为tensor(张量)存储在内存中,分别对应不同的shapes和precisions。
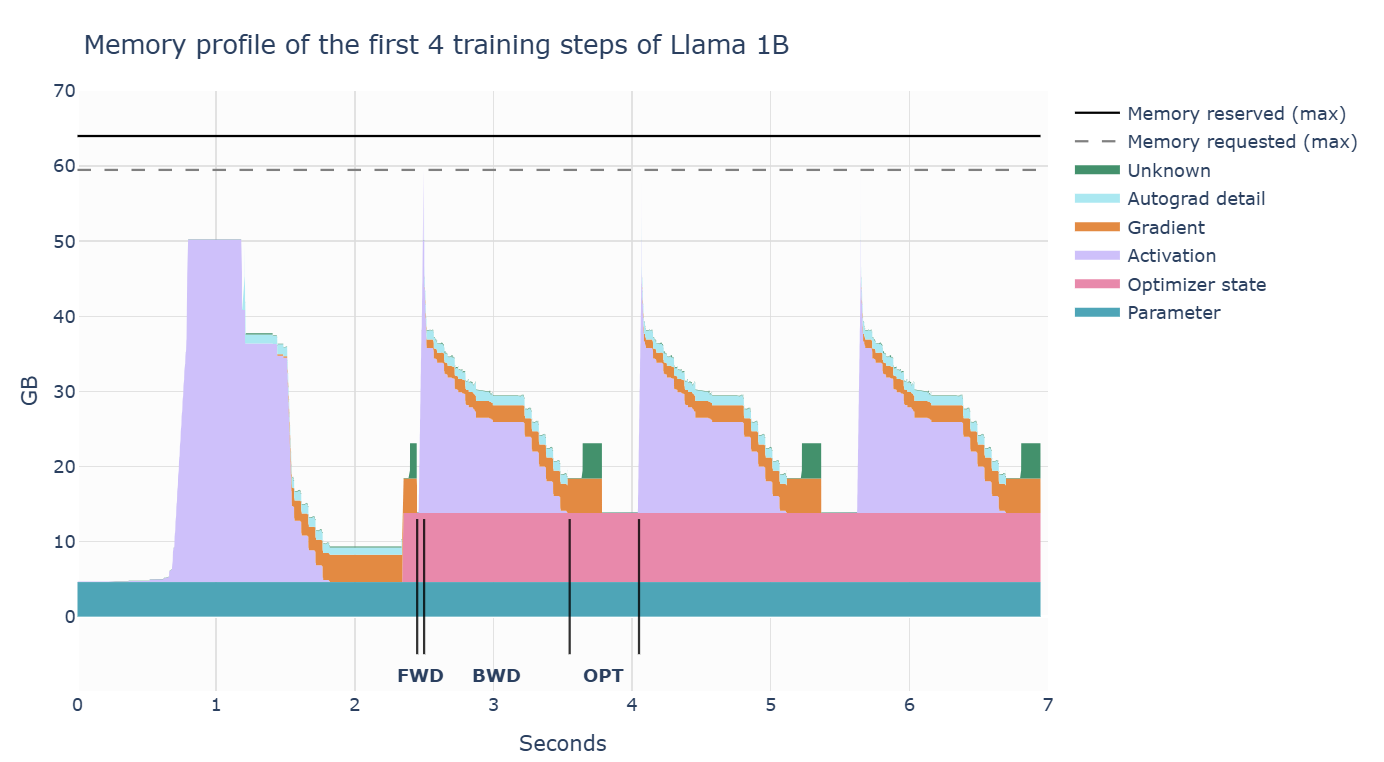
训练基本步骤:前向传播时,激活值迅速增加;反向传播时,梯度逐渐积累,且计算梯度的激活值会逐步被清除;最后,执行优化步骤,此时需要所有的梯度,并更新优化器状态;然后才开始下一次的前向传播。
第一步和后续步骤明显不同的原因:激活值快速增加,再保持一段时间的平稳。在第一步中,torch 的缓存分配器进行大量准备工作,预先分配内存;后续步骤不再需要寻找空闲内存块,从而加速)
weights/grads/optimizer state的内存
对于一个简单的transformer LLM,参数数量如下: \[ N=h*v+L*(12*h^2+13*h)+2*h \] \(h\)是隐藏层维度,\(v\)是词汇大小,\(L\)是模型的层数;可以看到,当隐藏层维度较大时,主导项是\(h^2\)项。
**内存需求:参数数量*每个参数的字节数**
传统FP32训练中,参数、梯度均需4字节,优化器(例如Adam)需要存储动量和方差,为每个参数增加另外两个4字节。
\(m_{params}=4*N\)
\(m_{grad}=4*N\)
\(m_{opt}=(4+4)*N\)
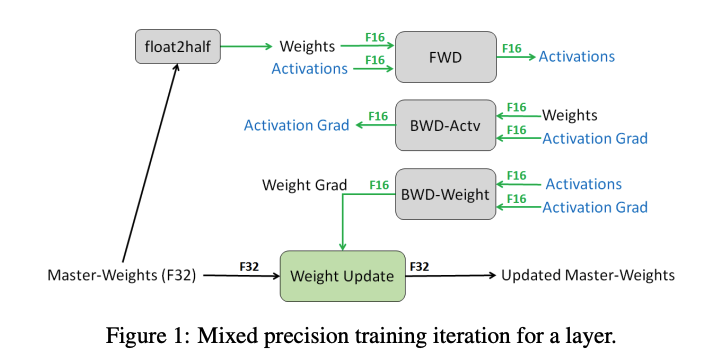
若使用高低混合精度训练,当前默认做法是:使用BF16进行大部分计算(每个参数、梯度分别需要2字节),额外复制一份模型权重和梯度为 FP32,因此每个参数总共需要 12 字节。即:
\(m_{params}=2*N\)
\(m_{grad}=2*N\)
\(m_{params_{fp32}}=4*N\)
\(m_{opt}=(4+4)*N\)
混合精度本身并不会节省整体内存,它只是将内存在三个组件之间重新分配。在前向和反向传播中使用半精度计算可以: 1. 在 GPU 上使用经过优化的低精度操作,这些操作更快; 2. 减少前向传播过程中的激活内存需求,而激活内存占用了大量内存。
若使用 FP8 训练代替 BF16,内存使用量会进一步减少(但它的稳定性较差)。
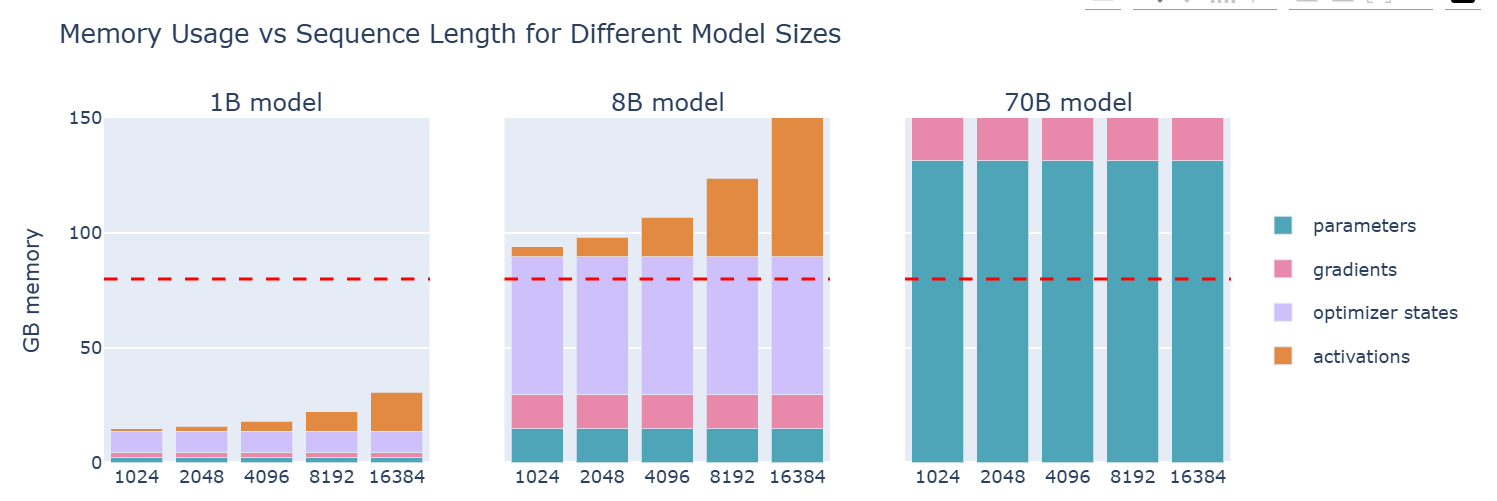
模型参数数量 FP32 或 BF16(不使用 FP32 梯度累积) BF16(使用 FP32 梯度累积) 1B 16 GB 20 GB 7B 112 GB 140 GB 70B 1120 GB 1400 GB 405B 6480 GB 8100 GB 可以观察到,一旦达到 7B 参数,权重和优化器的内存需求就会显著增加,并超过典型 GPU 内存的大小。
activations的内存
依赖于模型的输入。总内存如下: \[ m_{act}=L*seq*bs*h*(34+\frac{5*n_{heads}*seq}{h}) \] 其中,\(L\)是层数,\(seq\)是序列长度,\(bs\)是batch size,\(h\)是模型的隐藏维度,\(n_{heads}\)是注意力头的数量。
可以观察到,内存使用量会随着批量大小线性增长,并随着序列长度的平方增长,那么:激活内存是最容易“膨胀”的部分。
对于短序列(或者小批量大小),激活几乎可以忽略不计;但从大约 2-4k 个 token 开始,它们就会占用大量内存,而参数、梯度和优化器状态的使用,则基本上与序列长度和批量大小无关。
控制activation增长的策略
activation重计算(gradient checkpoints)
也叫做:梯度检查点,重物化。在前向传播时,抛弃一些activations;在后向传播时,实时重新计算activations。
- Full(全量重计算):在Transformer的每层transition point上,设置activations checkpoints:要求每层进行一次前向传播,即在反向传播过程中增加一次完整的前向传播。
- 可以节省最多内存,但在计算上最昂贵。
- Selective(选择性重计算):注意力激活值增长较多且在FLOP上计算便宜,因此抛弃他们。
- 对于一个GPT-3(175B)模型,可以减少70%的激活内存,而计算成本仅为2.7%;DeepSeek V3使用“多头潜在注意力”(MLA)来优化激活内存。
当前大多数框架使用Flash Attention,在其优化策略中,原生集成了activation重计算:在反向传播中,计算(而非存储)注意力分数和矩阵。
activation重计算略微增加FLOPs的数量;但显著减少内存开销。该策略对具备小型高速内存的硬件尤为有利(比如GPU)。
梯度累积(gradient accumulation)
梯度累积将batch拆分为若干个小的micro-batch;依次在每个micro-batch上进行前向、反向传播,计算梯度,在执行优化步骤前,将所有micro-batch梯度相加。实际上,优化步骤是基于梯度的平均值(而非总和)进行的,因此结果与梯度累积步骤的数量无关。有: \[ bs=gbs=mbs*grad_{acc} \] 其中:每次前向传播的batch size为\(mbs\);每两个优化步骤之间的batch size为\(gbs\)。假设在每进行8次前向/反向传播后执行一次优化步骤,则\(gbs\)将是\(mbs\)的8倍。
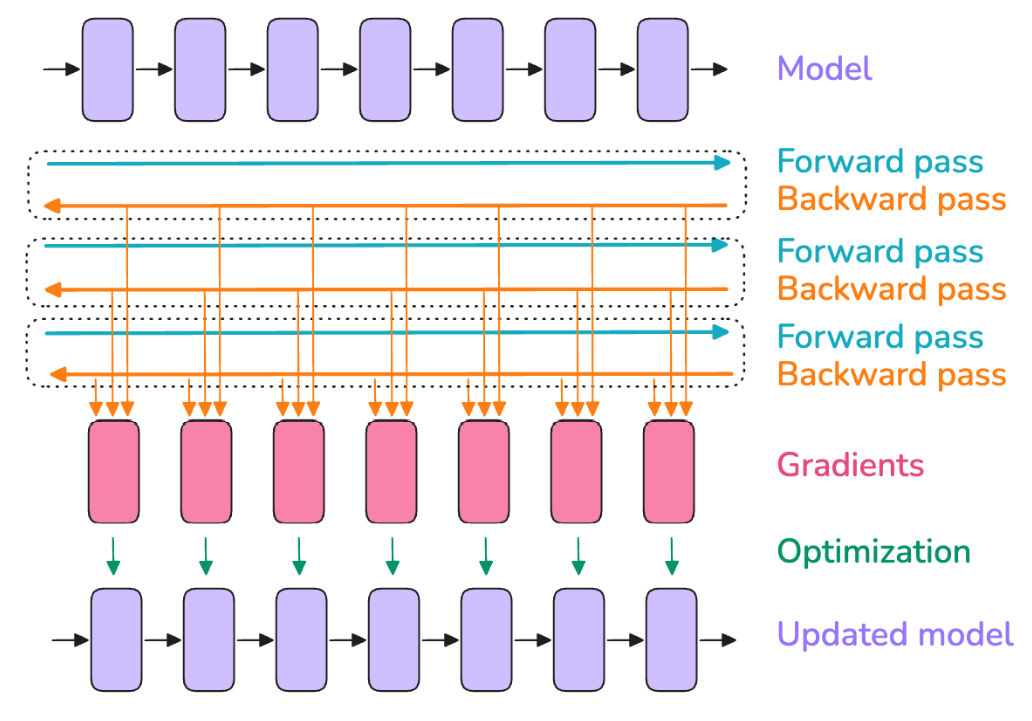
梯度累积的一个缺点:在每个优化步骤中,需要执行多个连续的前向/反向传播,从而增加计算开销,减慢计算速度。
然而,每个micro-batch的前向/反向传播可以并行运行。前向/反向传播是相互独立的,唯一的区别是输入样本。因此可以将训练扩展至多个GPU!
并行策略
数据并行(Data Parallelism)
思想:将模型复制到多个GPU上;在每个GPU上,对不同的micro batches执行前向/反向传播。
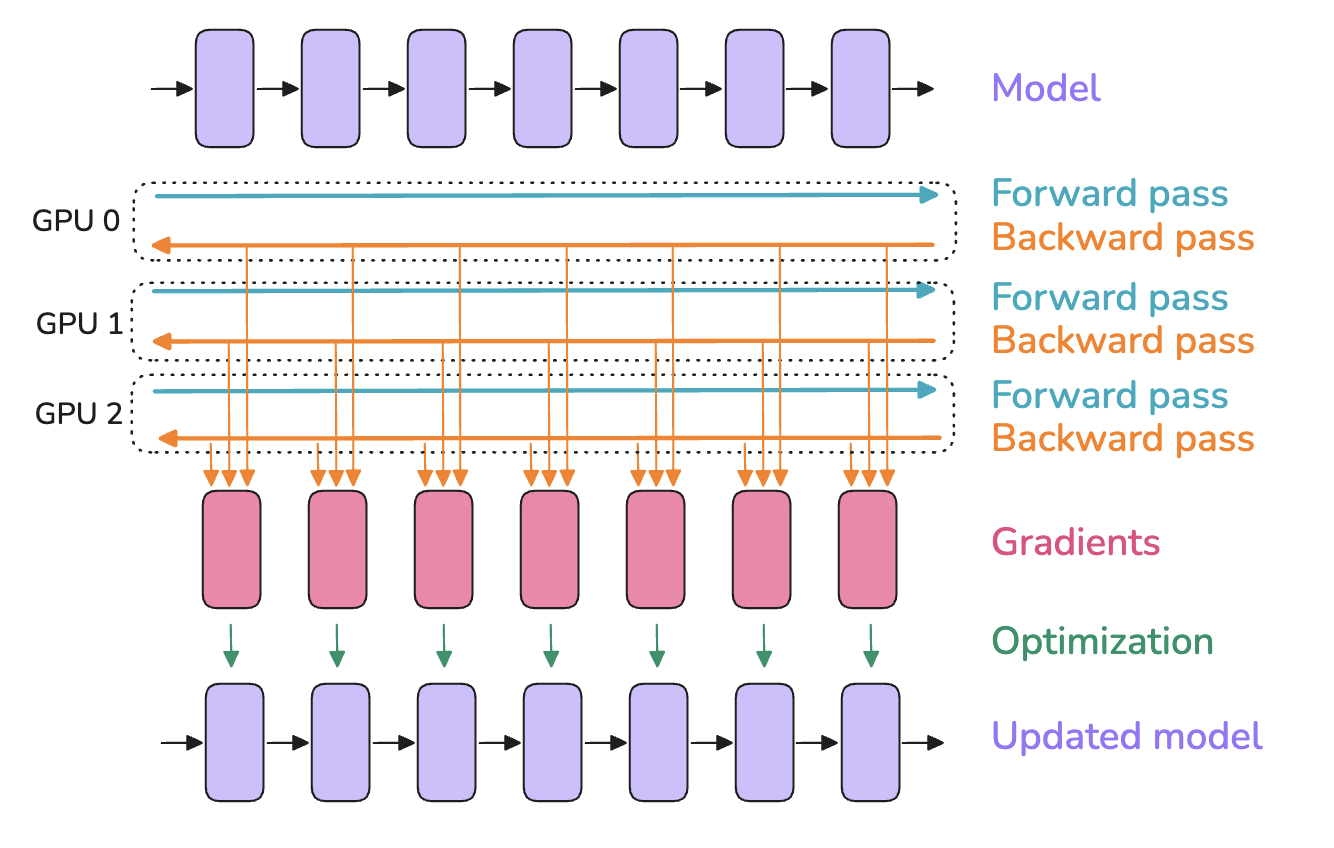
在每个GPU上使用不同的micro batch,那么每个GPU上的梯度不同;为了保持不同GPU上的模型实例同步,使用all-reduce对模型实例的梯度进行平均,该过程在优化之前的反向传播中执行。
- all-reduce原语:处理 GPU 实例和节点之间的同步和通信。


一个朴素的实现方式:等待反向传播完成所有的梯度计算;触发all-reduce操作,进行通信以同步这些梯度。然而,这会导致通信时GPU空闲,而我们希望通信和计算能并行。有哪些方法呢?
优化策略
优化一:梯度同步(通信)与反向传播(计算)并行
 一旦最后一层的反向传播计算完成,这些梯度可以立即被收集、求和;而反向传播计算会继续向左传播,计算更早层的梯度。
一旦最后一层的反向传播计算完成,这些梯度可以立即被收集、求和;而反向传播计算会继续向左传播,计算更早层的梯度。
1 | def register_backward_hook(self, hook): |
优化二:梯度分桶
GPU 操作通常在大tensor上执行时效率更高;通信操作亦然。因此,可以通过将梯度分组到多个桶中,并为每个桶内的所有梯度启动一个单独的 all-reduce 操作,(而不是为每个梯度执行独立的 all-reduce 操作)。显著减少通信开销,加速通信操作。 
优化三:配合梯度累积
何时同步梯度?
在一个简单版本中,每次反向传播后,自动触发一个 all-reduce 操作,这样效率较低:在最终步骤之后执行一次 reduce 操作能达到相同效果,同时减少开销。
在 PyTorch 中,通常在不需要进行梯度同步的反向传播上添加
model.no_sync()装饰器,来解决这个问题。
加入DP和梯度累积参数后,global batch size更新如下: \[ bs=gbs=mbs*grad_{acc}*dp \] 其中,\(grad_{acc}\)是梯度累积的步数,\(dp\)是DP中并行实例的数量。
实际上,一般倾向于最大化DP中并行节点的数量:因为DP是并行的,梯度累积是顺序的。在数据并行扩展不足时,再加上梯度累积,以达到目标的global batch size。
DP步骤
总结一下采用DP进行训练的配置步骤:
- 确定最佳的global batch size(in tokens);
- 选择训练的序列长度(2~8k个tokens当前结果不错);
- 寻找单个GPU上最大的local batch size(mbs)(不断增加,直到耗尽内存);
- 确定DP使用的GPU数量:GBS 与 DP 的比值决定所需的梯度累积步数。
例子: 假设要训练一个global batch size=4M的模型,序列长度为4k;则批量大小为1024个样本。
假设观察到单个 GPU 只能容纳 MBS=2 的内存,并且有 128 个 GPU 可供训练。那么:通过4步梯度累积,将实现每个训练步骤 1024 个样本或 4M tokens 的目标。
如果突然有 512 个 GPU 可用,仍然可以保持 MBS=2,并将梯度累积步数设置为 1,从而实现更快的训练!
注意:在使用 512+ 个 GPU 的规模时,取决于所使用的网络,通信操作将开始受到环延迟的限制,这会降低计算效率,并影响吞吐量。
虽然DP将梯度同步的 all-reduce 操作与反向传播计算重叠以节省时间,但这种好处在大规模下开始失效。为什么?因为随着添加更多的 GPU(成百上千个),它们之间的协调开销会显著增加,导致网络需求变得过大,抵消了带来的好处。随着每个新 GPU 加入,设置DP的效率将越来越低。
DeepSpeed ZeRO(零冗余优化器)
在每个DP rank上对优化状态、梯度、参数进行赋值,将导致大量内存冗余。ZeRO通过在数据并行维度上,对优化器状态、梯度和参数进行分区来消除内存冗余,同时仍然允许使用完整的参数集进行计算。
activations不参与分区:每个DP replica接收不同的micro-batch,因此每个DP节点上的activations也不同,不参与复制。
考虑如下场景:使用混合精度训练和Adam优化器时,假设模型参数量为 \(\psi\),那么每张GPU中的显存内容分为两类:
- 模型状态:
- 模型参数(半精度,bf16/fp16):\(2\psi\)
- 模型梯度(半精度,bf16/fp16):\(2\psi\)
- Adam优化器状态(FP32格式的模型参数备份、FP32的momentum和FP32的variance):\(4\psi+4\psi+4\psi\) Adam状态占比75%。
- 剩余状态: 除了模型状态之外的显存占用,包括activation、各种buffer以及无法使用的显存碎片(fragmentation)。
混合精度训练:同时存在fp16和fp32两种格式的数值,其中模型参数、模型梯度都是fp16,此外还有fp32的模型参数,如果优化器是Adam,则还有fp32的momentum和variance。、
假设显卡数量为\(N\),提出以下三种ZeRO算法: 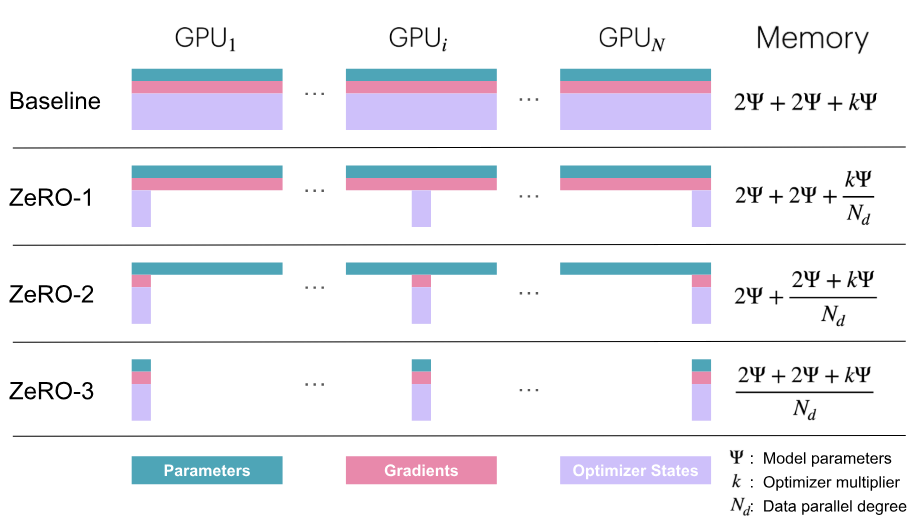
- ZeRO-1:只对优化器状态进行分片,每张卡保存\(\frac{1}{N}\)的状态量。此时,每张卡所需显存是\(4\psi+\frac{12\psi}{N}\)字节,当\(N\)较大时,趋向于\(4\psi\),记为\(P_{os}\);
- ZeRO-2:对优化器状态和梯度进行分片,此时,每张卡所需显存是\(2\psi+\frac{2\psi+12\psi}{N}\)字节,当\(N\)较大时,趋向于\(2\psi\),记为\(P_{os+g}\);
- ZeRO-3:将模型参数、梯度、优化器状态三者都进行分片,此时,每张卡所需显存是\(\frac{16\psi}{N}\)字节,当\(N\)较大时,趋向于\(0\),记为\(P_{os+g+p}\);
- ZeRO-3对应Pytorch FSDP
ZeRO-1,ZeRO-2,ZeRO-3通信量分析
集群通信:
reduce-scatter:
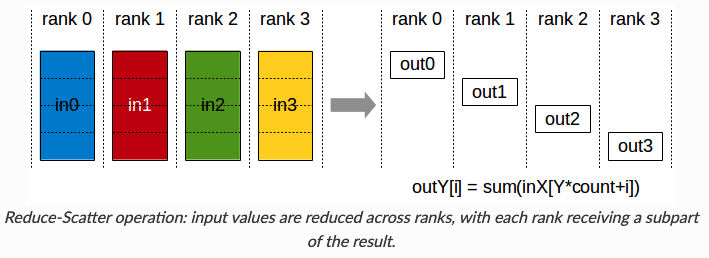 all-gather:
all-gather: 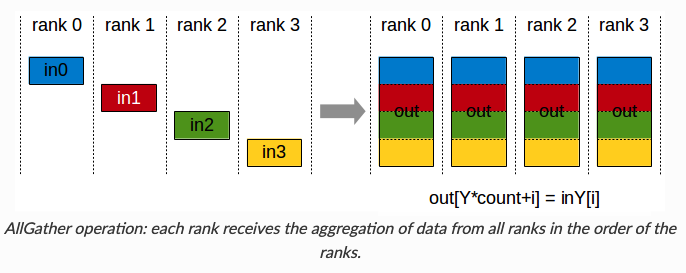 Ring all-reduce:由reduce-scatter,all-gather两个步骤组成:
Ring all-reduce:由reduce-scatter,all-gather两个步骤组成: 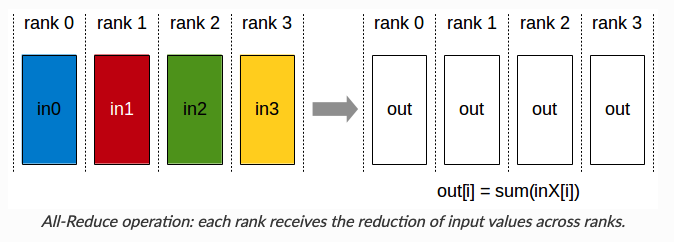
传统的DP在每一步计算梯度后,需要一次all-reduce操作计算梯度均值,当前常用Ring all-reduce,分为reduce-scatter和all-gather两步。
ZeRO-1,ZeRO-2将all-reduce梯度通信改为:reduce-scatter操作,并在优化器步骤之后,增加了对所有参数的all-scatter操作。
- \(P_{os}\),\(P_{os+g}\)和传统DP的通信量相同
ZeRO-3:
- 前向传播:依次通过各个layer,按需获取必要的参数;在参数不再需要时,立即从显存中清除。
- 反向传播:生成梯度分片。
需要在前向/反向传播中,持续执行all-gathers操作,那么与ZeRO-2相比,需要额外执行\(2*numLayers-1\)次all-gather,每次操作都会带来一个小的基础延迟开销。
在前向传播时,需要参数时执行all-gather操作,产生一个\(\psi\)的通信开销,立即清除不需要的参数,因此反向传播时还需要一次all-gather操作;最后,与ZeRO-2相同,进行reduce-scatter操作处理梯度,产生\(\psi\)的通信开销。总通信开销为:\(3\psi\)(ZeRO-2的通信开销为\(2\psi\))
- 前向传播:依次通过各个layer,按需获取必要的参数;在参数不再需要时,立即从显存中清除。

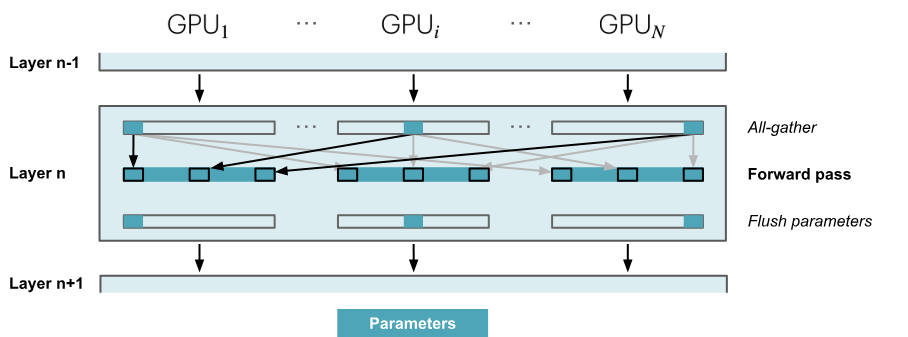
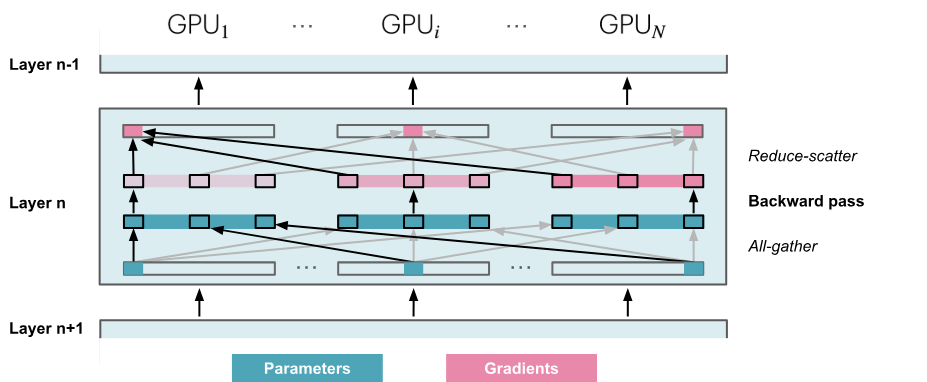

ZeRO-R
在进行tensor并行时,前向传播中的activations会在各个GPU中重复存储,因此:ZeRO-R将所有的中间activations分片存储,即只对activation checkpoints分片(其他activations已被抛弃)
见:重计算
正常情况:保存前向传播中,每一个activations,用于反向传播时计算梯度;每一个前向中的activation,到计算完对应梯度节点后,才能释放。
- 缺点:需要保存大量的中间激活值,导致占用了大量显存,并且所需的显存是随着层数n线性增长的。
优化一:将所有的中间激活值全部丢弃,反向传播需要时,再重新计算;
- 缺点:训练速度慢,每个前向节点原本只需要计算一次,现在最多需要计算n次!
折中做法:选取一些前向节点作为checkpoint,训练时,这些checkpoint节点的激活值会一直保存在显存中,而其他节点的激活值会被丢弃。
- 优点:计算反向梯度节点时,只需要从离它最近的checkpoint节点开始计算,而不用把每个节点都重新计算一遍。
ZeRO-Offload
GPU显存不够用,则:将一部分计算和存储下放到CPU和内存,并且不让CPU和GPU之间的通信成为瓶颈,也不让CPU参与过多计算,避免CPU计算成为瓶颈。
Adma优化器中,每一层迭代如下: 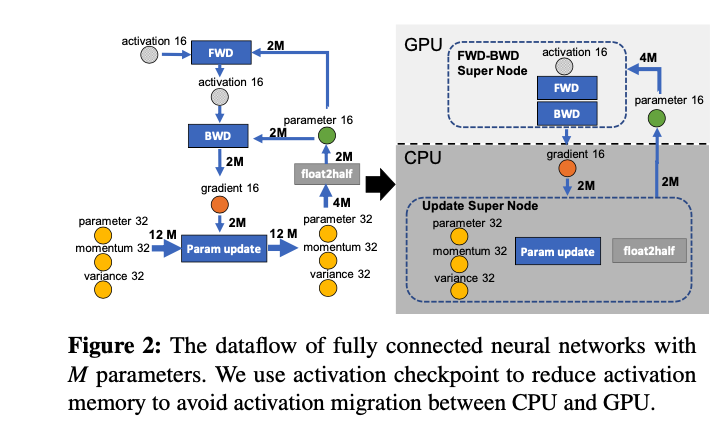
将数据流图切分成CPU和GPU两部分。ZeRO-Offload策略如下:它将计算复杂度较高的前向FWD和反向BWD放在GPU上;而参数更新和float2half这两个计算操作放在CPU上。因此,优化器状态也放在内存中,
述方法仅仅针对单卡场景。在多卡场景下,ZeRO-Offload利用ZeRO-2方法。ZeRO-2将优化器状态和梯度分片,每张卡只存储\(\frac{1}{N}\),而ZeRO-Offload将这\(\frac{1}{N}\)个优化器状态和梯度都下放到内存,只在CPU上进行参数更新.
更多内容参考:大模型并行训练技术(一)—— ZeRO系列
张量并行(Tensor Parallelism)
数学原理
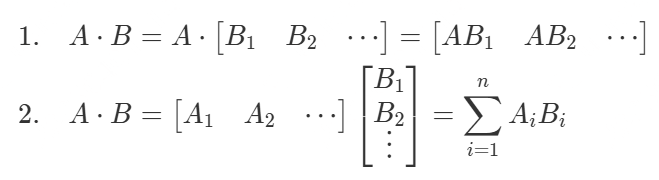
在神经网络中,矩阵乘法常用以下方式表示:\(X\times W\),其中:
- \(X\)为activation的输入;
- \(W\)为
nn.Linear的权重。
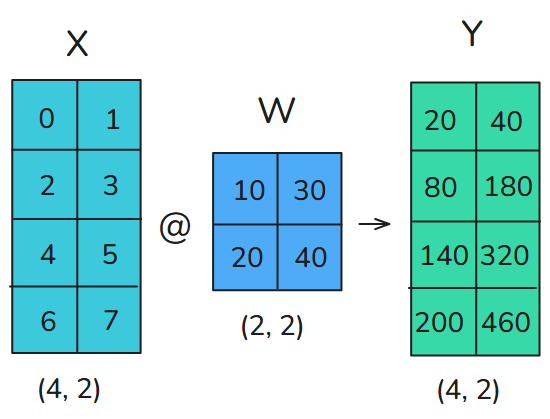
在TP中,tensors将被沿着一个特定维度分为N个shards,并分布在N个GPU上。矩阵可以按行/按列切分,分别对应行并行、列并行。
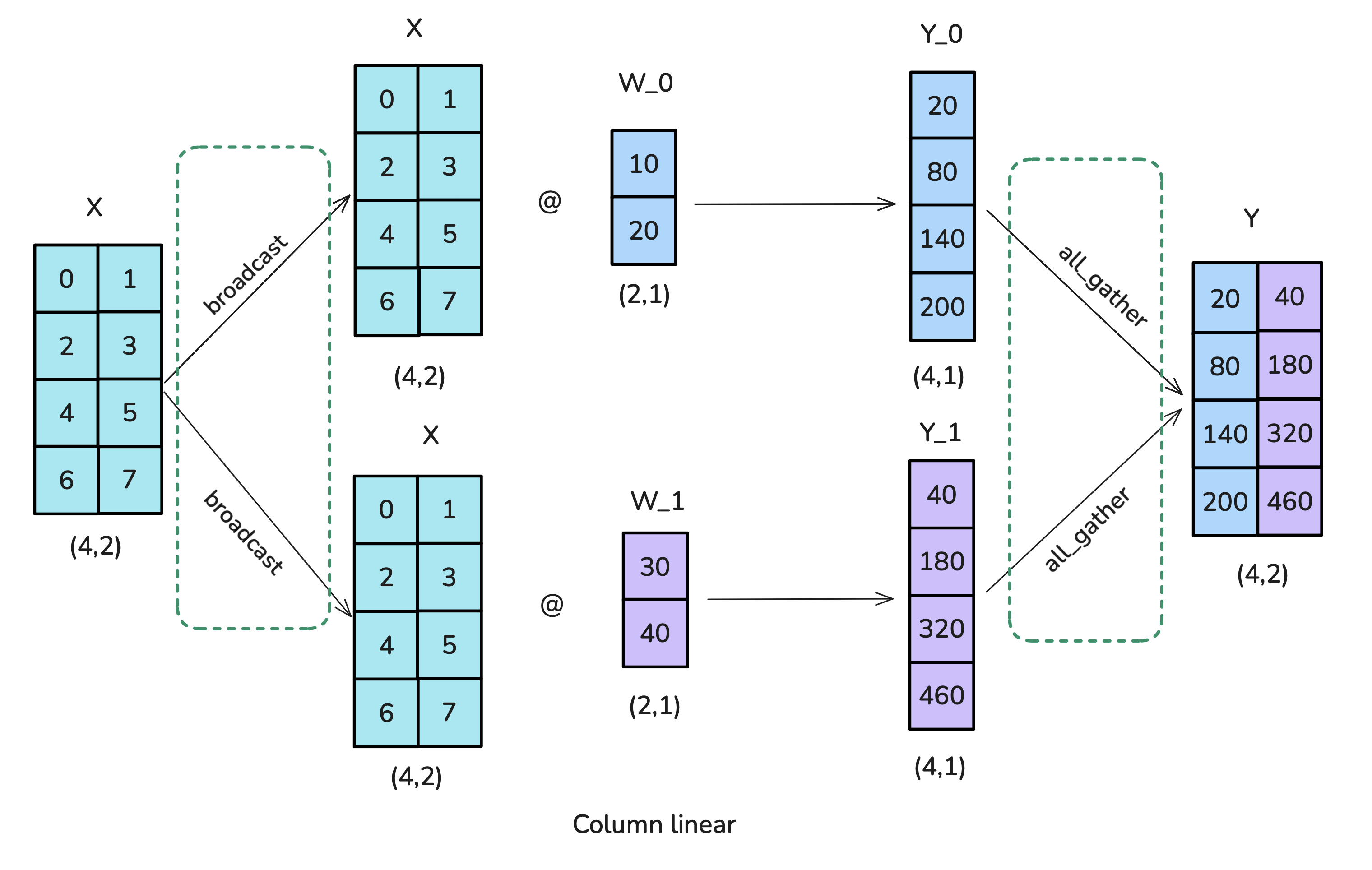
column-linear
- 运用broadcast操作,将输入矩阵复制到每个worker;
- 将每个权重矩阵切分为若干个列,分别与输入矩阵相乘,最后通过all-gather操作结合。
row-linear
- 运用scatter操作,将输入矩阵切分为若干个列;
- 将每个权重矩阵切分为若干行,分别与输入矩阵的各列相乘,最后通过all-reduce操作相加。
Transformer Block内部的张量并行
一个Transformer由两个主要的block组成:前向反馈层(Feedbackforward layers,MLP)和多头注意力层(Multi-Head Attention,MHA),可以同时运用TP。
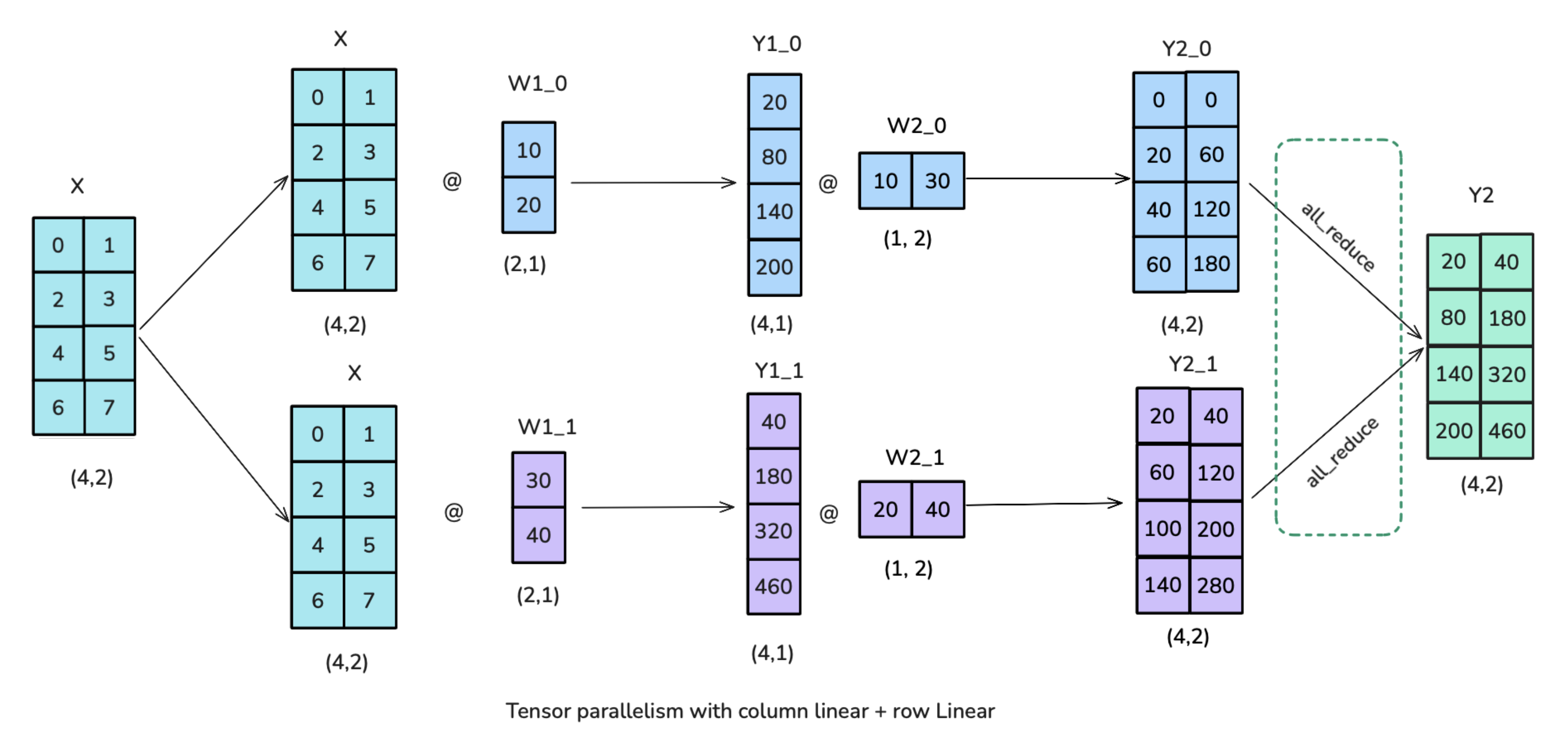
前向反馈层(MLP)
MLP:先使用column-linear,再使用row-linear(现实训练中不需要broadcast操作,因为可以确保输入已经在TP ranks之间同步)
比先row-linear后column-linear更快,省去了中间的all-reduce操作。
多头注意力层(MHA)
将 Q、K 和 V 矩阵按列并行拆分,输出投影则沿着行维度拆分。在多头注意力的情况下,按列并行的方法有一个非常自然的解释:每个worker计算单个或一部分head的注意力。这种方法同样适用于多查询(MQA)或分组查询注意力(GQA),其中,keys和values在queries之间共享。 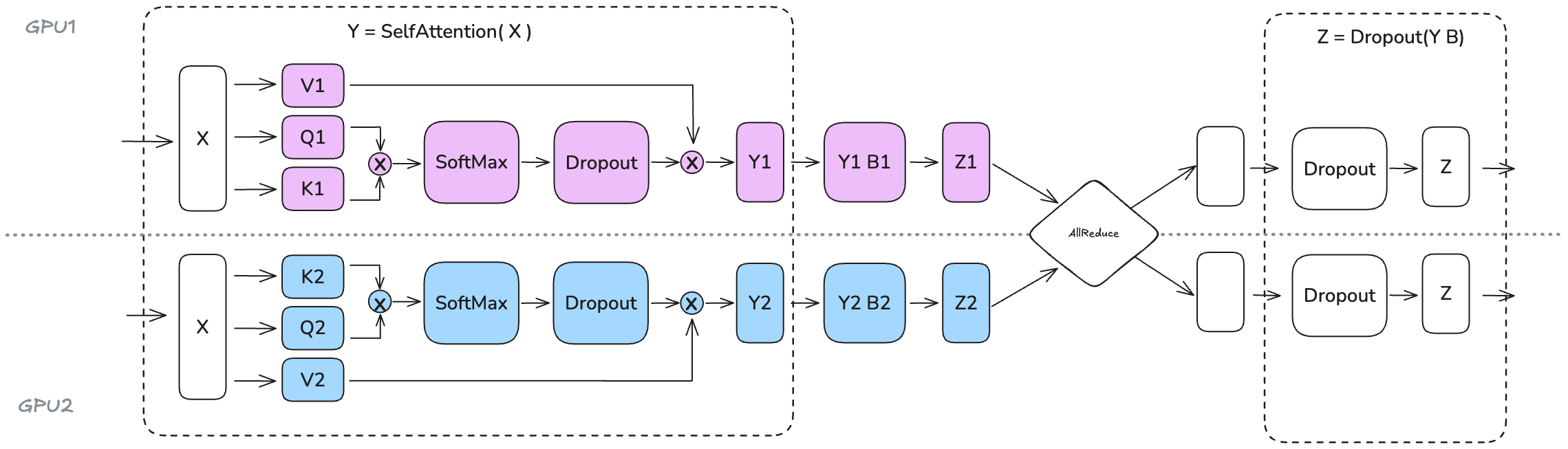
值得注意的是,张量并行度(TP degree)不应超过Q/K/V 头的数量,因为需要保证每个 TP rank的head是完整的(否则无法在每个 GPU 上独立计算注意力,需要额外的通信操作)。
如果使用 GQA,TP 幅度应该实际小于 K/V 头的数量。例如,LLaMA-3 8B 模型有 8 个Key/Value heads,因此TP degree最好不要超过 8;如果我们为这个模型使用 TP=16,那么我们需要在每个 GPU 上复制 K/V 头,并确保它们保持同步。
TP性能
然而,TP也不是万全之策。需要在模型的计算路径中直接添加了多个分布式通信原语,因此这些通信操作很难完全隐藏或与计算重叠(就像在 ZeRO 中做的那样)。最终的性能将是计算和内存增益与额外通信开销之间的折中结果。举个例子:
MLP的操作流程图如下:  在每个decoder layer的前向传播中,会遇到一个同步点(即all-reduce操作,无法与计算重叠);该通信开销是必需的,在应用 LayerNorm 之前,合并tensor-parallel ranks的结果。
在每个decoder layer的前向传播中,会遇到一个同步点(即all-reduce操作,无法与计算重叠);该通信开销是必需的,在应用 LayerNorm 之前,合并tensor-parallel ranks的结果。
- TP优点:TP有助于减少矩阵乘法的activation memory,因为过程中间的activations被分片存储在不同的 GPU 上;
- TP缺点:
- 需要收集完整的activations以执行类似 LayerNorm 的操作,这并没有完全利用内存的优势;
- 引入大量通信需求,严重依赖于网络基础设施。由于无法完全将这个特定的 AllReduce 操作与计算重叠,它直接延长了前向传播的关键路径。
下图展示分布式训练中,计算效率和内存可用性之间的trade-off:随着TP degree增加,虽然每个GPU的吞吐量减少(左图),但它能够处理更大的批量大小(右图)。 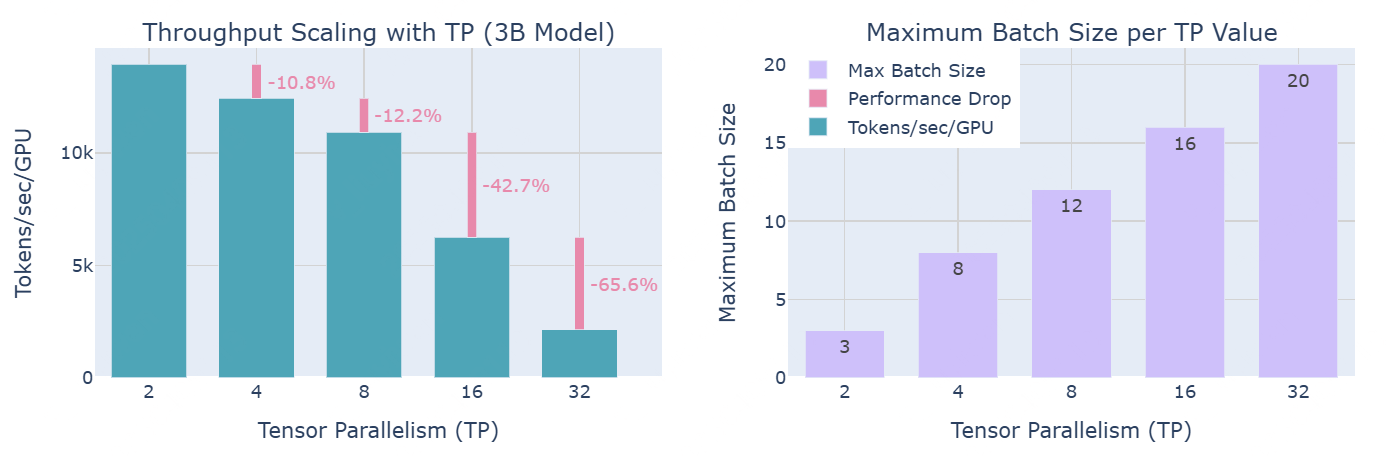
实际上,正如左图所示:TP的通信开销在超越 8 个 GPU 时变得尤为显著:虽然在单节点内使用TP时,可以利用快速的 NVLink 互连,但跨节点通信则依赖于较慢的网络连接;当从 TP=8 增加到 TP=16 时,性能有显著下降;而从 TP=16 增加到 TP=32 时,下降更加明显。在更高的并行度下,通信开销变得如此之高,以至于它迅速主导了计算时间。
70B大模型的内存使用量
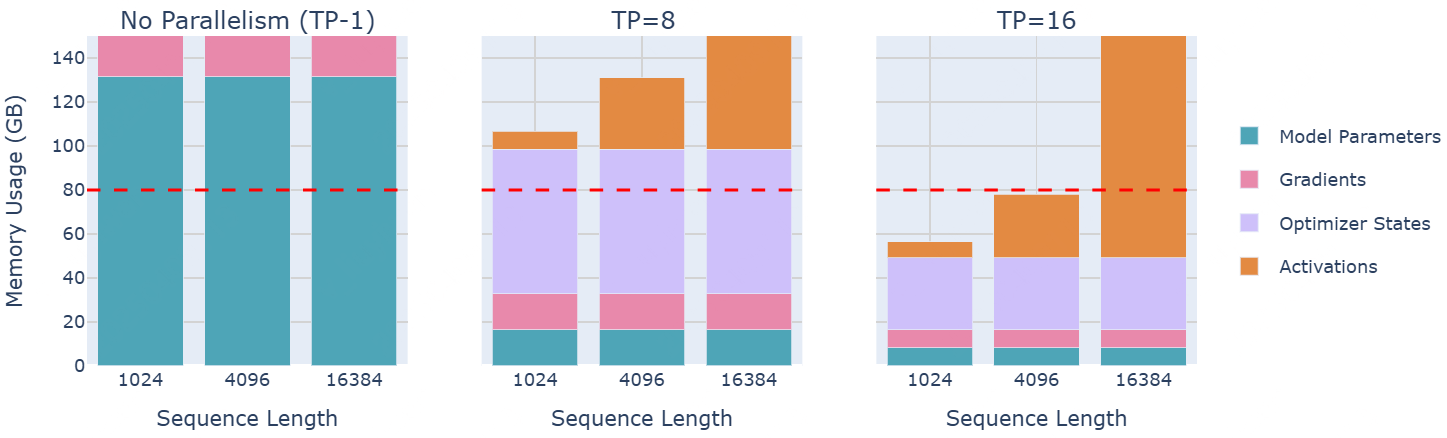
是否有办法从TP中获得更多的好处呢?可以看到,层归一化(Layer Normalization)和Dropout仍然需要在每个 GPU 上收集完整的activations,这在一定程度上抵消了内存节省。可以通过寻找方法将这些剩余操作也并行化,从而做得更好。
- TP中的层归一化:由于每个 TP rank 在 all-gather 之后看到的是相同的activations,因此层归一化的权重实际上不需要 all-reduce 来同步它们的梯度。在反向传播之后,它们自然会在各个 rank 上保持同步;
- TP中的Dropout:必须确保跨 TP rank 同步随机种子,以保持行为的确定性。
一个小扩展:序列并行(Sequence Parallelism)
SP切分TP未处理的activations和computations(例如:LayerNorm和Dropout),但是沿着input sequence的维度(不是跨隐藏层的维度)。
上述操作需要访问完整的隐藏维度才能正确计算。例如:LayerNorm需要完整的隐藏维度,以计算均值和方差: \[ LayerNorm(x)=\gamma\cdot\frac{x-\mu}{\sqrt(\sigma^{2}+\epsilon)}+\beta \] 其中,\(\mu=mean(x)\),\(\sigma^{2}=var(x)\)是沿着隐藏层\(h\)计算的。
尽管这些操作在计算上比较简单,但它们仍然需要大量的激活内存,因为它们需要完整的隐藏维度。SP允许我们沿着sequence维度拆分,来将这一内存负担分摊到多个GPU上。
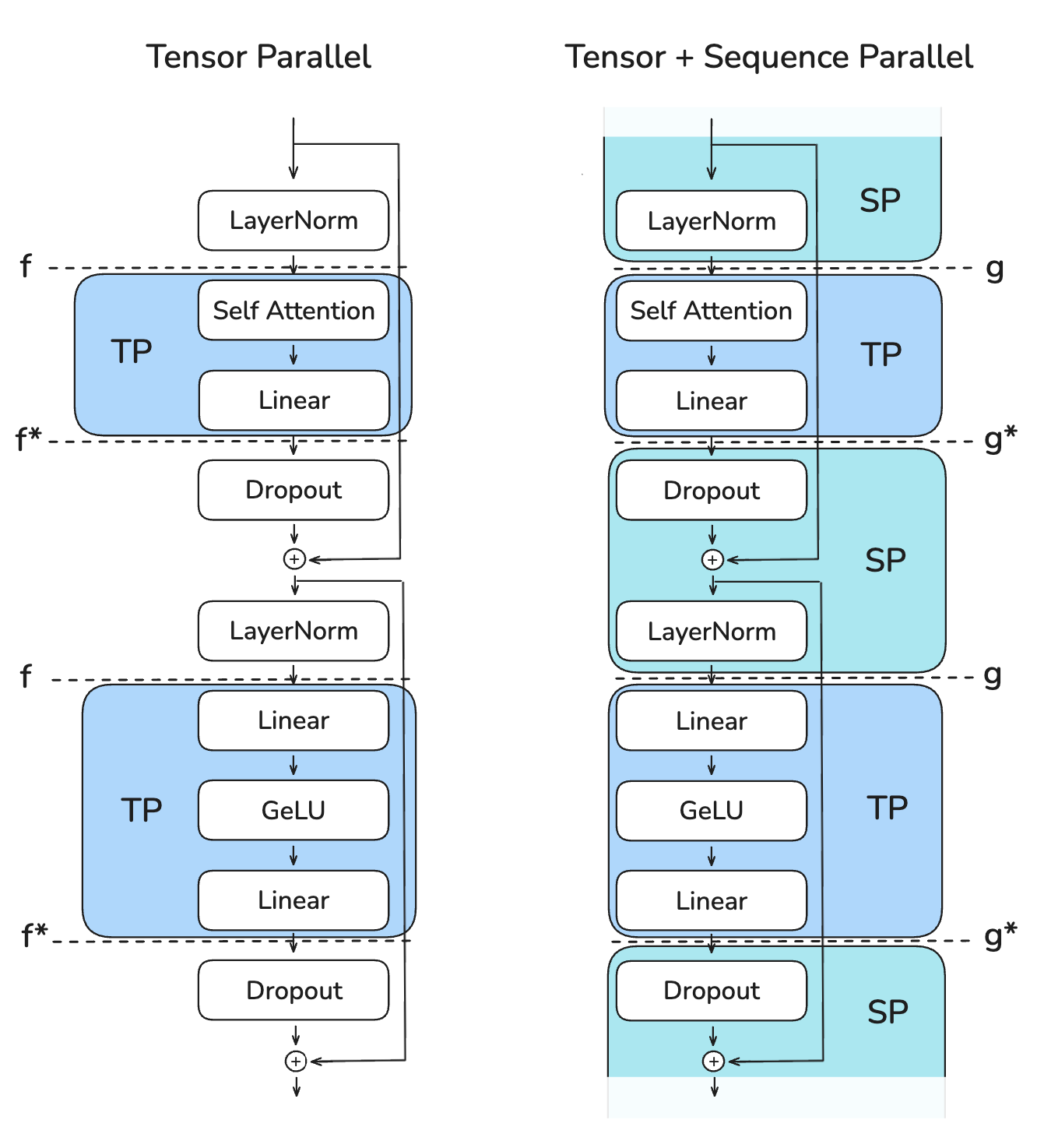
- 前向传播:
- "f" 是一个无操作(no-op),因为activations已经在不同的rank之间进行了复制;
- "f*" 是一次全归约(all-reduce),用于同步activations,并确保正确性。
- 反向传播:
- "f*" 是一个无操作(no-op),因为gradient已经在不同的rank之间进行了复制;
- "f" 是一次全归约(all-reduce),用于同步gradient。
这些操作“f”和“f*”被称为共轭对,因为它们是互补的——在前向传播中,当一个是no-op时,另一个在反向传播中是all-reduce,反之亦然。
在SP中,避免使用all-reduce(需要收集完整的激活值)
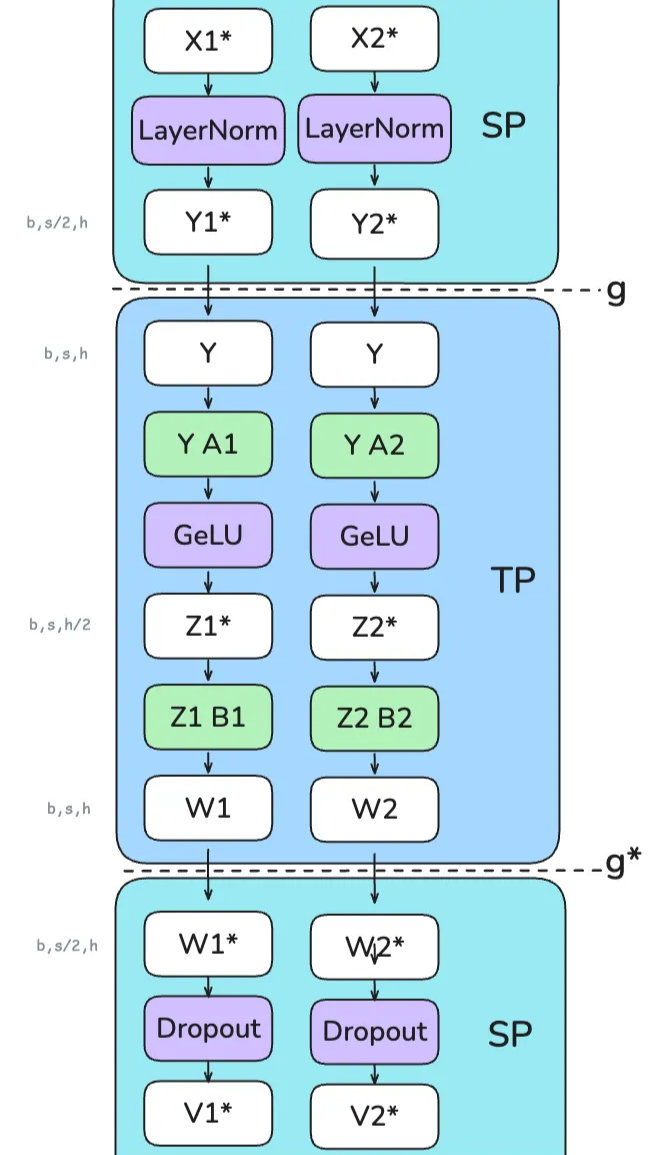
事实上发生了什么呢?
- 初始层归一化(SP区域)
- 输入张量 X1 和 X2(形状为 b, s/2, h)进入LayerNorm,已经沿sequence维度进行拆分 每个GPU独立计算它们各自序列块的LayerNorm,得到 Y1 和 Y2;
- 第一次转换(SP → TP)
- “g”操作(all-gather)将 Y1 和 Y2 合并回完整的序列长度 恢复 Y(形状为 b, s, h)
- 第一次线性变换(TP区域)
- A1层 是column-linear,所以它沿隐藏维度拆分 Y;GeLU 激活函数在每个GPU上独立应用 Z1,形状为 (b, s, h/2)
- 第二次线性变换(TP区域)
- B1层 是row-linear,它恢复隐藏维度 W1 形状为 (b, s, h)
- 最后转换(TP → SP)
- “g*”操作(reduce-scatter),在前一个row-linear层的进行dropout,同时在sequence维度上进行分散;W1形状为 (b, s/2, h)
SP:的一大优势是:它减小了需要存储的最大的activation size。在仅使用TP时,需要在不同的点存储形状为(b, s, h)的activations。然而,使用SP后,最大的activation size减小到\(\frac{b\cdot s\cdot h}{tp}\)(\(tp\)是分割数),因为总是沿着序列维度或隐藏维度进行拆分。
以下表格描述:前向传播过程中,activations shape随着隐藏维度\(h\)和序列维度\(s\)的变化:
| Region | TP only | TP with SP |
|---|---|---|
| Enter TP (Column Linear) | h: sharded (weight_out is sharded) | h: sharded (weight_out is sharded) s: all-gather to full |
| TP Region | h: sharded s: full | h: sharded s: full |
| Exit TP (Row Linear) | h: full (weight_out is full + all-reduce for correctness) s: full | h: full (weight_out is full + reduce-scatter for correctness) s: reduce-scatter to sharded |
| SP Region | h: full s: full | h: full s: sharded |
对于嵌入层:
| Region | Vanilla TP | TP with SP |
|---|---|---|
| Embedding Layer (Row Linear sharded on vocab) | h: full (weight_out is full + all-reduce for correctness) s: full | h: full (weight_out is full + reduce-scatter for correctness) s: reduce-scatter to sharded |
70B大模型的内存使用量
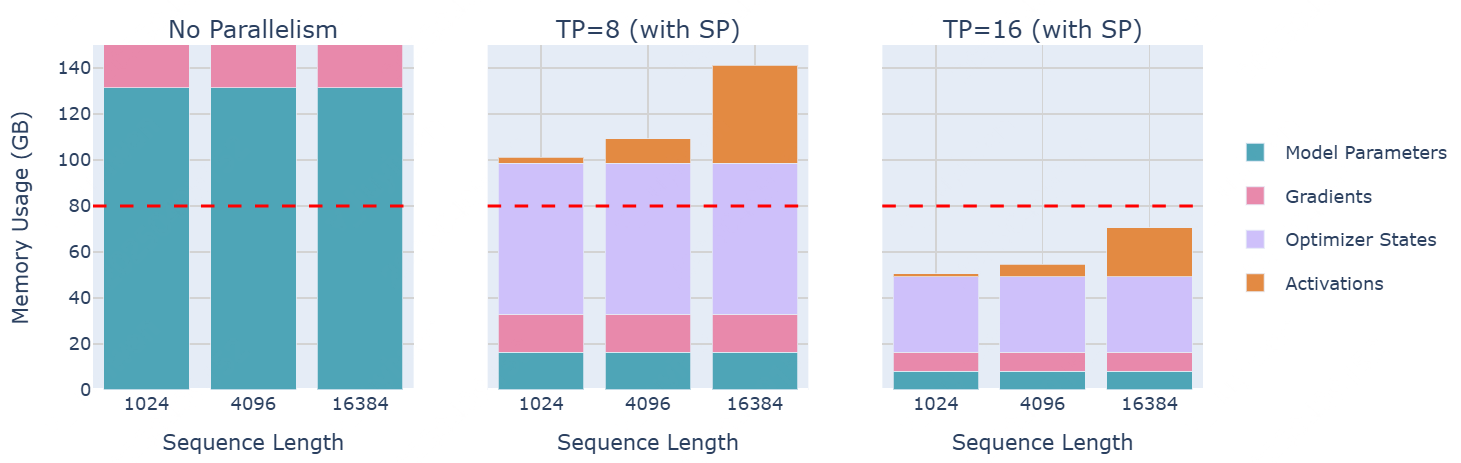
如上图,通过TP/SP=16,使得处理16k tokens成为可能。
使用TP+SP是否会比传统的TP引入更多的通信开销?是和否都有可能。
在传统TP的前向传播过程中,每个Transformer块中有两个all-reduce操作;而在SP中,每个Transformer块中有两个all-gather和两个reduce-scatter操作。因此,SP的通信操作数量是TP的两倍。但由于all-reduce操作可以分解为all-gather + reduce-scatter。因此它们在通信开销上是等效的。同样的推理适用于反向传播,因为我们只需使用每个操作的共轭(no-op ↔︎ all-reduce,all-gather ↔︎ reduce-scatter)。
在每个layer中,讨论了4个通信操作(2个用于Attention,2个用于MLP)。以下为TP+SP时,MLP的性能分析情况: 
和TP相似,TP+SP难以与计算重叠,这使得吞吐量在很大程度上依赖于通信带宽。在这一点上,和传统TP一样,TP+SP通常只在单个节点内执行(将TP degree保持在每个节点的GPU数量之下,例如TP≤8)。
TP+SP性能
以下为使用TP+SP扩展时,对于一个3B模型和4096序列长度,吞吐量和内存利用率的变化: 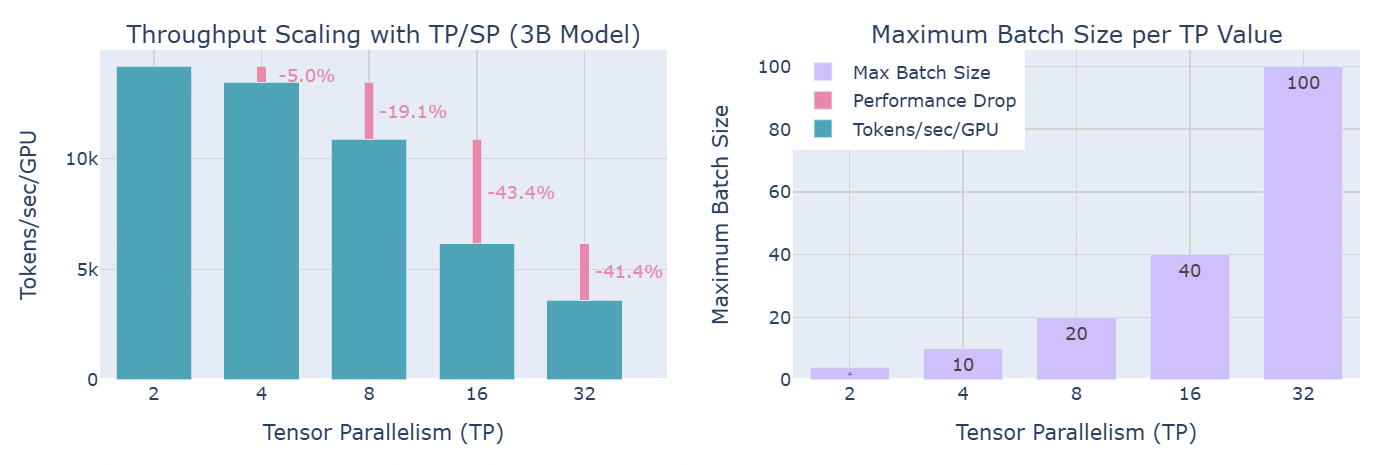 再次观察到,计算效率(左图)和内存容量(右图)之间的trade-off。虽然较高的并行度通过减少activations的内存,能够处理更大的批次大小;但它们也降低了每个GPU的吞吐量,特别是当并行度超过节点内GPU数量的阈值时。
再次观察到,计算效率(左图)和内存容量(右图)之间的trade-off。虽然较高的并行度通过减少activations的内存,能够处理更大的批次大小;但它们也降低了每个GPU的吞吐量,特别是当并行度超过节点内GPU数量的阈值时。
总结观察结果:
- 对于这两种方法,在从TP=8到TP=16时,性能出现最大降幅:因为这是我们从仅在单个节点(NVLink)内进行通信,转变为跨节点通信(EFA)的时刻;
- 使用TP+SP时,相较于TP,帮助处理更大的批次;
TP通过沿着隐藏维度拆分注意力和前馈操作,将activations分布在多个GPU上;而SP沿着序列维度拆分剩余的操作,进一步提高了activations的并行程度。
由于SP区域中的LayerNorm操作在不同的序列部分上进行,因此它们的梯度会在不同TP ranks之间有所不同。为了确保权重保持同步,我们需要在反向传播过程中,对它们的梯度进行all-reduce操作,类似于数据并行(DP)确保权重同步。然而,这只是一个小的通信开销,因为LayerNorm的参数相对较少。
然而,TP和SP也有两个限制: 1. 如果扩展序列长度,TP区域的activations内存仍然会膨胀; 2. 如果模型太大,无法适应TP=8,那么由于节点间连接的瓶颈,将出现巨大的性能下降。
我们可以通过上下文并行(Context Parallelism)来解决问题1),通过流水线并行(Pipeline Parallelism)来解决问题2)。接下来,先来看看上下文并行!
上下文并行(Context Parallelism):解决长序列的activations爆炸
通过张量并行(Tensor Parallelism)和序列并行(Sequence Parallelism),我们可以显著减少每个GPU的内存需求,因为模型的weights和activations被分布到多个GPU上。然而,当我们训练更长的序列时(例如,当序列长度扩展到128k或更多tokens时),仍然可能超出单个节点的内存容量,因为在TP区域内,我们仍然需要处理完整的序列长度。
此外,即使我们完全重新计算activations(带来大约30%的计算开销),仍然需要在layer boundaries处保留一些activations,其内存需求也会随着序列长度的增加而线性增长。接下来,看看CP如何帮助我们解决这个问题:
SP沿着序列维度拆分输入;但现在,将这种拆分应用到整个模型,而不是仅仅应用于模型中的SP区域。
拆分序列不会影响大多数模块,如MLP和LayerNorm(每个token都是独立处理的)。它也不需要像TP那样的昂贵通信(因为仅拆分输入,而不是权重矩阵)。就像DP一样,在计算梯度后,会启动一个all-reduce操作,来同步CP组中的梯度。
然而,一个重要的例外是:注意力模块。在注意力模块中,每个token需要访问所有其他序列token的键/值对(即使在causal attention中,也至少需要关注之前的所有token);因此,注意力模块需要在GPU之间进行完全通信,以交换必要的keys/values。
这个想法是intuitively expensive的。现在引入一个高效的key/value通信机制:Ring Attention。
Ring attention
首先,每个GPU启动一个异步通信操作,将其key/value pair发送至其他GPU;在等待其他GPU数据时,计算已存储在内存中数据的注意力分数。理想情况下,在计算完成之前,从另一个GPU接收到下一个key/value pair,这样GPU就可以在完成第一轮计算后,立即开始下一轮计算。(等待与计算重叠)。
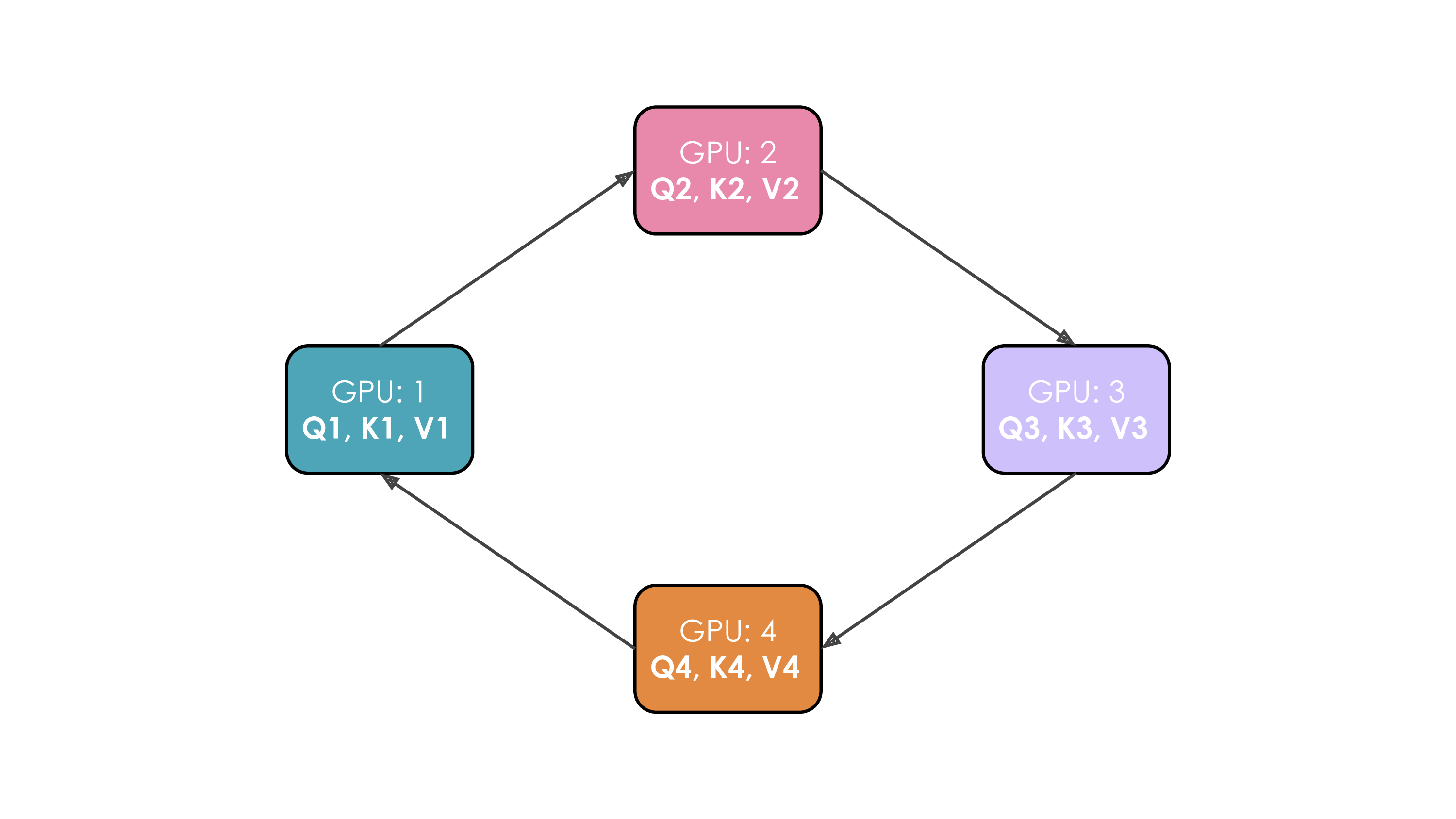
假设当前有4个GPU和一个4个token的输入。最初,输入序列沿着序列维度均匀拆分,因此每个GPU将只拥有一个token及其对应的Q/K/V值。假设Q1、K1和V1表示第一个token的query、key和value,这些数据位于第一个GPU上。注意力计算需要4个step才能完成。在每个step内,每个GPU执行以下三个连续操作:
- 将当前key/value以非阻塞的方式发送到下一个机器(除了在最后一个step);
- 本地计算注意力分数:运用当前的key/value值: \[ softmax(\frac{QK^{T}}{\sqrt{d}})*V \]
- 等待接收来自前一个GPU的key/value;返回第1步,更新当前的key/value为:刚从前一个GPU接收到的key/value。
然而,Ring Attention的简单实现,会导致一个问题:由causal attention矩阵形状引起的GPU负载不均。来看看casual attention mask的计算: 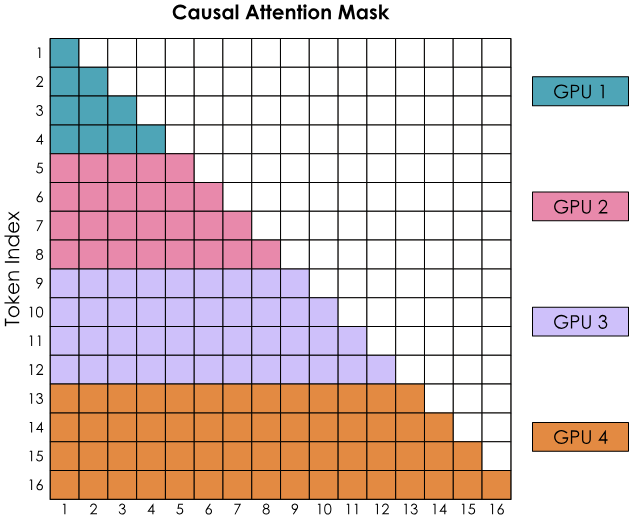 SoftMax是按行计算的,这说明:每当一个GPU接收到某行的所有token时,它就可以开始计算。可以看到,GPU1可以立即计算它,因为它从token 1到token 4开始,且GPU1实际上不需要从其他GPU接收任何信息;然而,GPU2需要等待第二轮,才能接收到token 1-4,从而拥有token 1-8的所有值。此外,GPU1似乎执行的工作远少于其他所有GPU。
SoftMax是按行计算的,这说明:每当一个GPU接收到某行的所有token时,它就可以开始计算。可以看到,GPU1可以立即计算它,因为它从token 1到token 4开始,且GPU1实际上不需要从其他GPU接收任何信息;然而,GPU2需要等待第二轮,才能接收到token 1-4,从而拥有token 1-8的所有值。此外,GPU1似乎执行的工作远少于其他所有GPU。
用什么方式平衡GPU负载呢?
Zig-Zag Ring Attention
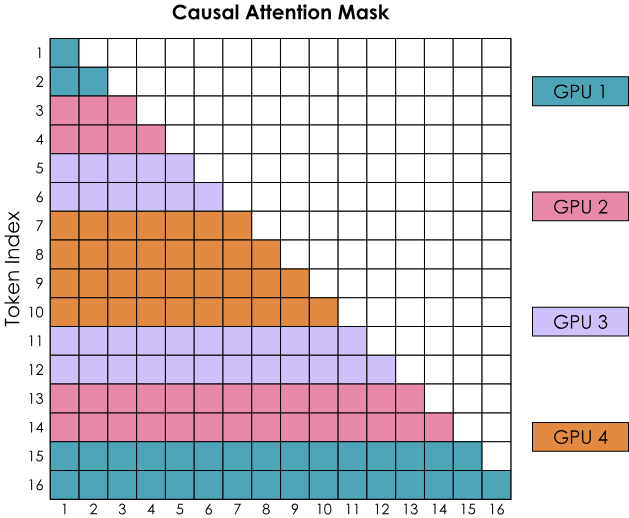
我们需要更好的方法来分配输入序列。这可以通过不完全按顺序将token分配给GPU,而是稍微混合一下顺序,使得每个GPU都有早期和晚期的token。这个方法被称为Zig-Zag Attention,在这种新的安排中,attention mask将展现更均匀的计算分布,(数一数被标记的方块,发现计算已经在所有GPU之间平衡分配)
同时看到,为了完成所有行,每个GPU都需要从其他GPU获取信息。
有两种常见方式来使计算和通信重叠,分别是: 1. 执行一般的all-gather,将每个GPU上的所有同时KV重新收集(类似ZeRO-3); 2. 按需将每个GPU上的key/value pair,逐个从一个GPU收集到另一个GPU。
- all-gather实现:所有GPU同时收集来自其他所有GPU的完整KV对
- 需要更多的临时内存,因为每个GPU必须同时存储完整的KV对;
- 通信一次性完成,但内存开销较大。
- All-to-All(Ring)实现:GPU以类似环形的模式交换KV对,一次交换一块
- 更节省内存,因为每个GPU只需要临时存储一块额外的KV对;
- 通信被分散,与计算重叠


TP在跨节点时扩展性不好,如果模型权重无法轻松放入一个节点该怎么办呢?接下来,进入另一种并行方式:Pipeline Parallelism(流水线并行),来解决这个问题!
流水线并行(Pipeline Parallelism)
在TP部分,我们看到,当尝试将TP扩展到超出单节点内GPU数量(通常为4或8)时,性能会受到一个低带宽网络——“节点间连接”的强烈影响。可以通过对集群中多个节点进行基准测试清晰地看到这一点(每个节点有8个GPU): 节点间通信带宽测量,展示了不同节点数下的AllReduce、AllGather和ReduceScatter操作的中位数(线)和5th-95th百分位范围(阴影区域)。 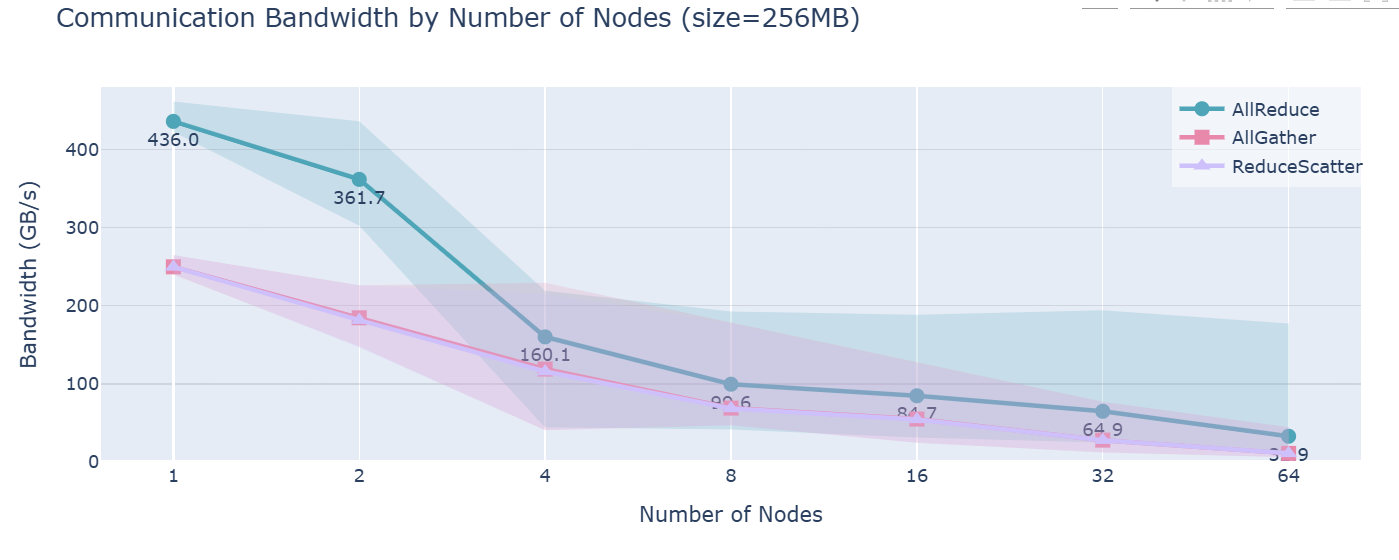
SP和CP可以帮助处理长序列,但如果内存问题的根本原因不是序列长度,而是模型本身的大小,它们的帮助就不大了。对于大型模型(如70B+),仅仅模型权重的大小就足以超出单节点上4-8个GPU的限制。我们可以通过引入第四个(也是最后一个)并行维度:“流水线并行性(Pipeline Parallelism)”来解决这个问题。
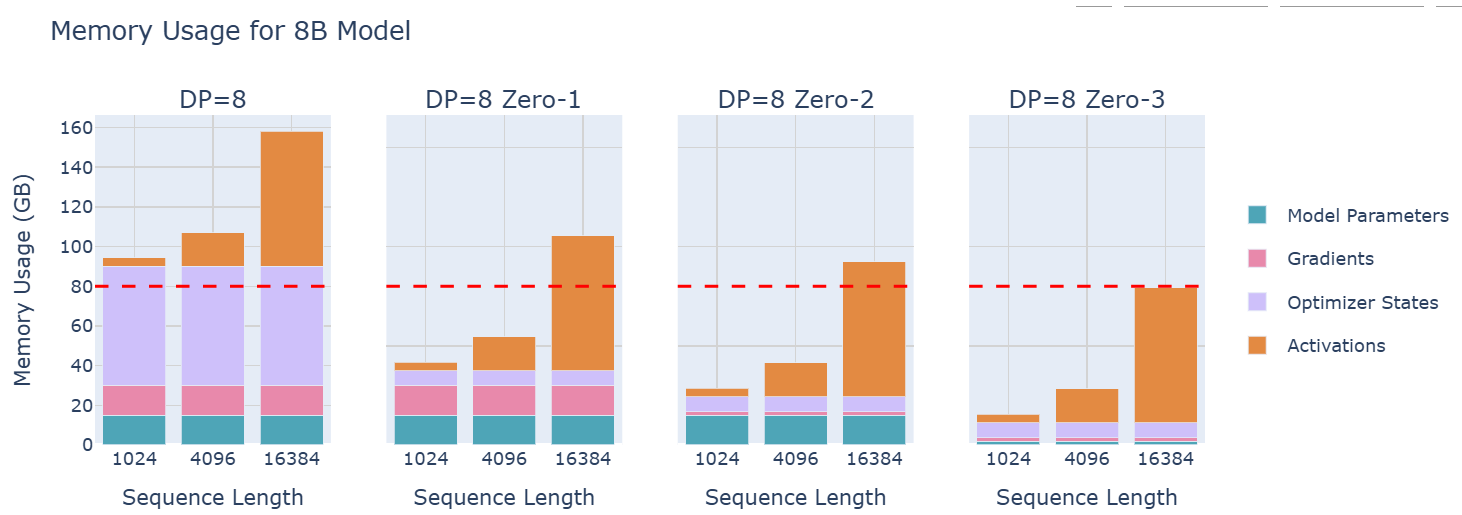
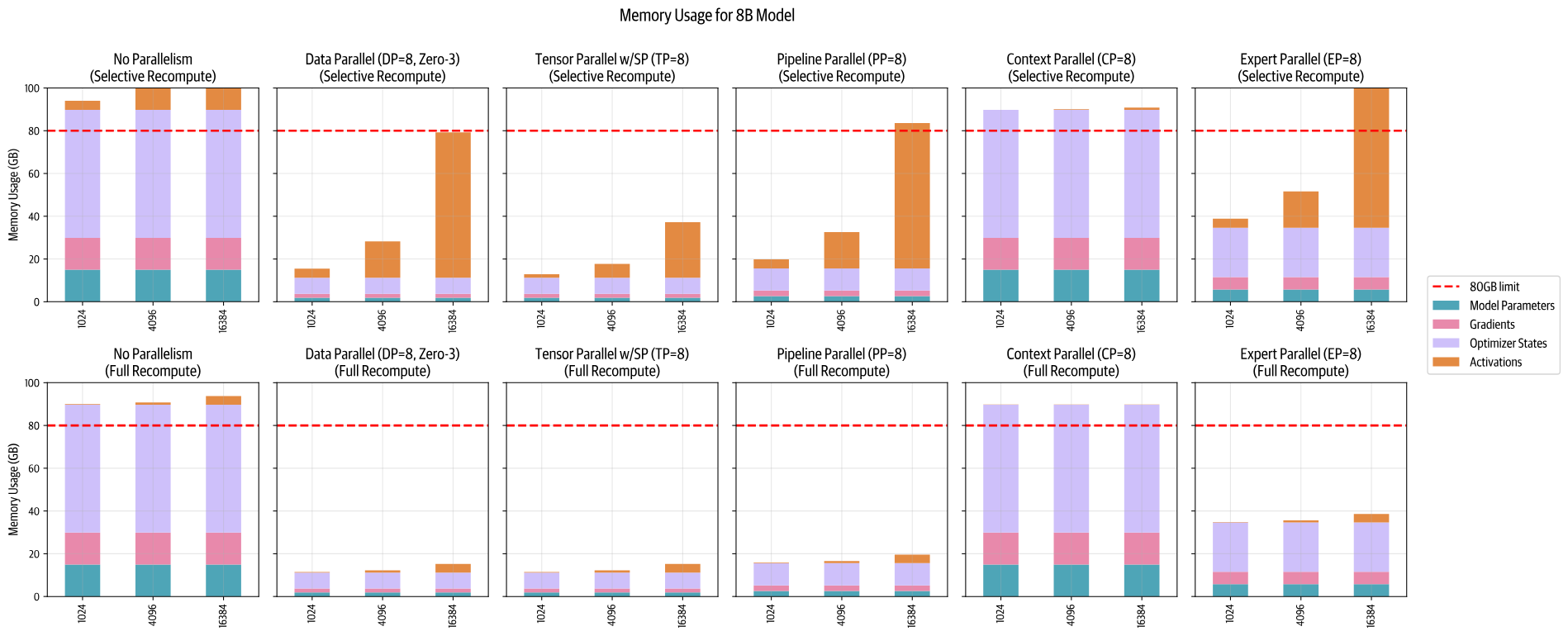
PP是一种简单但强大的技术——我们将模型的层划分到多个GPU上!例如,如果我们有8个GPU,我们可以将第1-4层放在GPU 1上,将第5-8层放在GPU 2上,依此类推。这样,每个GPU只需要存储和处理模型的一部分层,显著减少了每个GPU的内存需求。让我们看看在一个8B模型上的流水线并行性如何影响内存使用情况:
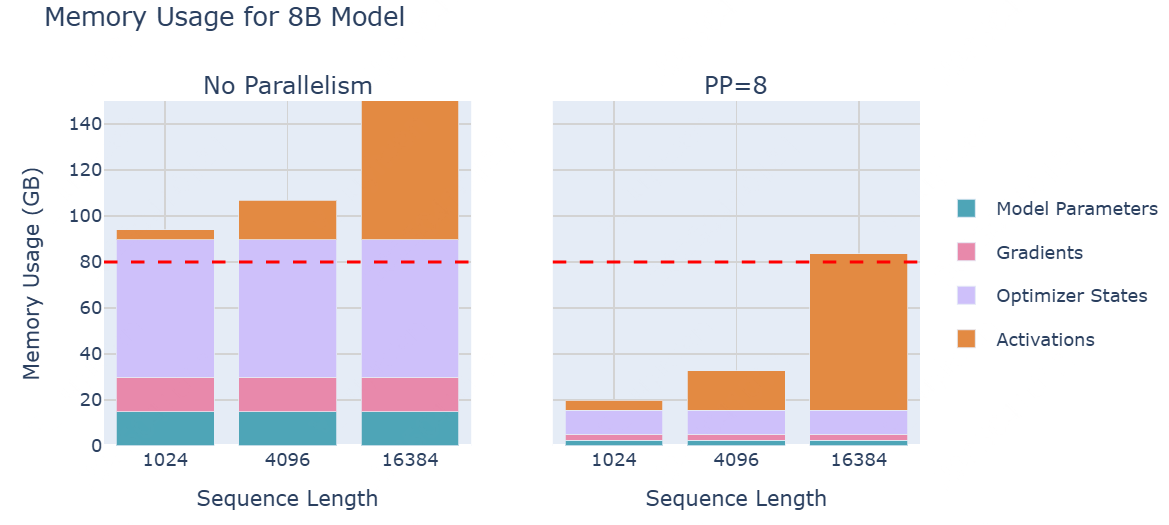
从上图可知:尽管模型参数在GPU之间得到了很好的分配,但每个GPU的activations内存仍然保持不变!(每个GPU仍然需要处理完整的批次数据,只不过它们处理的是不同的层)。一个GPU的层产生的activations会被传递到下一个GPU,以继续前向传播。
这引入了一种新的通信模式:与DP中通过ZeRO-3传递参数不同;现在通过Pipeline,在GPU之间顺序地传递activation tensors。
在不同节点上拆分层
假设我们简单地将模型的层分布在多个设备上,例如:第一块GPU处理模型的前几层,第二块GPU处理模型的后几层,依此类推。这样,模型的前向传播过程转为:按顺序将数据批次传递给每个计算设备,从而依次使用每个设备进行计算。
这种做法的直接优势之一是:所需的互联带宽较低,因为只在模型深度的几个位置传递中等大小的activations;(而TP中,通信发生在每一层的多个位置)
然而,PP的主要挑战在于:如何高效地绕过PP的顺序性质,以确保GPU始终保持忙碌状态,即保持:计算与通信的重叠状态。 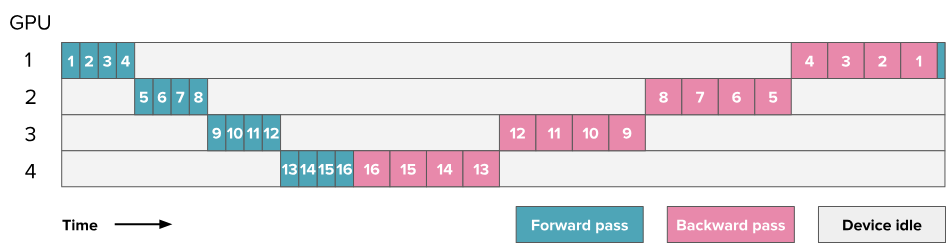 上图中,空闲时间用灰色表示,命名为“bubble”。bubble造成的时间损失是多少呢?
上图中,空闲时间用灰色表示,命名为“bubble”。bubble造成的时间损失是多少呢?
假设\(t_f\), \(t_b\)分别是前向和反向传播的时间,针对一个microbatch和管道的一个阶段进行测量((一个简单的假设是:\(t_b=2*t_f\)),如果实现完美的并行化,理想时间为:\(t_{id}=t_b+t_f\).
但是,考虑到bubble的存在,额外的时间为: \[ t_pb=(p-1)\times (t_b+t_f) \] 其中,\(p\)是pipeline并行度(GPU数量)。那么bubble时间和理想时间的比率为:\(p-1\)。即:随着更多GPU的加入,bubble时间增加,GPU的时间利用率下降。
有哪些减少bubble的方法呢?先看看第一个:all-forward-all-backward (AFAB) 调度。
all-forward-all-backward (AFAB) 调度:改善activations的内存占用
将批次分成更小的部分,这些部分可以并行或几乎并行地处理(就像在DP中做的那样)。现在,当第二个GPU忙于处理microbatch 1时,第一个GPU可以开始处理microbatch 1。以下是使用8个microbatch的调度示例: 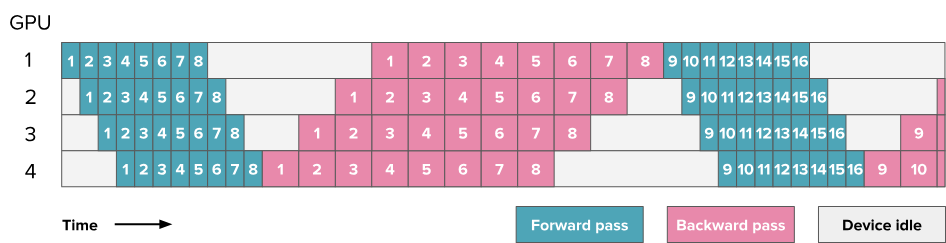
首先执行所有的前向传播,然后仅执行所有的反向传播。其优点是:前向和反向步骤仍然是一般性的顺序操作,因此保留了模型训练代码的一般组织方式。AFAB是PP的最简单的实现之一。
处理\(m\)个microbatch的理想时间为:\(t_{id}=m\times(t_f+t_b)\);
bubble时间比率为:\(r_{bubble}=\frac{(p-1)\times(t_f+t_b)}{m\times(t_f+t_b)}=\frac{p-1}{m}.\)
通过增加更多的microbatch,可以减少bubble的大小,将其缩小\(m\)倍。
尽管bubble令人烦恼,但还有一个更大的问题:当前需要将所有的activations存储在内存中,直至到达反向传播阶段,这会导致在PP中快速出现内存爆炸。那么,我们能否做得更好?
One-forward-one-backward(1F1B)调度 和 LLama 3.1 schemes
1F1B的中间稳定状态为:交替执行一次前向传播和一次反向传播。其理念是尽早开始执行反向传播。调度如下图: 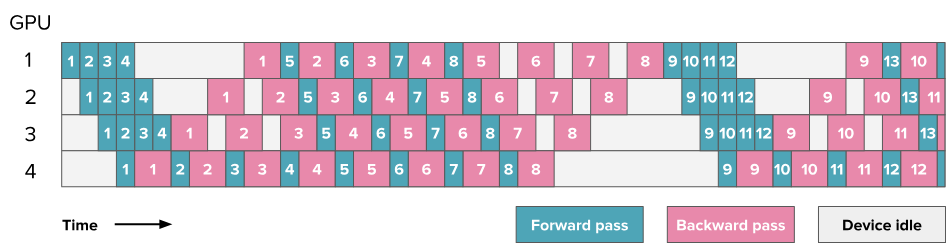 bubble的大小相同,因此训练效率没有显著提高。然而,只需要存储\(p\)个microbatch的activations(\(p\)为pipeline并行度),无需存储\(m\)个microbatch的activations。从而减小AFAB调度中的内存爆炸压力。
bubble的大小相同,因此训练效率没有显著提高。然而,只需要存储\(p\)个microbatch的activations(\(p\)为pipeline并行度),无需存储\(m\)个microbatch的activations。从而减小AFAB调度中的内存爆炸压力。 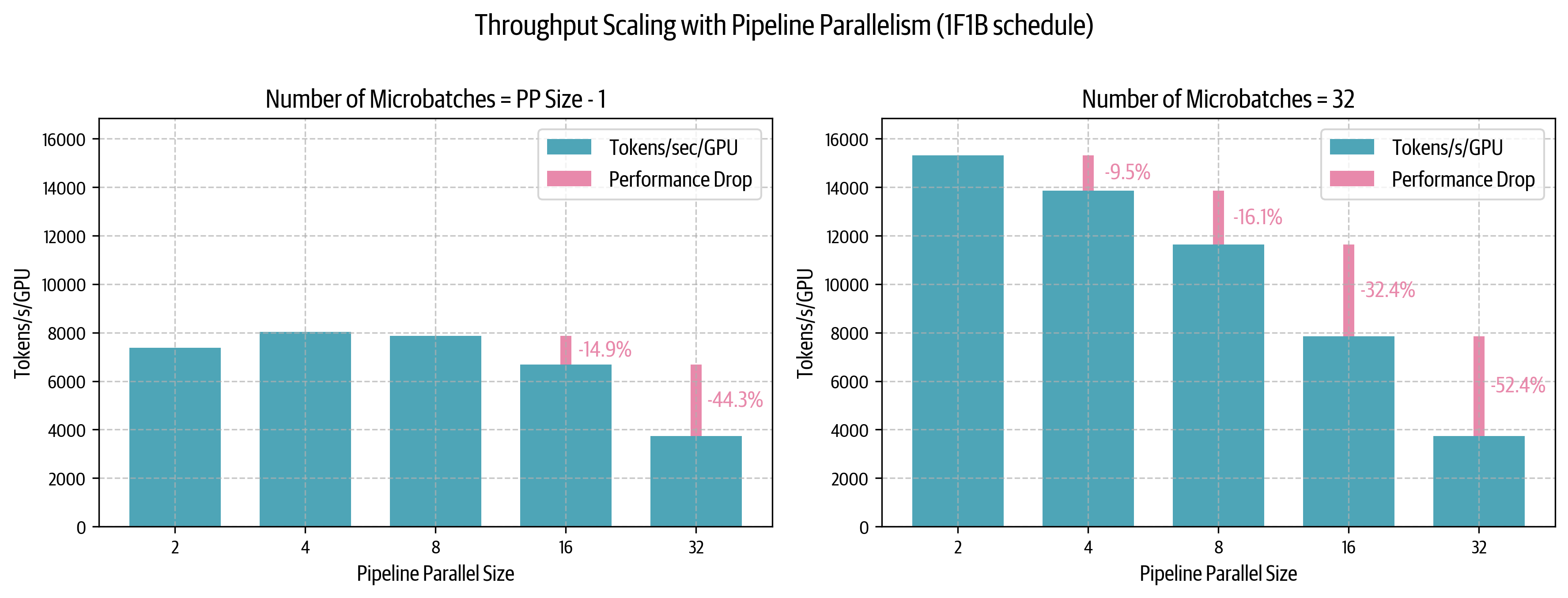 在左图中:
在左图中:
- \(m\leq p-1\)时,bubble的存在导致性能较低(即使扩展\(p\),性能也下降);
- \(m=32>>p-1\)时,可以改善低pipeline并行度下的性能。
实际上,由于最终受限于global batch size的影响,不能无限地增加microbatch的数量,以保持\(m>>p-1\)的比例。
可以观察到,在左图中(microbatch数量较少时),从一个节点(\(p=8\))扩展到两个节点(\(p=16\))时,性能仅下降14%;TP在类似跨节点场景下,性能下降约43%)。因此PP非常适合分布式训练。
1F1B改善了activations的内存使用;但是由\(r_{bubble}=\frac{p-1}{m}\)可知,bubble大小与\(p\)成比例,GPU计算依然处于空闲状态,是否有更智能的调度策略呢?
交错阶段(Interleaving Stages):改善bubble大小
到目前为止,我们是通过沿模型深度维度简单地切分模型,例如将第 1-4 层放在第一个 GPU 上,将第 5-8 层放在第二个 GPU 上。但其实还有其他方式可以切分我们的层,例如将奇数层(1、3、5、7)放在第一个 GPU 上,将偶数层(2、4、6、8)放在第二个 GPU 上。
这可以看作是一种“循环管道”的方式,其中microbatch将从一个 GPU 移动到下一个 GPU,在模型的前向传播过程中不断循环。 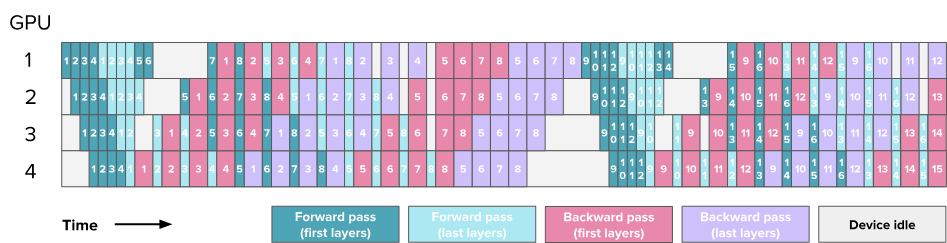
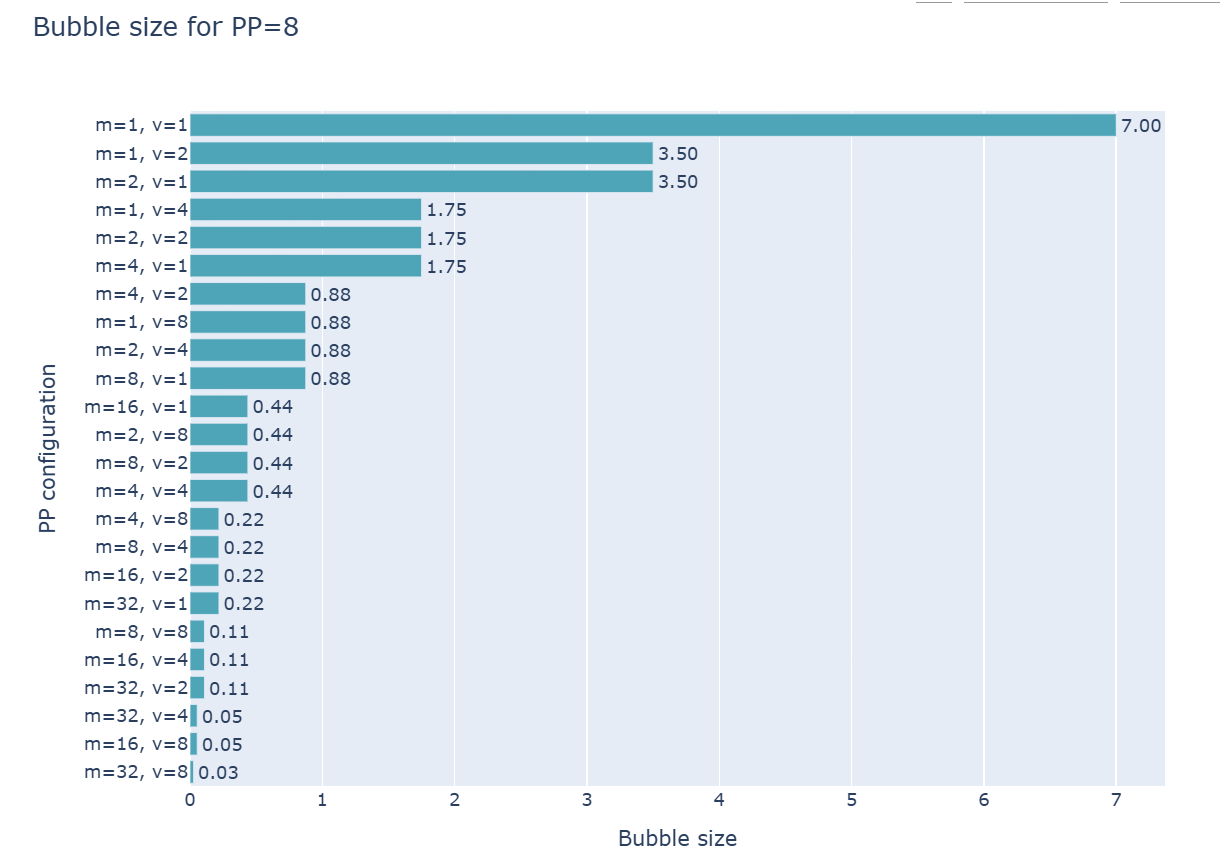
随着模型在每个 GPU 上多次经过,出现了额外的通信操作,这是因为之前只需要计算只需传递一次,现在需要传递多次。每个前向和反向传播过程被切分为\(v\)个部分(\(v\)是每个 GPU 上的stages或model chunks的数量)。则有: \[ t_{pb}=\frac{(p-1)\times(t_f+t_b)}{v} \\ r_{bubble}=\frac{1}{v}\frac{(p-1)\times(t_f+t_b)}{m\times(t_f+t_b)}=\frac{p-1}{v\times m} \] 现在,我们通过增加microbatch数量和交错阶段数量,来减小bubble大小(当然,通信量也会增加一个因子\(v\))。 下图为\(p=8\)时的bubble大小。其中:
- \(m=1, v=1\):普通的流水线并行;
- \(v=1\):AFAB或1F1B;
- \(v\neq 1\):交错阶段。
GPU调度是一个值得深入探讨的问题。有两种方式:
- 深度优先:优先让较早的micro-batches通过更靠后的layers:尽快关闭前向和反向循环,即尽快让batches从模型中输出;
- 广度优先:优先让较后的micro-batches通过更靠前的layers:尽可能填满pipeline。
Llama3.1中的PP策略:1F1B+交错阶段,depth-first和bread-first可选。
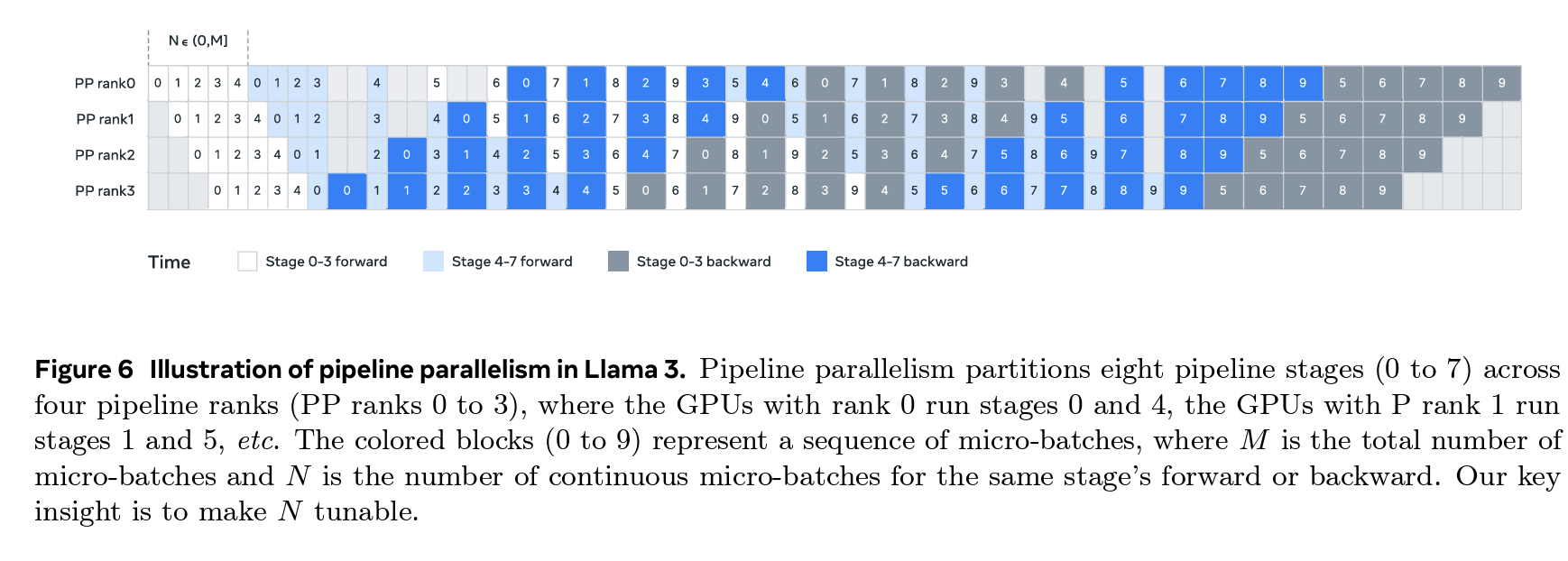
然而,PP的策略优化依然进行中,在DeepSeek V3/R1中,提出了一种方法,将bubble大小降低至几乎为零!
Zero Bubble和双管道(DualPipe)
核心理念是:将涉及的操作划分得更精细,以最有效的方式进行交错。
Zero Bubble是DualPipe的前身。ZeroBubble 的基本观察是,矩阵乘法的反向传播,涉及两个独立的操作:输入的反向操作(B)和权重的反向操作(W):
输入的反向传播,是进行执行更低层反向传播的必要条件;然而,权重的反向传播则不是(只要在优化步骤之前执行即可),如下图所示: 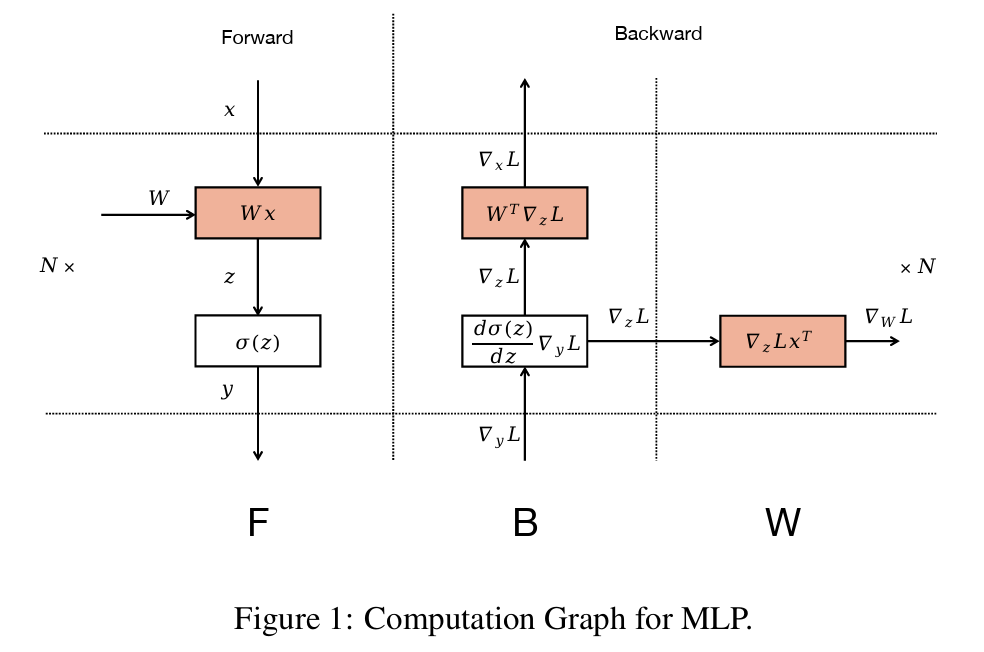
因此,权重的反向操作(W),可安排在对应B之后的任何位置;这允许策略性地安排W,以填补pipeline中的buble。
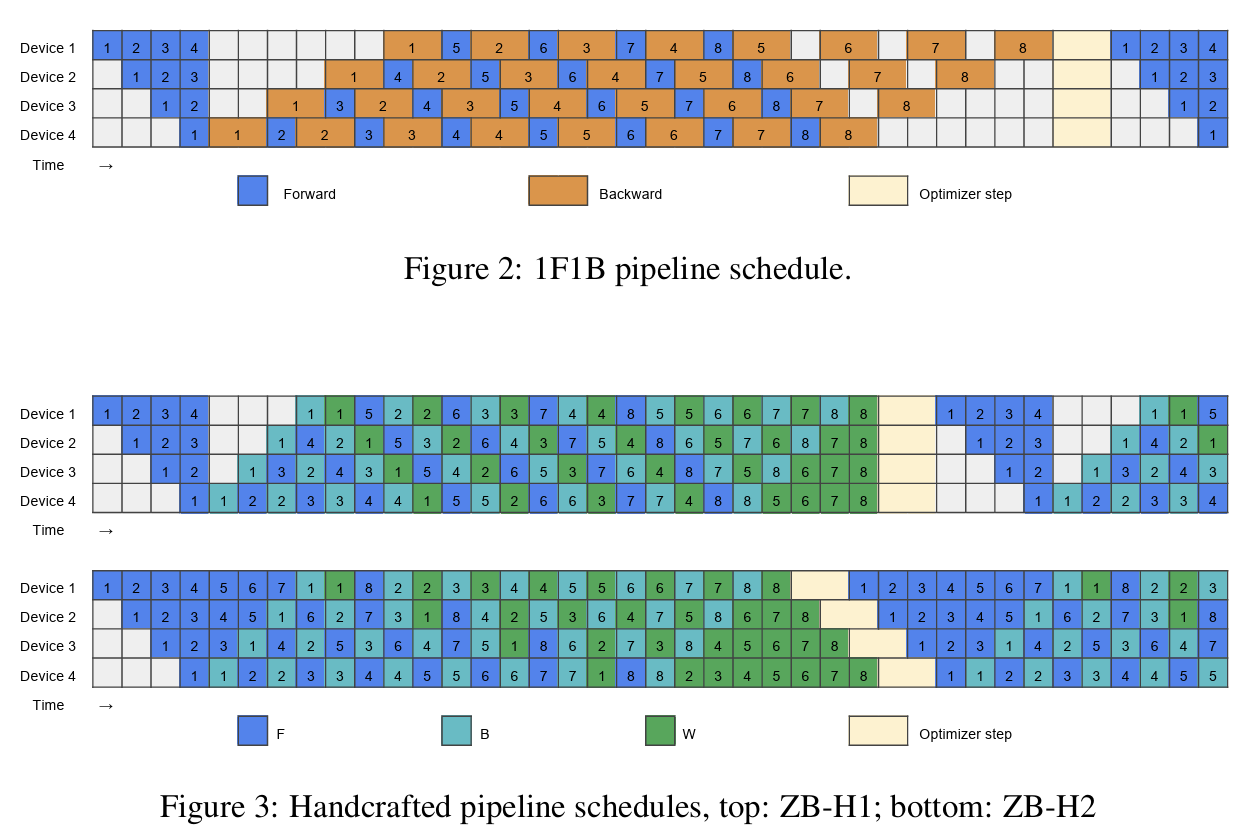
- 1F1B调度:交替进行前向/反向传播,但反向传播为较粗粒度;
- ZeroBubble的两个变种:将反向传播拆分为:B和W的细粒度操作(最后一个称为ZB-H2,是一个理论上的Zero Bubble调度)
DeepSeek 的 DualPipe 在其 V3 技术报告中,引入了这一分解方法的扩展,增加了两个流从 PP 维度的两端传播的情况,这些流被交替安排,以进一步最小化 GPU 的空闲时间。如下图:
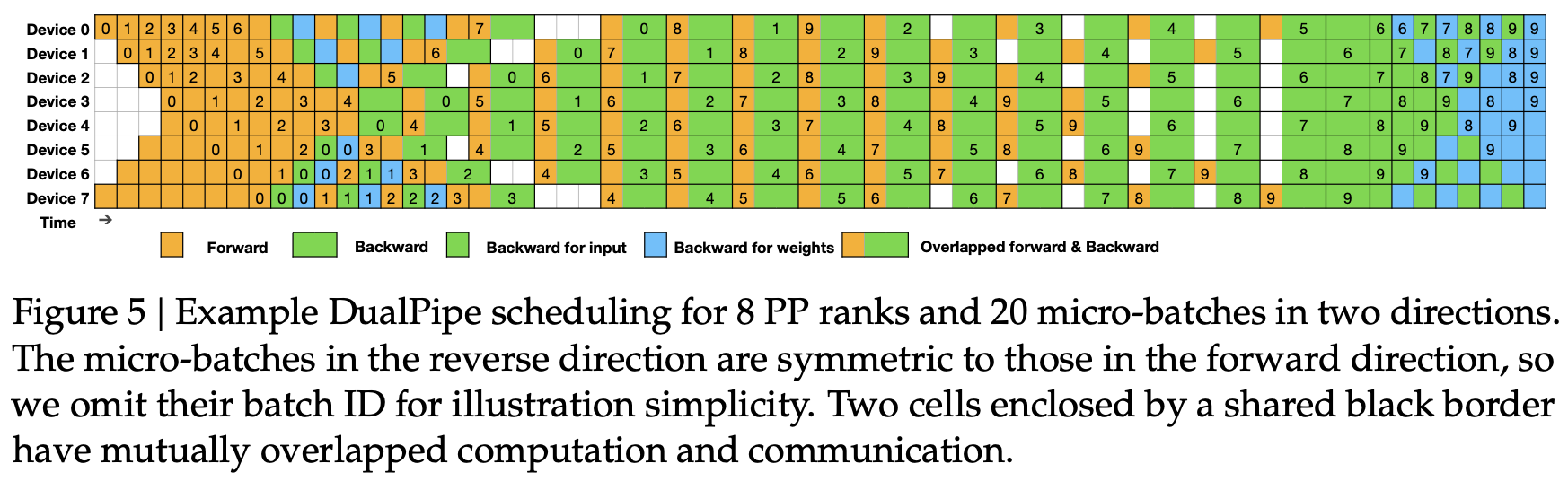
最后来到专家并行(Expert Parallelism),其提供高效训练大模型的并行策略。
专家并行(Expert Parallelism)
MoE由两个关键部分组成:
- 稀疏MoE层:替代Transformer中的前馈网络(FFN)层,包含若干个expert,每个expert本身是一个独立的神经网络。
- gate network和router:决定哪个tokens发送到哪个expert(可以将一个token发送给多个expert)。roter由学习得到的参数组成,与网络的其他部分一同预训练。 > MoE特点:(与稠密模型相比) > * 训练:预训练速度更快;但在微调阶段常面临泛化能力不足,易引发过拟合; > * 推理:由于只使用一部分参数,MoE推理速度快于相同参数量的稠密模型;但需要将所有expert加载至内存,对显存要求高。
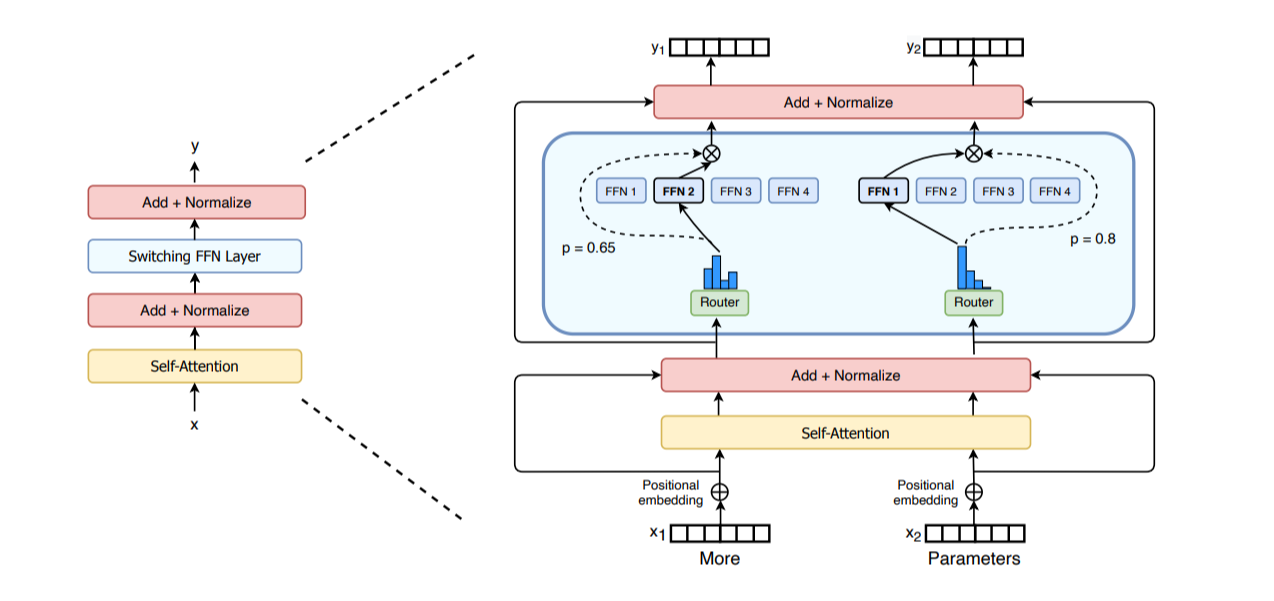 > MoE特点:(与稠密模型相比) > * 训练:预训练速度更快;但在微调阶段常面临泛化能力不足,易引发过拟合; > * 推理:由于只使用一部分参数,MoE推理速度快于相同参数量的稠密模型;但需要将所有expert加载至内存,对显存要求高。
> MoE特点:(与稠密模型相比) > * 训练:预训练速度更快;但在微调阶段常面临泛化能力不足,易引发过拟合; > * 推理:由于只使用一部分参数,MoE推理速度快于相同参数量的稠密模型;但需要将所有expert加载至内存,对显存要求高。EP的理念是:运用MoE框架,实现expert维度上的并行。由于前馈层完全独立,可以将每个expert的前馈层,放在不同的worker上。(比TP更轻量,因为无需拆分矩阵乘法,只需将token的隐藏层通过router导引至相应expert)
现实中,EP通常与其他并行策略一起使用(例如DP),因为EP只影响MoE层,不拆分tokens(CP会沿着序列维度拆分tokens)。 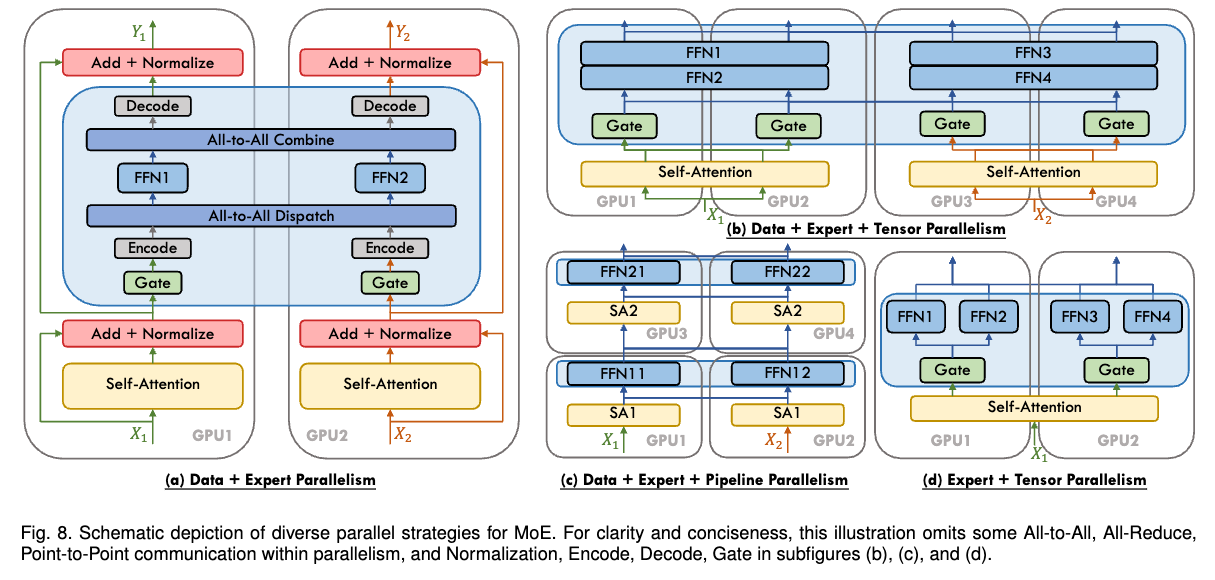
5D并行
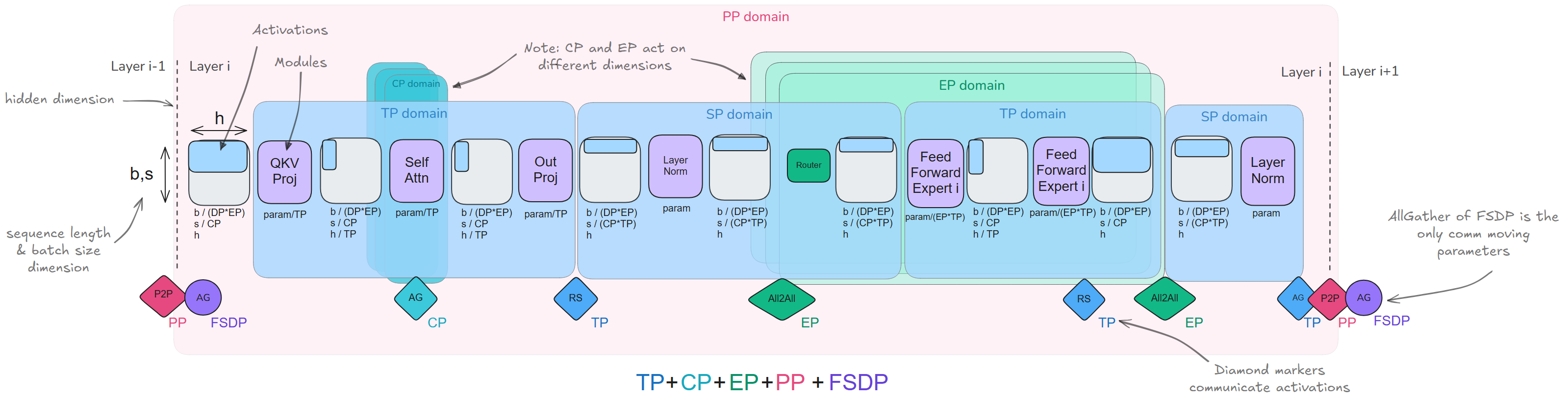
当前,已经学习了扩展模型训练的5种并行策略:
- 数据并行(DP):沿着batch维度
- 张量并行(TP):沿着隐藏层维度
- 序列/上下文并行(SP/CP):沿着sequence维度
- 流水线并行(PP):沿着model layers维度
- 专家并行(EP):沿着MoE experts维度
以及三种可以与DP结合使用的 ZeRO 策略,用于节省内存: * ZeRO-1 – 在 DP 副本之间,对optimizer states分片 * ZeRO-2 – 在 DP 副本之间,对optimizer states, gradients分片 * ZeRO-3 – 在 DP 副本之间,对optimizer states, gradients, parameters分片
我们应该如何高效地组合这些策略,哪些策略应该分开使用?
PP vs. ZeRO-3
PP和ZeRO-3都是将模型weights划分到多个GPU上,沿着模型深度轴,执行计算/通信(例如在 ZeRO-3 中,在计算时预取下一层)。这说明:完整的层操作都在每个设备上进行(而不像 TP 或 EP ,在子层单元上执行计算)。
PP和ZeRO-3的区别如下:
| Aspect | ZeRO-3 | Pipeline Parallelism (PP) |
|---|---|---|
| 每个计算单元存储 | layer的一部分 | 整个layer |
| 使用通信传输的内容 | 权重 | 激活值 |
| 协调 | 与模型无关 | 与模型无关 |
| 实现挑战 | 复杂的模型分区和通信处理 | 复杂的调度策略 |
| 扩展性 | 偏好大批量和长序列,以隐藏通信 | 偏好较大grad_acc以隐藏bubble |
ZeRO-3 和 PP 解决的是相同的挑战,但涉及不同的方法,其结合使用在实践中并不常见;ZeRO-1 和 ZeRO-2 主要关注优化器状态和梯度,很容易地与PP结合。
TP(+SP)
TP与SP是天然互补的,可以与PP和ZeRO-3结合使用。因为它依赖于矩阵乘法的分配性质,这使得weights和activations可以被分割并独立计算,之后再进行合并。 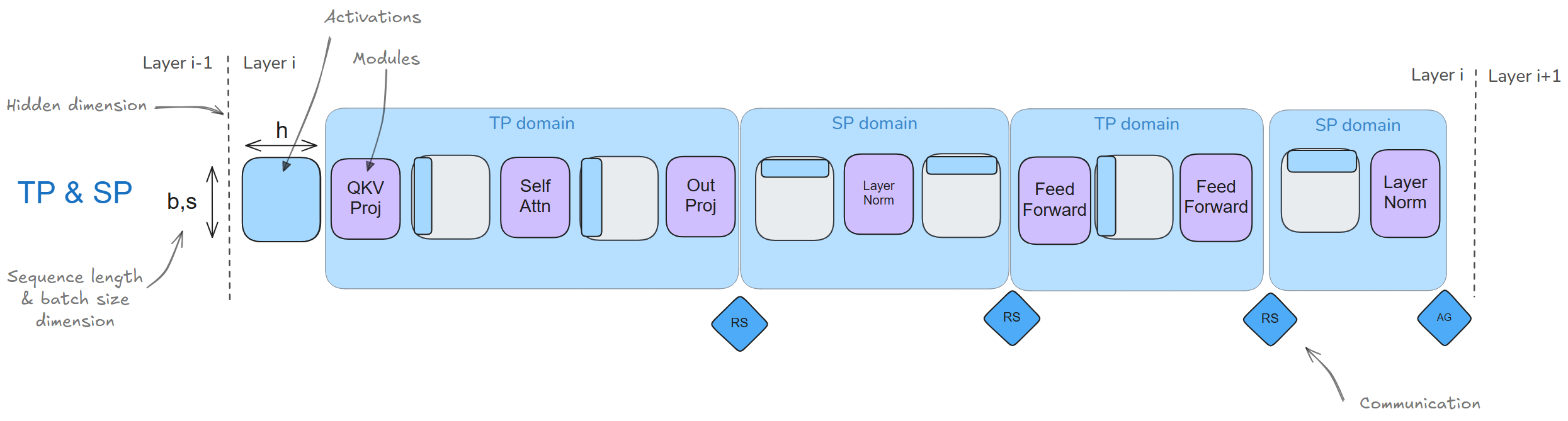 单独使用TP的两个限制:
单独使用TP的两个限制:
- 通信开销:由于TP的通信操作是计算关键路径的一部分,因此它在某个点之后难以很好地扩展,此时通信开销开始占主导地位。
- 模型特定的分割要求: 与ZeRO和PP不同,TP需要确定activations的切分策略—有时是在隐藏维度(TP区域),有时是在序列维度(SP区域)—这使得实现变得更加繁琐。
因此,TP通常用于节点内部通信;ZeRO-3或PP用于跨节点并行(需要更少的带宽(对于PP),或更容易与计算重叠(对于ZeRO-3))。
CP/EP
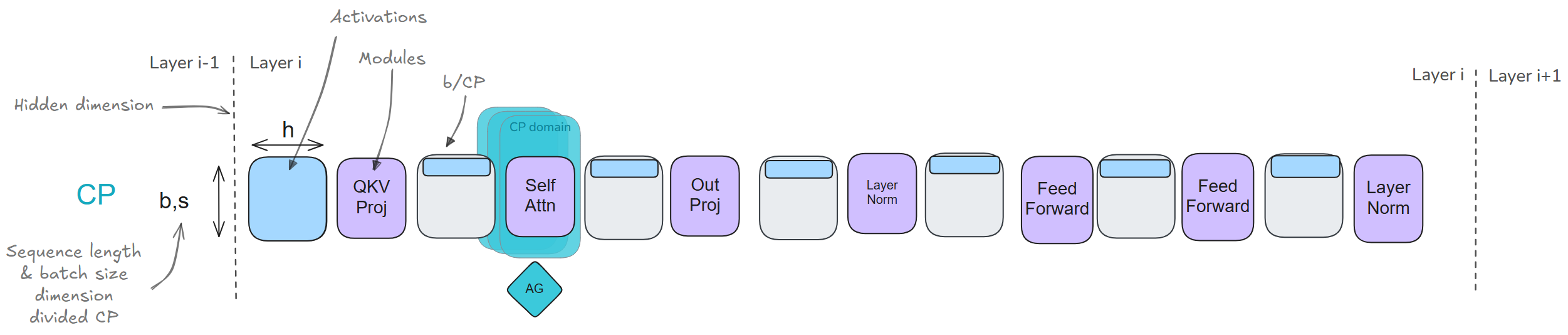
CP和EP均有利于activations的切片,可视作TP的互补。CP解决了长序列的训练问题;EP支持分布式MoE训练。
CP通过沿着序列维度切分activations,并使之分布在不同GPU上,解决长序列的训练问题。虽然大多数操作(如MLP和LayerNorm)可以独立处理这些分割的序列;但注意力层则需要通信,因为每个token都需要访问来自整个序列的keys/values(通过Ring Attention处理,使得计算和通信重叠)。 > CP在扩展到极端序列长度(128k+ tokens)时尤为价值:此时即使使用完全的activations重计算,单个GPU的内存需求也难以承受。
EP专门解决训练MoE的挑战:将experts分布在多个GPU上;在计算期间,动态地将tokens导向相关的expert。关键通信操作是:all-to-all操作,即将token通过router导向分配的expert,并将结果收集回来。尽管当前操作引入通信开销,但它使得模型容量显著扩展:因为每个token在推理(和训练)过程中,只由总参数的一个较小部分处理。  > EP和DP在输入处理上具备相似性:因此通常将EP视为DP的一个子方法;区别在于:EP使用专门的expert routing处理输入;而DP让所有GPU通过相同的模型副本处理输入。
> EP和DP在输入处理上具备相似性:因此通常将EP视为DP的一个子方法;区别在于:EP使用专门的expert routing处理输入;而DP让所有GPU通过相同的模型副本处理输入。
总结
总结以上并行策略对模型各个子部分的影响:
- TP(+SP):通过切分weights和activations,影响整个模型的计算;
- CP:主要影响注意力层(需要跨序列通信),其他层可以独立处理被分割序列;
- EP:主要影响MoE层(替代了标准的MLP块),其他注意力层和组件保持不变;
- PP和ZeRO:不特别针对任何子模块或组件(唯一的例外是:PP中modules和layers需要平衡,因此第一层和最后一层通常会因为附加的嵌入层而被特别处理)
| TP+SP | CP | EP |
|---|---|---|
| 在hidden/seq维度上分割weights和activations | 在seq维度上分割activations | 分割expert的weights和activations |
| 用于矩阵乘法操作(column/row linears)的通信 | 用于注意力key/values的通信 | 用于token路由到expert的通信 |
| 针对模型特定实现 | 除注意力外,与模型无关 | 除MoE层外,与模型无关 |
| 偏好高带宽的节点内通信 | 偏好长序列长度 | 需要MoE模型 |
| 方法 | 内存节省 | 并行/切分维度 | 缺点 |
|---|---|---|---|
| DP | Activations (降低local batch size) | Batch | 受限于max batch size |
| PP | Model parameters | Model layers | bubble和复杂调度 |
| TP/SP | Model parameters和activations | Hidden dimension / Sequence length | 高带宽通信 |
| CP | Activations | Sequence length | 注意力模块增添额外通信 |
| EP | Experts parameters | Expert dimension | 需要MoE layers, 增添额外routing通信 |
| ZeRO-1 | Optimizer states | 在DP副本之间切分 | 额外的参数通信 |
| ZeRO-2 | Optimizer states and gradients | 在DP副本之间切分 | 额外的参数通信 |
| ZeRO-3 | Optimizer states, gradients, and model parameters | 在DP副本之间切分 | 额外的参数通信 |
