内存分配器 内存空间包含两个重要区域:栈区 和堆区 。不同编程语言使用不同的方法管理堆区的内存,C++ 等编程语言会由工程师主动申请和释放内存,Go 以及 Java 等编程语言会由工程师和编译器共同管理,堆中的对象由内存分配器分配并由垃圾收集器回收。
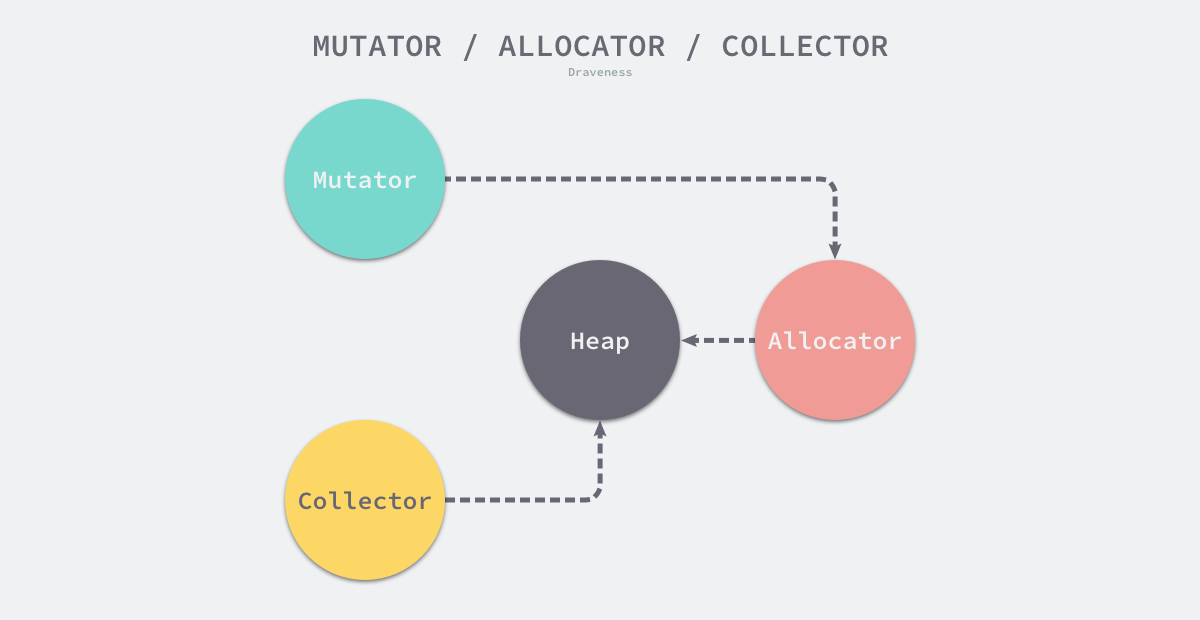
设计原理 内存管理一般包含三个不同的组件,分别是用户程序(Mutator)、分配器(Allocator)和收集器(Collector);当用户程序申请内存时,它会通过内存分配器申请新内存,而分配器会负责从堆中初始化相应的内存区域 。
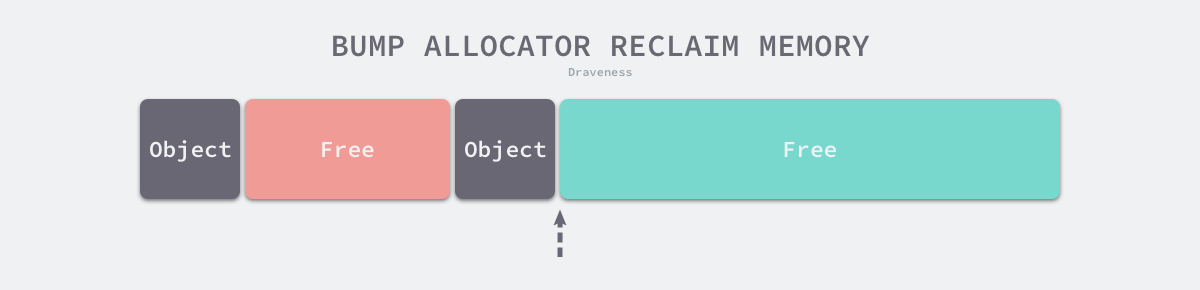
分配方法 线性分配器 使用线性分配器时,只需要在内存中维护一个指向特定位置的指针;用户程序申请内存时,移动指针。然而,这不利于在内存被释放时重用内存。如下图中红色部分难以利用:
因为线性分配器需要与具有拷贝特性的垃圾回收算法配合,所以 C 和 C++ 等需要直接对外暴露指针的语言无法使用该策略。
空闲链表分配器 在内部会维护一个类似链表的数据结构;当用户程序申请内存时,依次遍历空闲的内存块 ,找到足够大的内存,然后申请新的资源并修改链表,时间复杂度为O(n),常见策略如下:
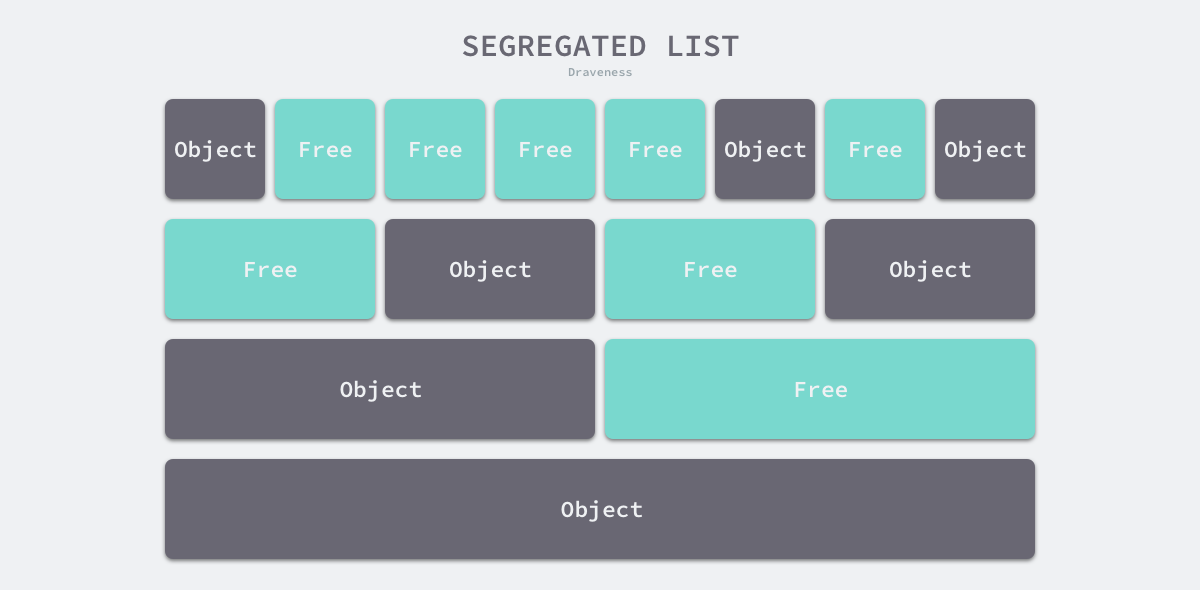
首次适应(First-Fit):从链表头开始 遍历,选择第一个大小大于申请内存的内存块; 循环首次适应(Next-Fit):从上次遍历的结束位置开始 遍历,选择第一个大小大于申请内存的内存块; 最优适应(Best-Fit)— 从链表头遍历整个链表,选择最合适的内存块; 隔离适应(Segregated-Fit)— 将内存分割成多个链表,每个链表中的内存块大小相同(不同链表的内存块大小不同),申请内存时先找到满足条件的链表,再从链表中选择合适的内存块 ; Go使用的内存分配策略类似第4种。
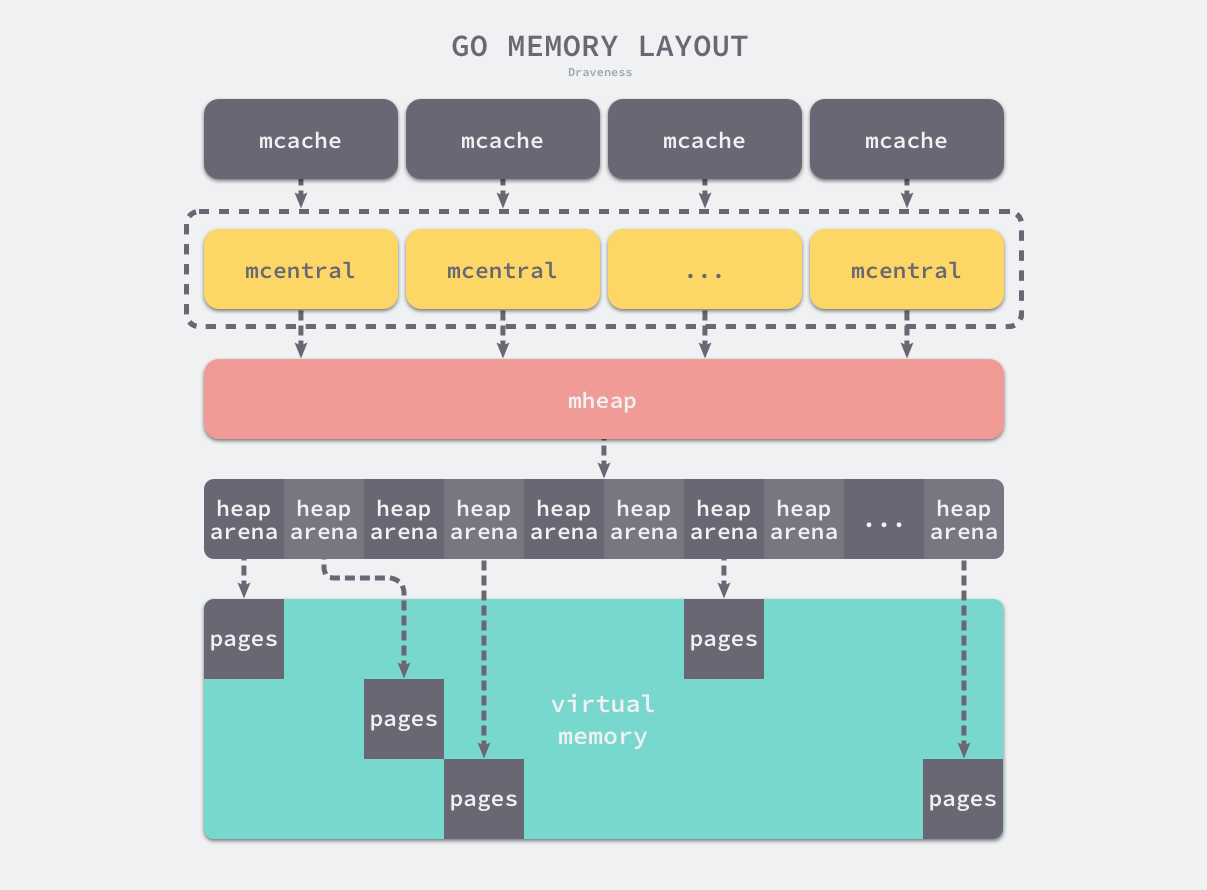
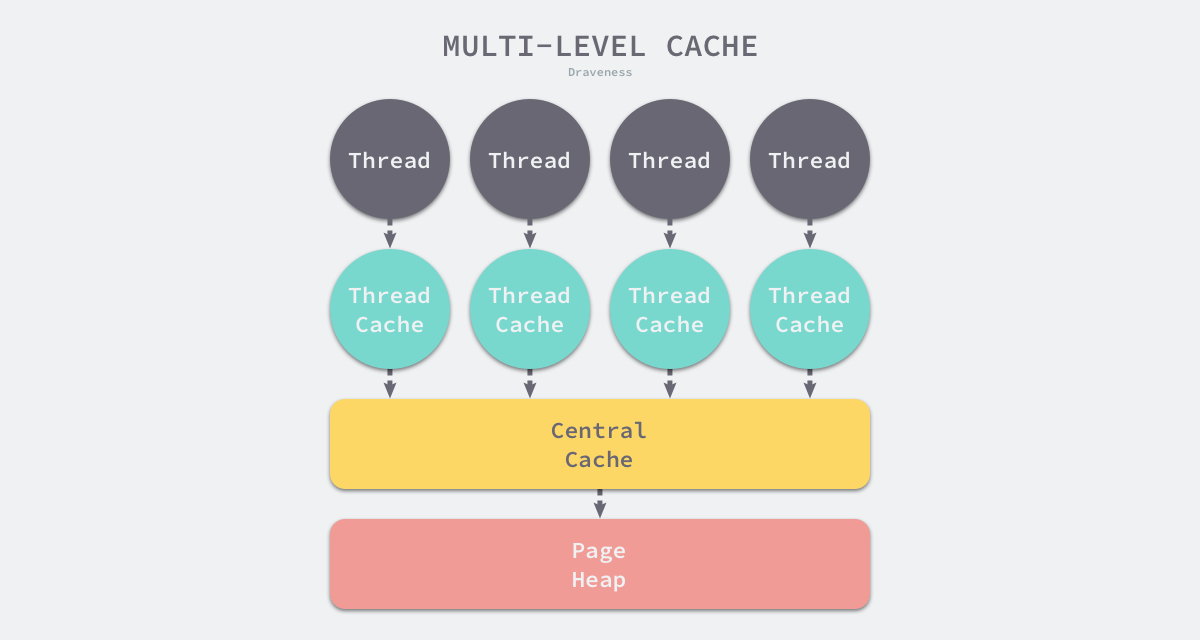
分级分配 Go 语言的内存分配器借鉴了线程缓存分配(TCMalloc)的设计实现高速的内存分配,它的核心理念是使用多级缓存将对象根据大小分类 ,并按照类别实施不同的分配策略 。对象一共包括3种:
微对象:(0, 16B) 小对象:[16B, 32KB] 大对象:(32KB, +∞) 多级缓存包括3个组件:线程缓存(Thread Cache)、中心缓存(Central Cache)和页堆(Page Heap)
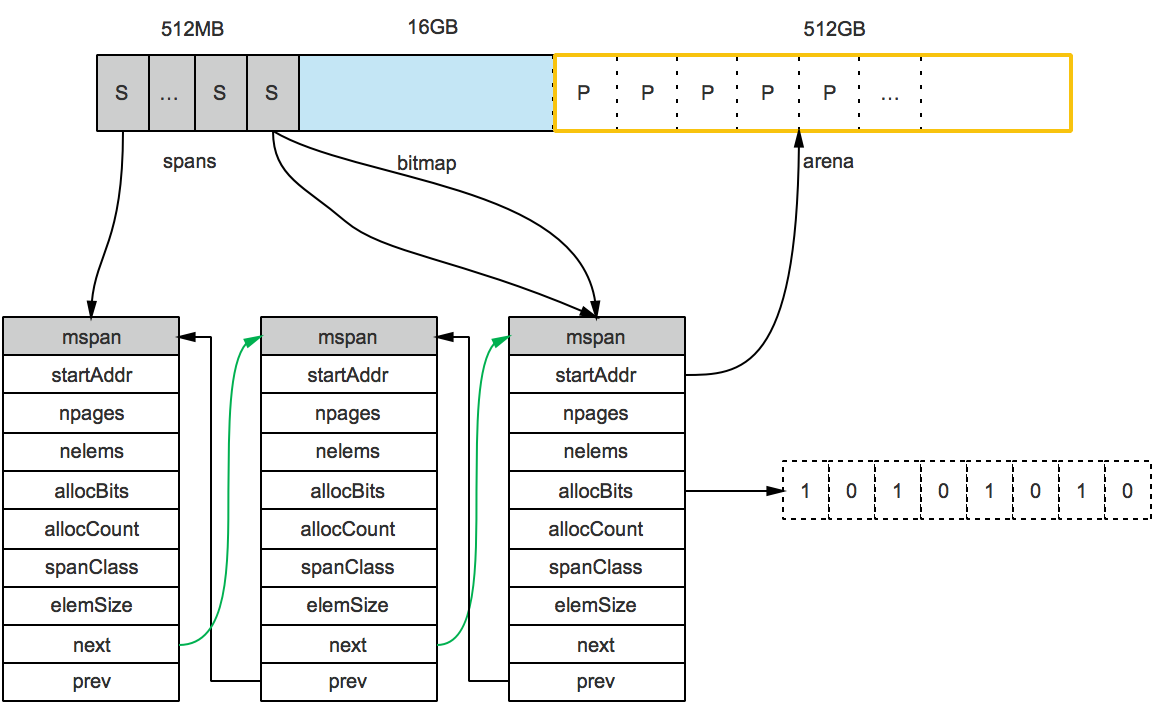
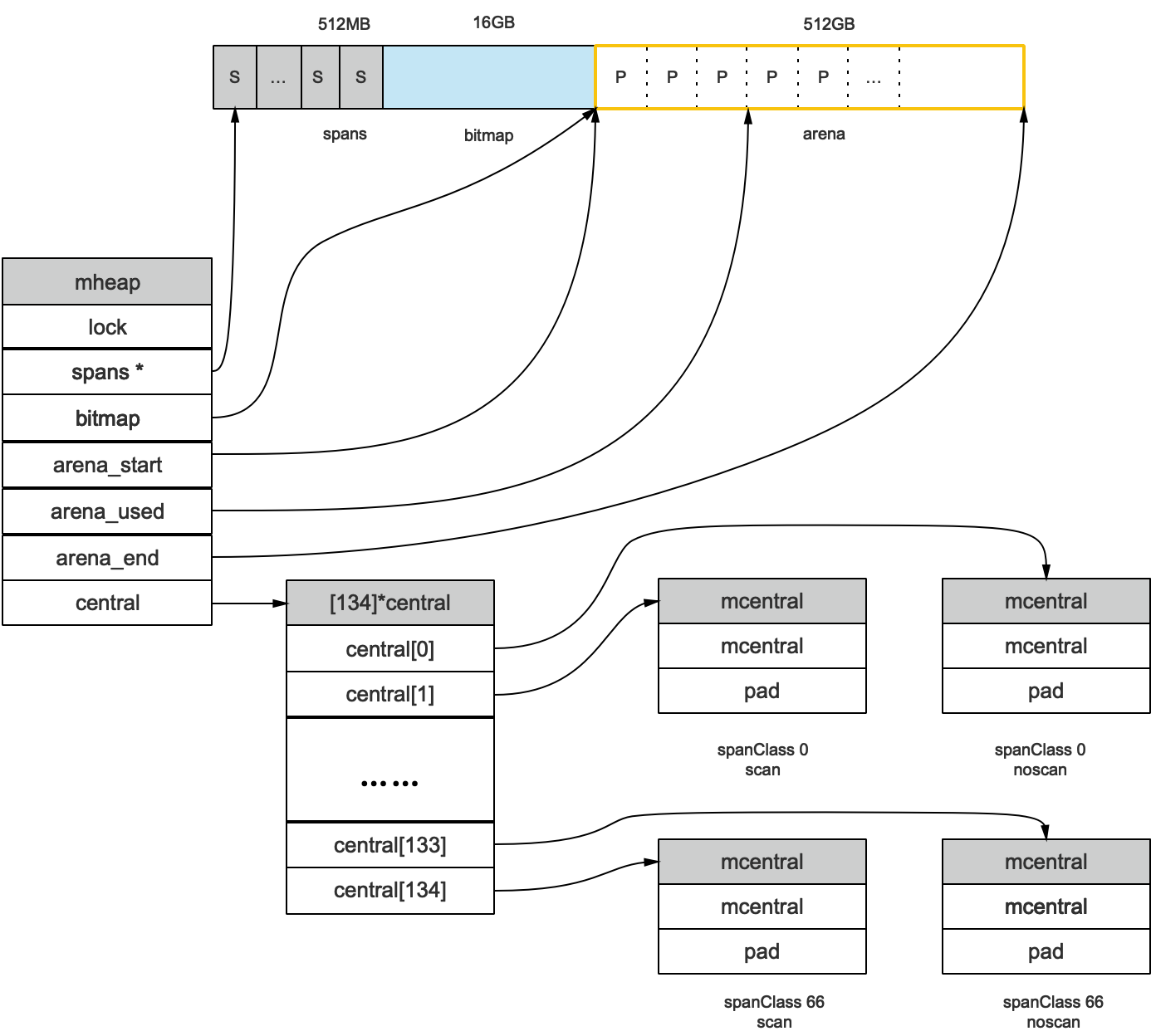
虚拟内存布局 在 Go 语言 1.10 以前的版本中,堆区的内存空间是连续的,即在启动时初始化整片虚拟内存区域,spans、bitmap 和 arena 区域分别预留了 512MB、16GB 以及 512GB 的内存空间。 然而有以下问题:
堆大小上限受限(512GB): C 和 Go 混合使用时易产生地址空间冲突:分配的内存地址会发生冲突,导致堆的初始化和扩容失败;没有被预留的大块内存可能会被分配给 C 语言的二进制,导致扩容后的堆不连续。 在 1.11 版本及以后换用稀疏内存 的方案:runtime使用二维的 runtime.heapArena每个runtime.heapArena管理 64MB 的内存空间 :
在amd64的Linux操作系统上,runtime.heapruntime.heapArenaruntime.heapArena管理 64MB 的内存空间,单个Go 语言程序的内存上限也就是 256TB。
1 2 3 4 5 6 7 8 9 10 11 12 type heapArena struct { bitmap [heapArenaBitmapBytes]byte spans [pagesPerArena]*mspan pageInUse [pagesPerArena / 8 ]uint8 pageMarks [pagesPerArena / 8 ]uint8 pageSpecials [pagesPerArena / 8 ]uint8 checkmarks *checkmarksMap zeroedBase uintptr }
bitmap如下:
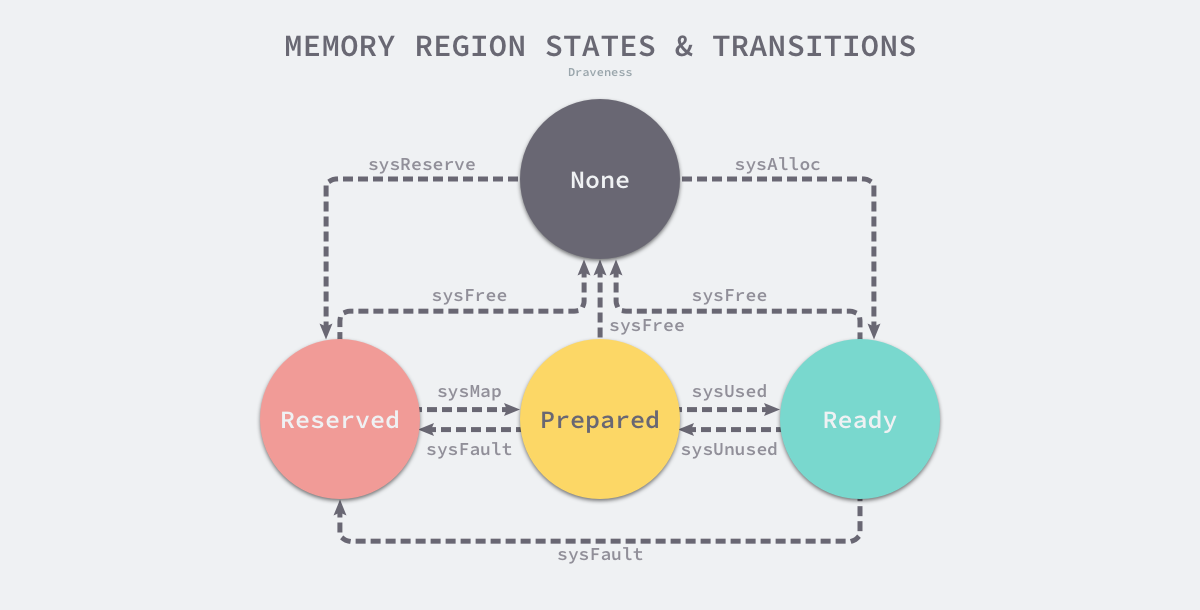
地址空间 Go的runtime构成了操作系统内存管理的抽象层(申请内存最终落到底层OS),抽象层将地址空间分为4种状态:
None:地址空间默认状态,对应内存没有被保留或者映射;Reserved:runtime持有该内存空间Prepared:内存被保留,可以快速转到Ready状态 (没有对应的物理内存却访问Prepared状态内存的行为是未定义的);Ready:可以被安全访问 runtime使用 Linux 提供的 mmap、munmap 和 madvise 等系统调用实现了操作系统的内存管理抽象层,抹平了不同操作系统的差异,提供了更加方便的接口。
内存管理组件
若干个runtime.mspan组成双向链表;每个runtime.mspannpages个大小为8KB的页 (这里的页是操作系统内存页的整数倍)
每个mspan按照其对应SpanClass的大小分割成若干个object,每个object可存储一个对象(对象的大小不超过object的大小),并使用一个位图标记object的占用情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 type mspan struct { next *mspan prev *mspan list *mSpanList ... startAddr uintptr npages uintptr freeindex uintptr allocBits *gcBits gcmarkBits *gcBits allocCache uint64 ... state mSpanStateBox spanclass spanClass }
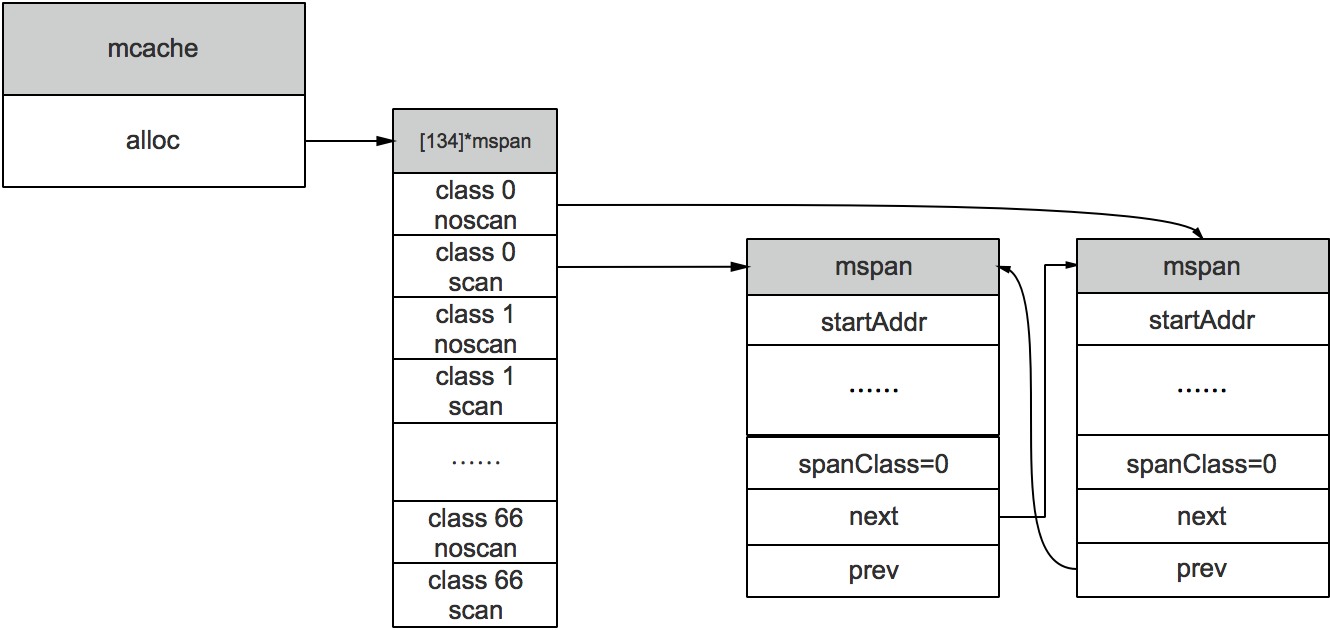
每一个工作线程绑定一个mcache ,每一个mcache持有68*2个runtime.mspanalloc字段中,用于缓存用户程序申请的微小对象。
1 2 3 4 5 6 7 8 9 type mcache struct { tiny uintptr tinyoffset uintptr local_tinyallocs uintptr ... alloc [numSpanClasses]*mspan } numSpanClasses = _NumSizeClasses << 1
初始化线程缓存时调用runtime.allocmcache刚初始化时alloc中的所有runtime.mspanruntime.mspan满足内存分配的需求 。
那么如何申请新的runtime.mspan并插入线程内存呢?调用runtime.mcache.refill
1 2 3 4 5 6 func (c *mcache) s := c.alloc[spc] s = mheap_.central[spc].mcentral.cacheSpan() c.alloc[spc] = s }
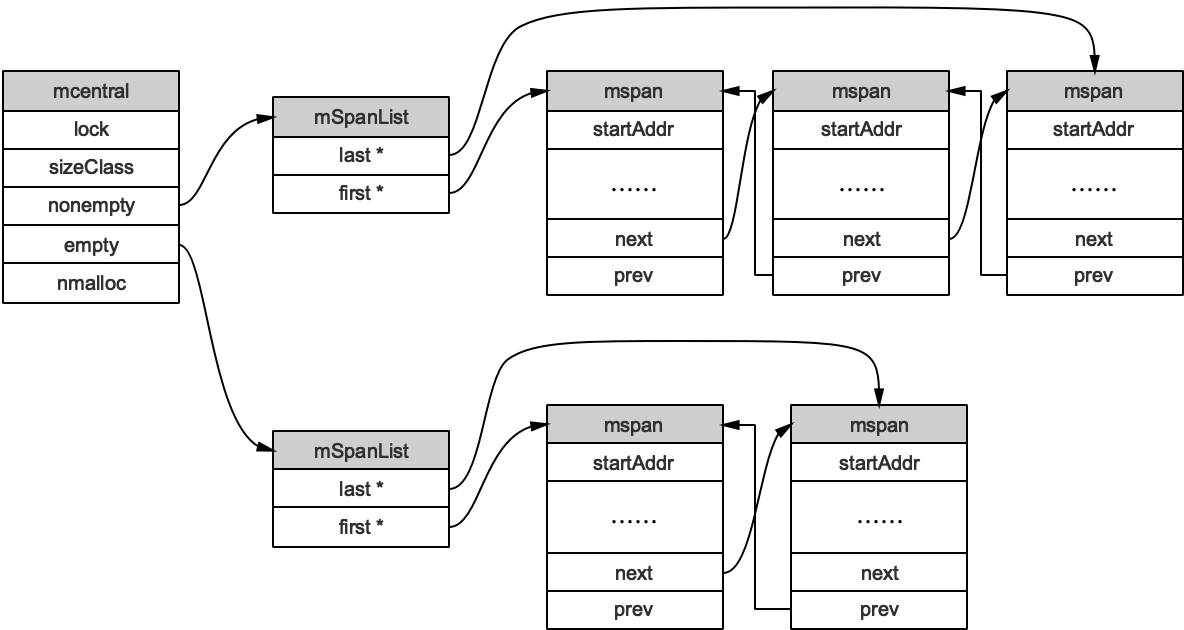
每个中心缓存管理某个跨度类的mspan。
1 2 3 4 5 type mcentral struct { spanclass spanClass partial [2 ]spanSet full [2 ]spanSet }
线程缓存在runtime.mcache.refillruntime.mcentral.cacheSpanmspan,步骤如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 func (c *mcentral) sg := mheap_.sweepgen spanBudget := 100 if s = c.partialSwept(sg).pop(); s != nil { goto havespan } for ; spanBudget >= 0 ; spanBudget-- { s = c.partialUnswept(sg).pop() if s == nil { break } if atomic.Load(&s.sweepgen) == sg-2 && atomic.Cas(&s.sweepgen, sg-2 , sg-1 ) { s.sweep(true ) goto havespan } } for ; spanBudget >= 0 ; spanBudget-- { s = c.fullUnswept(sg).pop() if s == nil { break } if atomic.Load(&s.sweepgen) == sg-2 && atomic.Cas(&s.sweepgen, sg-2 , sg-1 ) { s.sweep(true ) freeIndex := s.nextFreeIndex() if freeIndex != s.nelems { s.freeindex = freeIndex goto havespan } c.fullSwept(sg).push(s) } } ... s = c.grow() if s == nil { return nil } havespan: freeByteBase := s.freeindex &^ (64 - 1 ) whichByte := freeByteBase / 8 s.refillAllocCache(whichByte) s.allocCache >>= s.freeindex % 64 return s }
mheap代表Go程序持有的所有堆空间,使用一个全局对象_mheap管理堆内存。
当mcentral没有空闲的mspan时,会向mheap申请;mheap没有足够资源时,向操作系统申请新的内存(扩容)。
mheap中含有所有规格的mcentral;所以,当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan。
1 2 3 4 5 6 7 type mheap struct { arenas [1 << arenaL1Bits]*[1 << arenaL2Bits]*heapArena central [numSpanClasses]struct { mcentral mcentral pad [cpu.CacheLinePadSize - unsafe.Sizeof(mcentral{})%cpu.CacheLinePadSize]byte } }
runtime.mheapruntime.mheap.allocruntime.span
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 func (h *mheap) uintptr , spanclass spanClass, needzero bool ) *mspan { var s *mspan systemstack(func () if h.sweepdone == 0 { h.reclaim(npages) } s = h.allocSpan(npages, false , spanclass, &memstats.heap_inuse) }) ... return s } func (h *mheap) uintptr , typ spanAllocType, spanclass spanClass) (s *mspan) { gp := getg() base, scav := uintptr (0 ), uintptr (0 ) pp := gp.m.p.ptr() if pp != nil && npages < pageCachePages/4 { c := &pp.pcache base, scav = c.alloc(npages) if base != 0 { s = h.tryAllocMSpan() if s != nil && gcBlackenEnabled == 0 && (manual || spanclass.sizeclass() != 0 ) { goto HaveSpan } } } if base == 0 { base, scav = h.pages.alloc(npages) if base == 0 { h.grow(npages) base, scav = h.pages.alloc(npages) if base == 0 { throw("grew heap, but no adequate free space found" ) } } } if s == nil { s = h.allocMSpanLocked() } ... }
runtime.mheap
通过runtime.mheap.growarena 区域没有足够的空间,调用runtime.mheap.sysAlloc
用户程序向堆上申请内存的必经之路:堆上对象调用runtime.newobjectruntime.mallocgc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 func mallocgc (size uintptr , typ *_type, needzero bool ) mp := acquirem() mp.mallocing = 1 c := gomcache() var x unsafe.Pointer noscan := typ == nil || typ.ptrdata == 0 if size <= maxSmallSize { if noscan && size < maxTinySize { } else { } } else { } publicationBarrier() mp.mallocing = 0 releasem(mp) return x }
微对象 (0, 16B),不可以是指针类型 :先使用微型分配器 ,再依次尝试线程缓存、中心缓存和堆分配内存;小对象 [16B, 32KB] :依次尝试使用线程缓存、中心缓存和堆分配内存;大对象 (32KB, +∞) :直接在堆上分配内存 。微对象 微分配器可以将多个较小的内存分配请求合入同一个内存块中;只有当内存块中的所有对象都需要被回收时,整片内存才可能被回收。
假设微分配器已经在 16 字节的内存块中分配了 12 字节的对象,如果下一个待分配的对象小于 4 字节,它会直接使用上述内存块的剩余部分,减少内存碎片。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 func mallocgc (size uintptr , typ *_type, needzero bool ) ... if size <= maxSmallSize { if noscan && size < maxTinySize { off := c.tinyoffset ... if off+size <= maxTinySize && c.tiny != 0 { x = unsafe.Pointer(c.tiny + off) c.tinyoffset = off + size c.local_tinyallocs++ releasem(mp) return x } ... span = c.alloc[tinySpanClass] v := nextFreeFast(span) if v == 0 { v, span, shouldhelpgc = c.nextFree(tinySpanClass) } x = unsafe.Pointer(v) (*[2 ]uint64 )(x)[0 ] = 0 (*[2 ]uint64 )(x)[1 ] = 0 if size < c.tinyoffset || c.tiny == 0 { c.tiny = uintptr (x) c.tinyoffset = size } size = maxTinySize } ... } ... }
小对象 小对象是指:大小为 16 字节到 32,768 字节的对象、以及所有小于 16 字节的指针类型的对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 func mallocgc (size uintptr , typ *_type, needzero bool ) ... if size <= maxSmallSize { ... } else { var sizeclass uint8 if size <= smallSizeMax-8 { sizeclass = size_to_class8[(size+smallSizeDiv-1 )/smallSizeDiv] } else { sizeclass = size_to_class128[(size-smallSizeMax+largeSizeDiv-1 )/largeSizeDiv] } size = uintptr (class_to_size[sizeclass]) spc := makeSpanClass(sizeclass, noscan) span := c.alloc[spc] v := nextFreeFast(span) if v == 0 { v, span, _ = c.nextFree(spc) } x = unsafe.Pointer(v) if needzero && span.needzero != 0 { memclrNoHeapPointers(unsafe.Pointer(v), size) } } } else { ... } ... return x }
大对象 对于大于 32KB 的大对象,直接调用 runtime.mcache.allocLarge
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 func mallocgc (size uintptr , typ *_type, needzero bool ) ... if size <= maxSmallSize { ... } else { var s *mspan span = c.allocLarge(size, needzero, noscan) span.freeindex = 1 span.allocCount = 1 x = unsafe.Pointer(span.base()) size = span.elemsize } publicationBarrier() mp.mallocing = 0 releasem(mp) return x } func (c *mcache) uintptr , needzero bool , noscan bool ) *mspan { npages := size >> _PageShift if size&_PageMask != 0 { npages++ } ... s := mheap_.alloc(npages, spc, needzero) mheap_.central[spc].mcentral.fullSwept(mheap_.sweepgen).push(s) s.limit = s.base() + size heapBitsForAddr(s.base()).initSpan(s) return s }
小结 运行时的内存分配器使用类似 TCMalloc 的分配策略将对象根据大小分类,并设计多层级的组件提高内存分配器的性能。那么TCMalloc的结构是怎样的呢?以后写一节进行分析(画个饼)
参考 Go 语言设计与实现 图解Go语言内存分配

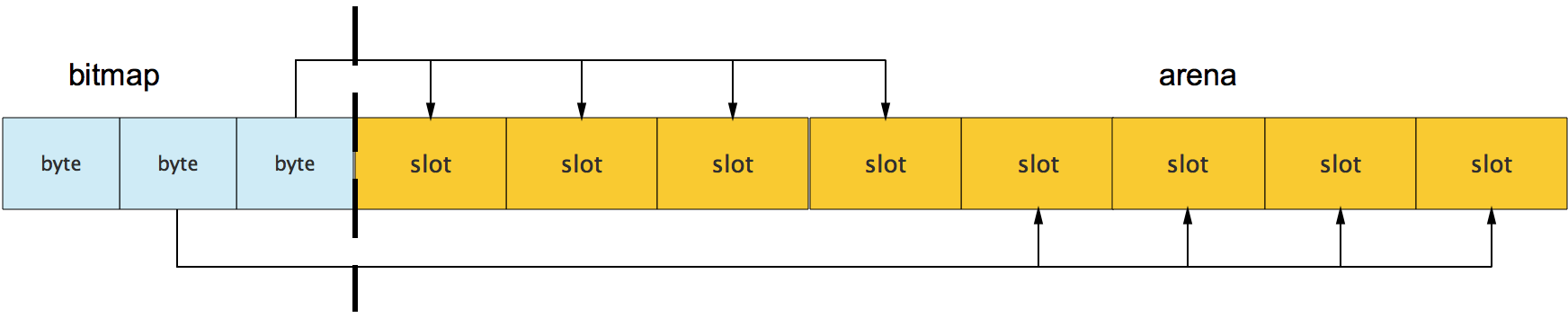 bitmap中一个byte对应4个指针(指针大小为8bit)的内存;bitmap的高地址部分指向arena的低地址部分;
bitmap中一个byte对应4个指针(指针大小为8bit)的内存;bitmap的高地址部分指向arena的低地址部分;