并行训练系列:3. 数据并行下篇(DeepSeed-ZeRO)
上篇描述了朴素数据并行(DP)和分布式数据并行(DDP)策略。两者的总通信量相同,然而 DP 的单 Server 机制导致了通信负载不均的问题(Server 通信量和总 GPU 数量成线性关系),导致 DP 适用于单机多卡场景;DDP 通过 Ring-AllReduce 这一 NCCL 操作,使得通信量均衡分布到所有 GPU 上(单个 GPU 通信量不受到总 GPU 数量的影响),利于多机多卡场景。
解决通信量负载不均的问题后,开始考虑显存开销:每个 DP 分片都复制了一份完整的模型参数、梯度和优化器状态,造成极大的显存负担,如何优化呢?
在优化显存前,需要先理清两个关键问题:
- 训练过程中 GPU 上存储了哪些内容?
- 分别在哪些阶段需要使用?
先看第一个问题。
显存开销计算
当训练一个神经网络时,需要在内存中存储以下内容:模型参数 W、模型梯度 G、优化器状态、(用于计算梯度的)激活值。
以上数据以tensor的形式存储在内存中。在训练各阶段的内存占用率如下图: 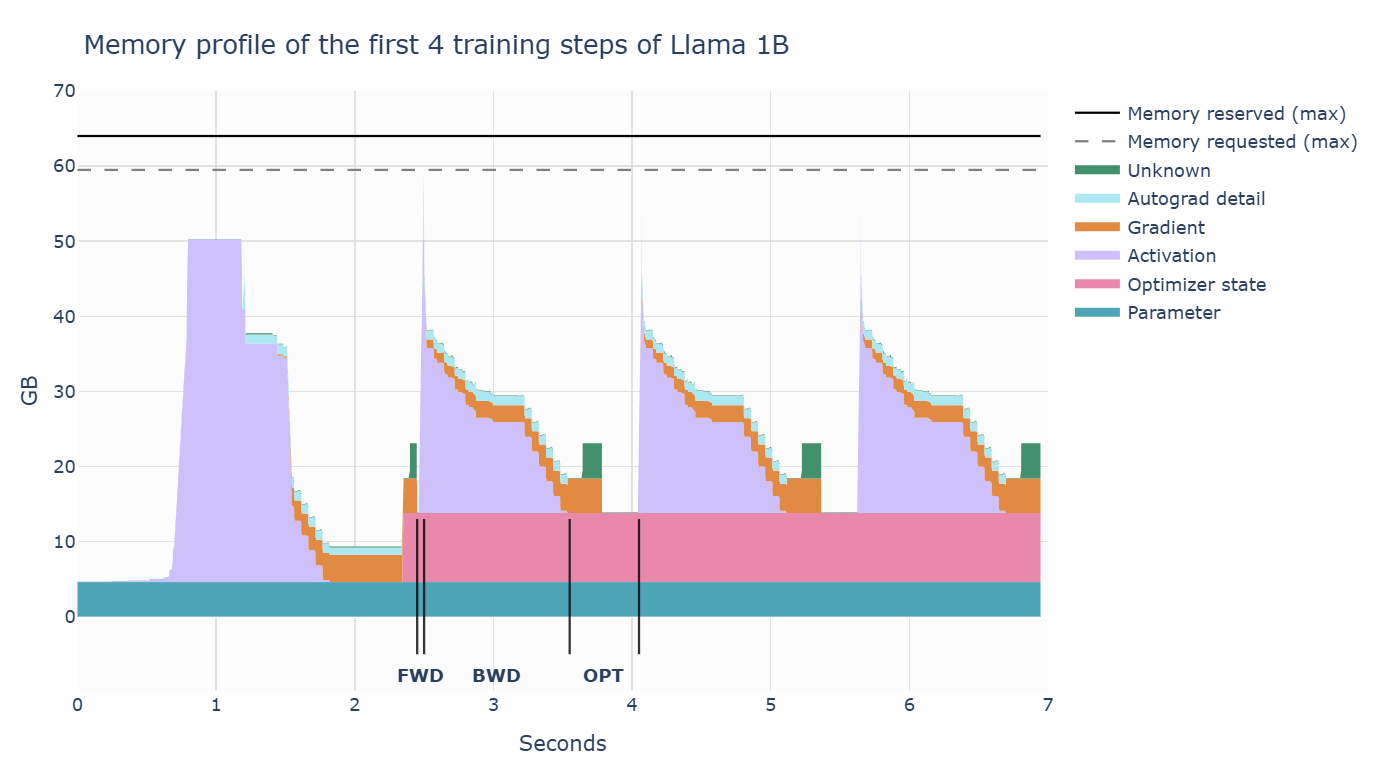
- 前向传播时,激活值迅速增加;
- 反向传播时,梯度逐渐积累,且计算梯度的激活值会逐步被清除;
- 最后,执行优化步骤,此时需要所有的梯度,并更新优化器状态;然后才开始下一次的前向传播。
第一步和后续步骤明显不同的原因:激活值快速增加,再保持一段时间的平稳。在第一步中,torch 的缓存分配器进行大量准备工作,预先分配内存;后续步骤不再需要寻找空闲内存块,从而加速)
传统 fp32 训练
假设模型参数 W 的大小是\(\psi\),以byte为单位,内存开销如下:
- 模型参数:\(4\psi\)
- 梯度:\(4\psi\)
- Adam 优化器的动量和方差:\((4+4)\psi\)
混合精度训练
下图采用混合精度训练: 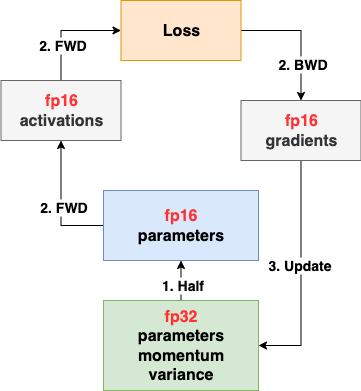
过程如下:
- 存储一份 fp32 的 parameter, momentum 和 variance(统称 model states);在 forward 开始之前,额外开辟一块存储空间,将 fp32 parameter 减半到 fp16 parameter;
- fp32 parameter 由优化器维护,只做更新;fp16 parameter 参与 FWD 计算
- forward/backward:产生精度为 fp16 的 activations 和 gradients;
- update:使用 fp16 gradients 更新 fp32 parameter;
模型收敛后,fp32 parameter 是最终的参数输出。
显存开销如下:
- 模型参数:\(4\psi+2\psi\)
- 梯度:\(2\psi\)
- Adam 优化器的动量和方差:\((4+4)\psi\)
传统 fp32 训练和混合精度训练的显存占用量均为\(16\psi\),不会节省整体内存;只是重新分配。那混合精度训练有哪些优点呢?
- GPU 上使用 fp16 的 parameter,加速前向/反向传播过程;
- 减少前向/反向传播中产生的激活值的显存占用量。
为了通用表示,记模型必存的数据大小为\(k\psi\)(包括 fp32 parameter, fp32 动量和方差);显存开销为\(2\psi+2\psi+K\psi\)。
DataFlow
现在考虑第2个问题:数据分别在哪些阶段使用呢?
- 模型参数 W:FWD/BWD 阶段;
- 梯度 G:FWD/BWD 结束后的 AllReduce,和参数更新阶段;
- Adam 优化下的优化器状态:参数更新阶段。
一个直观的策略是:我只需要在使用到数据时加载,而非全程保存在所有 GPU 上,就可以省下一笔存储空间了。
ZeRO 系列
假设显卡数量为 \(N\),提出以下3种 ZeRO 算法: 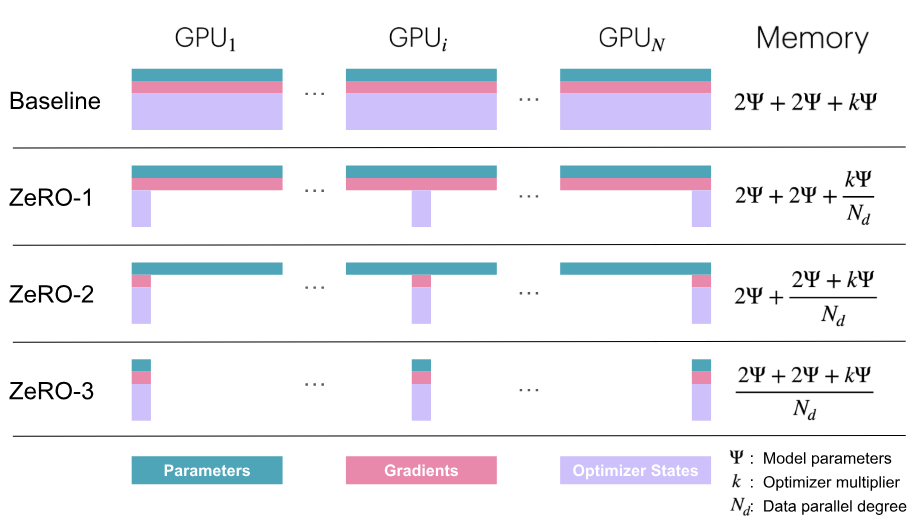 显存占用量分析:
显存占用量分析:
- ZeRO-1:只对优化器状态进行分片,每张卡保存\(\frac{1}{N}\)的状态量。此时,每张卡所需显存是\(4\psi+\frac{12\psi}{N}\)字节。当\(N\)较大时,趋向于\(4\psi\),记为\(P_{os}\);
- ZeRO-2:对优化器状态和梯度进行分片,此时,每张卡所需显存是\(2\psi+\frac{2\psi+12\psi}{N}\)字节。当\(N\)较大时,趋向于\(2\psi\),记为\(P_{os+g}\);
- ZeRO-3:将模型参数、梯度、优化器状态三者都进行分片,此时,每张卡所需显存是\(\frac{16\psi}{N}\)字节。当\(N\)较大时,趋向于\(0\),记为\(P_{os+g+p}\).
- ZeRO-3 对应 Pytorch FSDP
通信量分析:(这里不再换算为 byte)
朴素 DDP
聚合并下发梯度时,采用 Ring-AllReduce:
- Reduce-Scatter 阶段:通信量为\((N-1)\frac{\psi}{N}\)
- All-Gather 阶段:通信量为\((N-1)\frac{\psi}{N}\)
单卡通信量近似为\(2\psi\)。
ZeRO-1:\(P_{os}\)
将优化器状态(fp32 parameter + fp32 momentum + fp32 variance)分片存储在各个 GPU 上:
训练流程如下:
每张卡上存储一份完整的模型参数 W(fp16 parameter),将一个 batch 切分为多个 micro-batch,在每张卡上分别完成 FWD/BWD 计算,得到梯度 G(fp16 gradients);
聚合梯度 Reduce-Scatter:相比于朴素 DDP 使用 AllReduce,这里优化为 Reduce-Scatter,单卡通信量为\(\psi\),拿到更新自身\(\frac{1}{N}\)参数所需的 gradients 即可;
参数更新:
- 本地更新:使用完整梯度 G 和它负责的那部分 fp32 parameter,执行优化器步骤,更新它自己负责的那一部分 fp32 parameter;
fp16._copy(fp32):将更新后的 fp32 parameter 原位拷贝回本卡上完整 fp16 parameter 中对应的部分。- 例如:负责第0~25%参数的 GPU,用它更新后的 fp32 parameter 覆盖掉自己 fp16 parameter 中第0~25%的参数。
- All-Gather:由于每张卡只更新了模型的一部分,需要通过 All-Gather 通信操作(单卡通信量为\(\psi\));使得所有卡同步到完整的、更新后的 fp16 parameter,用于下一次迭代的 FWD/BWD。
假设完整的 fp32 parameter 大小为 1000 MB;
fp16:ZeRO 系列将原始的 fp32 复制一份并转为 fp16;这个大小为500 MB 的完整 fp16 副本会保存在每张卡上;fp16 用于 FWD/BWD 计算;
- 注意:fp16 是从更新后的 fp32 cast 得到并用于下一轮 FWD/BWD 计算(不会直接使用 fp16 gradients 更新)
fp32:每张卡上保存 \(\frac{1}{N}\) 的完整 fp32 parameter;操作为:
fp32 = partiton_fp16.copy().float().detach()
partiton_fp16:从本卡的完整 fp16 parameter 中,取出自己负责的那一部分(例如第0张卡负责0~25%的参数);.copy().float():将这一部分 fp16 parameter 复制出来,并转换为 fp32,得到了分区后的 fp32 parameter;.detach():将 fp32 parameter 从当前计算图中分离出来,不参与 FWD/BWD 计算,只用于权重更新。
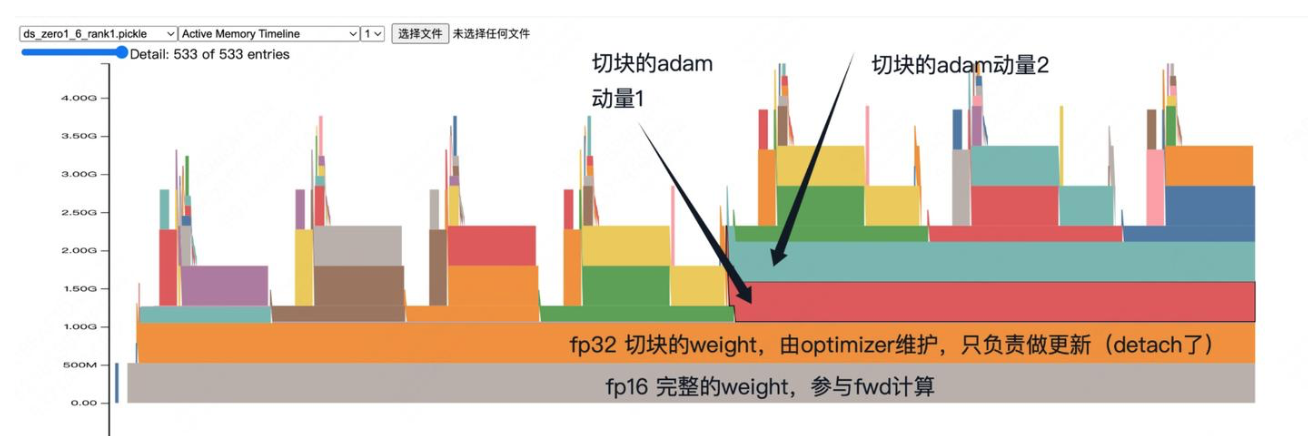 假设完整的 fp32 parameter 大小为 1000 MB;
假设完整的 fp32 parameter 大小为 1000 MB;步骤如下图: 
与朴素 DP 相比,ZeRO-1 在通信量相同的情况下,将单卡上优化器状态的显存占用降低到了\(\frac{1}{N}\)。
ZeRO-2:\(P_{os+g}\)
在 ZeRO-1 的基础上,将 fp16 gradients 分片存储在各个 GPU 上。
在 gradient 的 Reduce-Scatter 操作中,只需要保持每张卡上自己维护的梯度是聚合梯度。例如对于 GPU 1,负责维护 G1,其他 GPU 只需要将 G1 对应位置的梯度发给它即可。 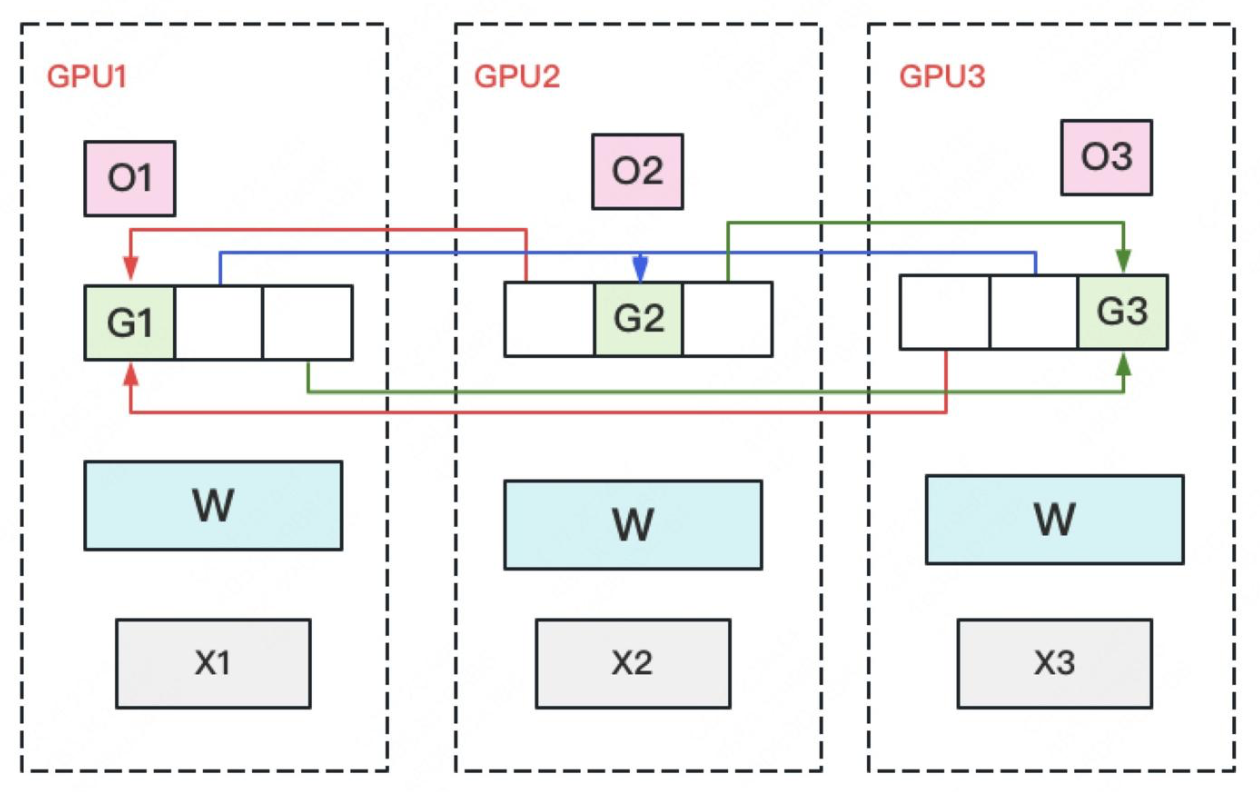 在上图中,聚合梯度后白色块无用,可从显存中移除;绿色块是最终的聚合梯度。
在上图中,聚合梯度后白色块无用,可从显存中移除;绿色块是最终的聚合梯度。
与 ZeRO-1 的通信步骤和通信量相同,优化点是进一步将 fp16 parameter 分片。
ZeRO-3:\(P_{os+g+p}\)
在 ZeRO-2 的基础上,将 fp16 parameter 也分片存储。
- 每张卡上只保存模型的部分参数 W(fp16 parameter),将一个 batch 切分为多个 micro-batch 输入到各张卡上;
- FWD:依次经过每个 layer。先对 W 做一次 All-Gather,聚合分布在其他卡上的 W,得到一份完整的 W(单卡通信量\(\psi\));做完 FWD,立刻从显存中清除不由自己维护的 W。
- BWD:对 W 做一次 All-Gather 取回完整的 W(单卡通信量\(\psi\)); 做完 BWD,对计算得到的梯度 G 做一次 Reduce-Scatter,从其他卡上聚合自己维护的那部分梯度(单卡通信量\(\psi\))。聚合操作结束后,立刻从显存中清除不由自己维护的 G。
- 每张卡用本地的 fp2 parameter 和梯度 G 执行优化器步骤,更新它自己负责的那一部分 fp32 parameter。
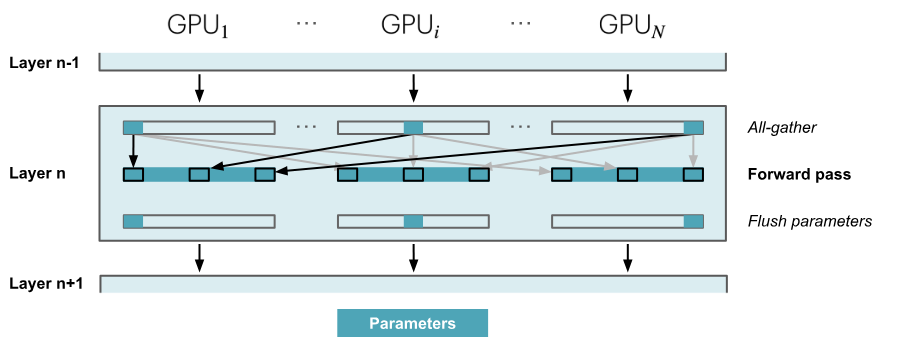
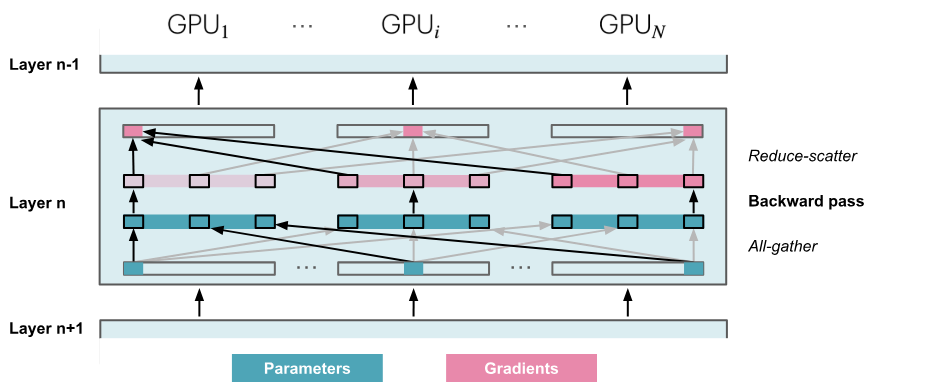
单卡总通信量为 \(3\psi\)。与朴素 DP 相比,用 1.5 倍的开销,换回了单卡总显存占用量降低到\(\frac{1}{N}\)。
与 ZeRO-2 相比,需要额外执行\(2*numLayers-1\)次 All-Gather,每次操作带来一个小的基础延迟开销。

显存占用量的对比图如下: 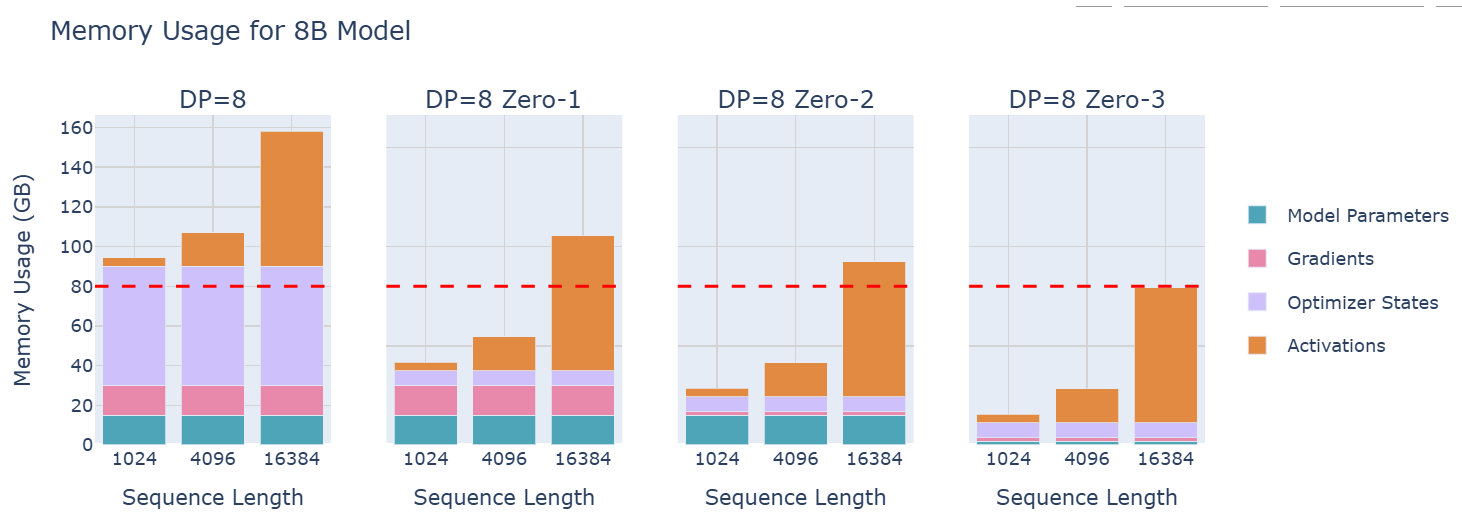
ZeRO-R:优化 Actications 的存储
以上为针对必存部分 model states 的显存优化,现在来看 activations.
不像模型参数、梯度、优化器状态对于模型更新是必须的,激活值只是起到加速梯度计算的作用,因此其存储策略支持灵活设置。
ZeRO-R 的做法是:将所有的激活值分片存储,即只对activation checkpoints分片。
正常情况:FWD 过程中保存每一个激活值,用于 BWD 时计算梯度,计算完对应梯度节点后才能释放激活值;
- 缺点:需要保存大量的中间激活值,显存占用量随着层数线性增长的。
优化一:丢弃所有的中间激活值, BWD 需要时重新计算;
- 缺点:训练速度慢,每个 BWD 原本只需要计算一次,现在最多需要计算n次!
折中做法:选取一些前向节点作为 checkpoint;训练时,这些checkpoint 的激活值会一直保存在显存中;而其他节点的激活值会被丢弃。
- 优点:计算反向梯度节点时,只需要从离它最近的checkpoint节点开始计算(不用把每个节点都重新计算一遍)。
ZeRO-Offload:显存不够,内存来凑
GPU 显存不够用,则:将一部分计算和存储下放到 CPU 和内存;并且不让 CP 和 GPU 之间的通信成为瓶颈,也不让 CPU 参与过多计算,避免 CPU 计算成为瓶颈。
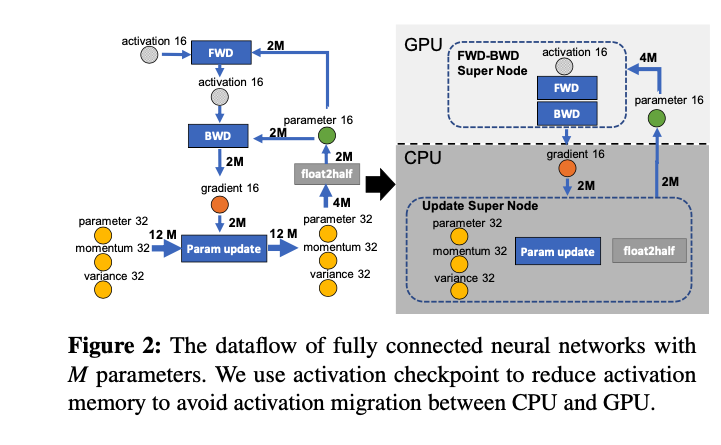
将数据流图切分成 CPU 和 GPU 两部分。ZeRO-Offload 策略如下:将计算量高的 FWD 和 BWD 放在 GPU 上;计算量低的参数更新和 float2half 这两个计算操作放在CPU上。因此,优化器状态也放在内存中。
上述方法仅仅针对单卡场景。在多卡场景下,ZeRO-Offload 采取 ZeRO-2 策略:将分片后的\(\frac{1}{N}\)个优化器状态和梯度都下放到内存,只在CPU上进行参数更新。
更多内容参考:大模型并行训练技术(一)—— ZeRO系列
Pytorch-FSDP
FSDP Engine 默认采取 ZeRO-3 策略。详细用法参考:FullyShardedDataParallel — PyTorch 2.2 documentation
FSDP 在 DeepSpeed ZeRO-DP 的基础上进行了拓展,分片策略包括:NO_SGARD(对标朴素 DDP);SHARD_GRAD_OP(对标ZeRO2);FULL_SHARD(默认策略,对标 ZeRO3);HYBRID_SHARD(节点内 shard,节点间 replicate,对标ZeRO++ stage3),_HYBRID_SHARD_ZeRO2(节点内 ZeRO-2 shard,节点间replicate)。
训练流程如下图: 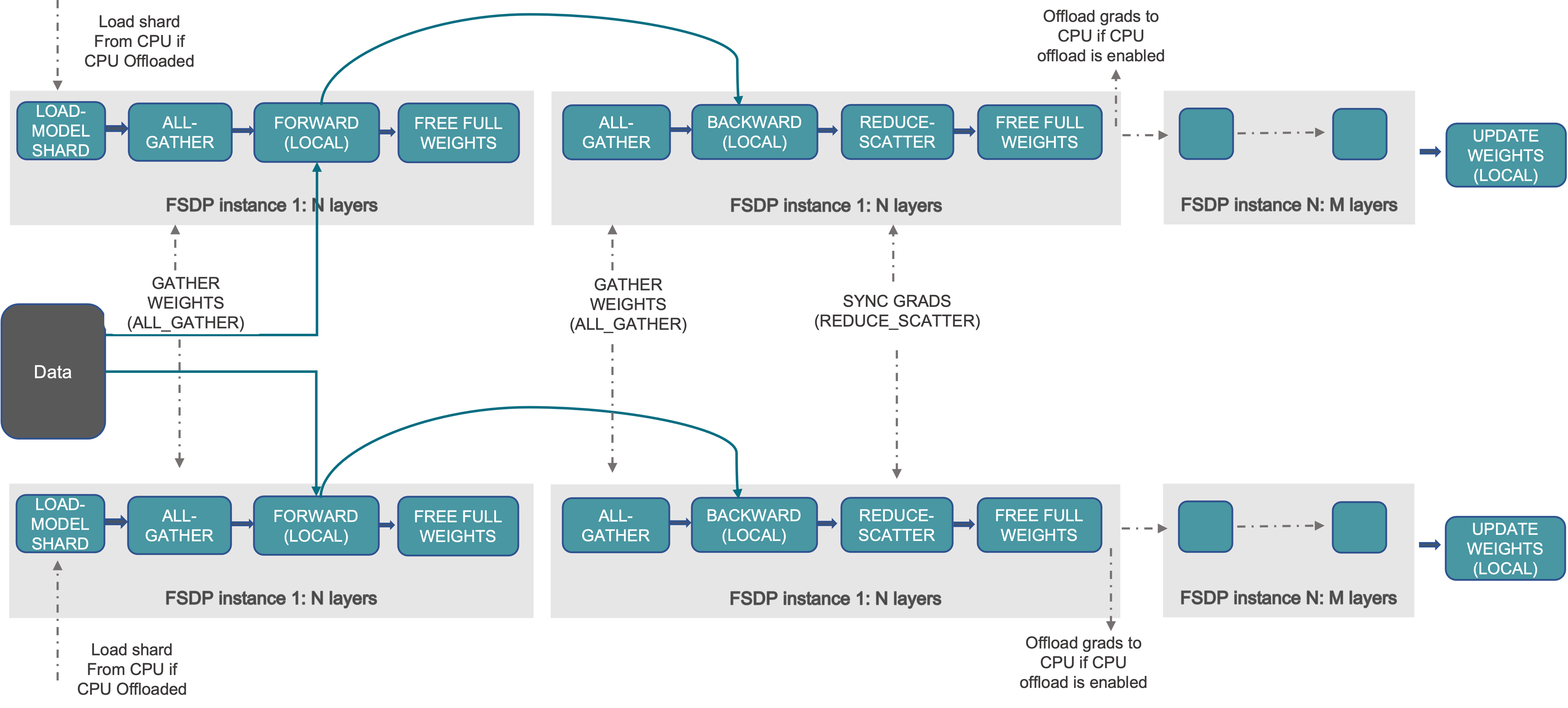
细节详见下一篇。
ZeRO vs TP
做一个小结:ZeRO 系列的关键思路是“通信换显存”。
看上去 ZeRO 对 parameter 做了拆分,为什么不算 TP 呢?
因为在 FWD/BWD 过程中,需要通过 All-Gather 聚合每张卡上维护的模型参数才能计算,计算时使用的是完整的参数和切分后的输入,依然是 DP;
对于 TP/PP,在 FWD/BWD 中只存储模型参数的一部分,计算时使用的是切分后的参数和完整的输入。
