并行训练系列:2. 数据并行上篇(DP,DDP)
数据并行(DP)
思想:将模型复制到多个GPU上;在每个GPU上,对不同的micro batches执行前向/反向传播。 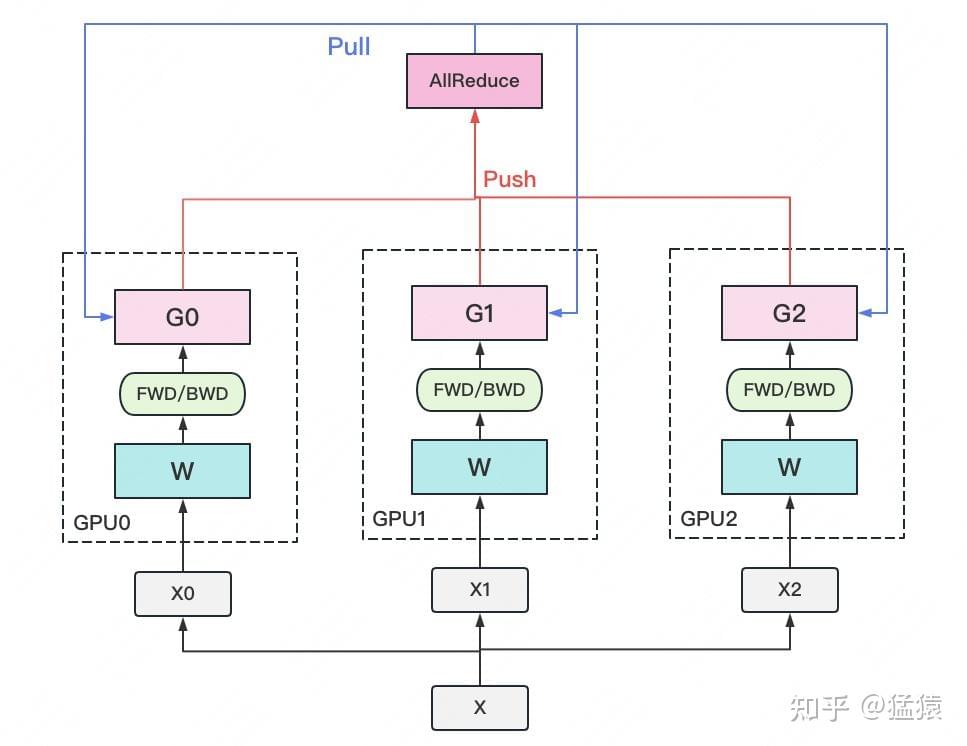
- 准备:在每个 GPU 上都拷贝一份完整的模型参数,将一个数据 batch 均分为多个 micro-batch,分别拷贝到不同 GPU 上(DP 分片);
- 前向传播/反向传播:每个 GPU 上对不同的 micro-batch 分别执行前向/反向传播,计算得到梯度 G;
- 聚合并下发梯度(All-Reduce): 每个 GPU 将本地梯度 G 发送给单个 GPU 做聚合(或者在不同的 GPU 上聚合梯度的某些部分);再将平均后的梯度下发到所有 GPU;

- 本地参数更新:所有 GPU 利用下发的梯度完成本地参数更新。
实现 DP 的经典框架为参数服务器:计算 GPU 称为 Worker,梯度聚合 GPU 称为 Server。
- Worker 和 Server 是逻辑概念,分别可以对应一块或多块物理意义上的 GPU(当前讨论的基本都是对应一张 GPU 的情况);
- Server 可以只做梯度聚合,也可以梯度聚合+全量参数更新一起做(当前讨论前一种情况);
- 实际应用中为减少通讯量,选择一个 Worker 同时作为 Server。
由第2点出发:能否将梯度聚合分布在多个 GPU 上完成呢?由此引出 Ring-AllReduce 算法。
由第3点出发:如果只选择一个 Worker 作为 Server,多机场景中 Server 将成为性能瓶颈。对于\(m\)个 Worker,将所有梯度发送到Server 需要\(O(m)\)时间;如果将 Server 数量增加到\(n\),每个 Server 只需要存储\(O(\frac{1}{n})\)个参数,总时间优化为\(O(\frac{m}{n})\).
受到通信负载不均的影响,DP一般用于单机多卡;而上述两种优化都利于将训练拓展到多机场景。
分布式数据并行(DDP)
Ring-AllReduce(环同步)
考虑下图中的4路 GPU 服务器:
- CPU 作为参数服务器:每个GPU通过 PCIe 链路连接到主机CPU,该链路最多只能以16GB/s的速度运行。速度太慢。
- 每个 GPU 具有6个 NVLink 连接,每个NVLink连接都能够以300Gbit/s进行双向传输;相当于每个链路每个方向约300/8/2=18GB/s。简言之,聚合的 NVLink 带宽明显高于 PCIe带宽,采用 GPU 作为参数服务器更佳。
- 单个 GPU 作为参数服务器:将其中3个 GPU 的梯度发送到第4个 GPU 上需要30毫秒(每次传输需要10毫秒=160MB/16GB/s)。再加上30毫秒将权重向量传输回来,总共需要60毫秒;
- 参数服务器分布在所有 GPU 上:将梯度分为4个部分,每个部分为40 MB,现在可以在不同的 GPU 上同时聚合每个部分。因为 PCIe 交换机在所有链路之间提供全带宽操作,所以传输需要2.5*3=7.5毫秒,(而不是30毫秒),同步操作总共需要15毫秒。
 假设所有梯度共需160 MB。
假设所有梯度共需160 MB。
研究结果表明最优的同步策略是将网络分解成两个环,并基于两个环直接同步数据。 
Ring-AllReduce 同步方法如下:给定由\(n\)个计算节点(或GPU)组成的一个环,每个节点向其左邻居发送部分梯度,直到在其右邻居中找到聚合的梯度。将梯度分为\(n\)个块,并从节点\(i\)开始同步块\(i\)。因为每个块的大小是\(\frac{1}{n}\),所以总时间是\(\frac{n-1}{n}\approx 1\)。即:增大环的大小时,聚合梯度所花费的时间不会增加。
理论时间在实践中通常会差一些,因为深度学习框架无法将通信组合成大的突发传输。
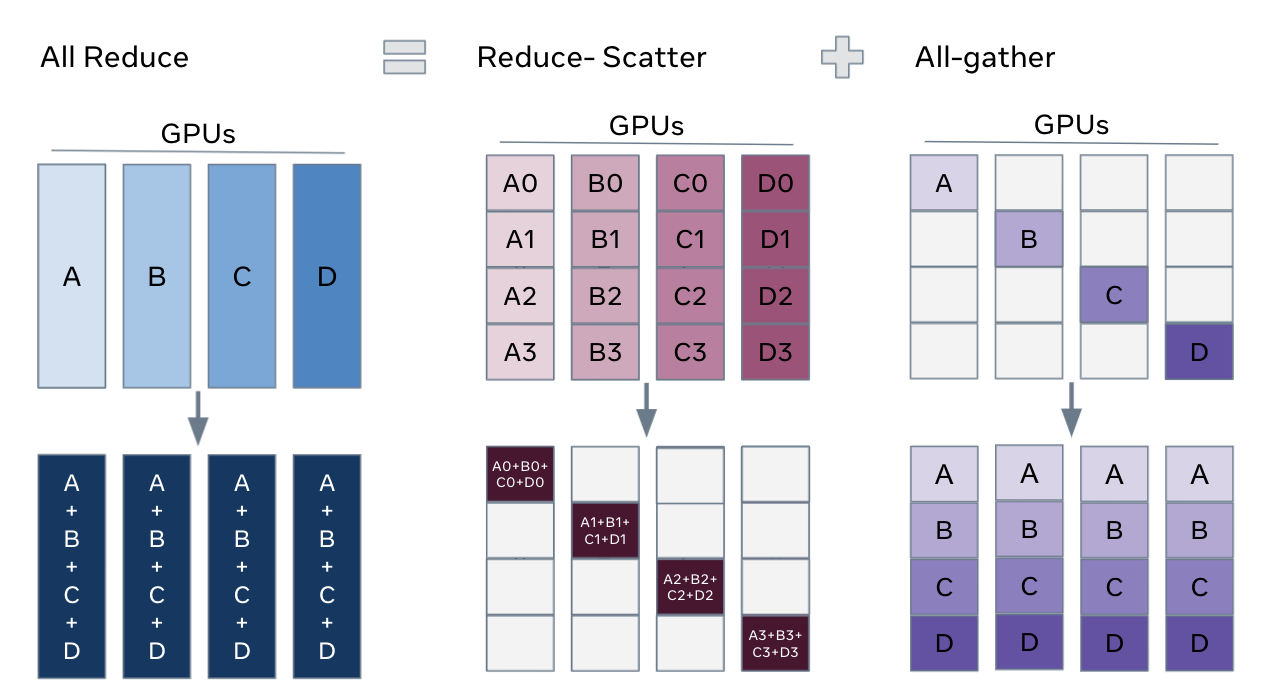
Ring-AllReduce 通信量分析
假设模型参数 W 的大小为 \(\psi\),GPU 个数为 \(N\)。则梯度 G 总大小为\(\psi\),每个梯度块的大小为\(\frac{\psi}{N}\)。对于单个 GPU(只计算发送通信量):
- Reduce-Scatter 阶段:通信量为\((N-1)\frac{\psi}{N}\)
- All-Gather 阶段:通信量为\((N-1)\frac{\psi}{N}\)
即单个 GPU 总的发送通信量为\(2(N-1)\frac{\psi}{N}\)。随着\(N\)的增大,可以近似为\(2\psi\);所有 GPU 的总通信量为 \(2N\psi\)。
由第3点出发考虑通信开销:Server 需要和每一个 Worker 完成梯度传输;当 Server 和 Worker 不在同一台机器上时,Server 的带宽将成为计算效率瓶颈。由此引出分布式数据并行(DDP)。
如果所有梯度发送到单个 GPU 上做梯度聚合,该 GPU 承载的通信量为\(N\psi\),其他 GPU 承载的通信量为 \(N\psi\),所有 GPU 的总通信量依然为\(2\psi\)。Ring-AllReduce 不改变总通信量,但将通信量均分到了每一时刻的每个 GPU 上,解决了通信负载不均的问题。
