并发系列:2. Go 的长连接
TCP 连接的建立和关闭
绝大多数网络连接的建立都是基于 TCP 协议的,我们往往知道一个原则:建立 TCP 连接需要三次握手,其具体过程也是面试的一个常考点。那么“为什么 TCP 建立连接需要三次握手?”呢?这个问题很少深究。首先回顾一下建立连接的过程:
TCP 连接是什么?
连接:用于保证可靠性和流控制的信息,包括 Socket、序列号和窗口大小。其中:Socket 由互联网地址标志符和端口组成;窗口大小主要用来做流控制;最后的序列号用于追踪通信发起方发送的数据包序号,接收方可以通过序列号向发送方确认某个数据包的成功接收。 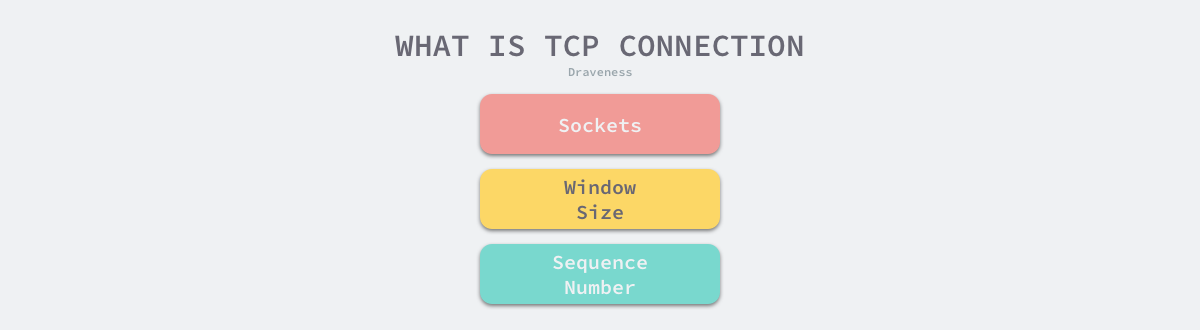
TCP 所有的协议状态如下图: 
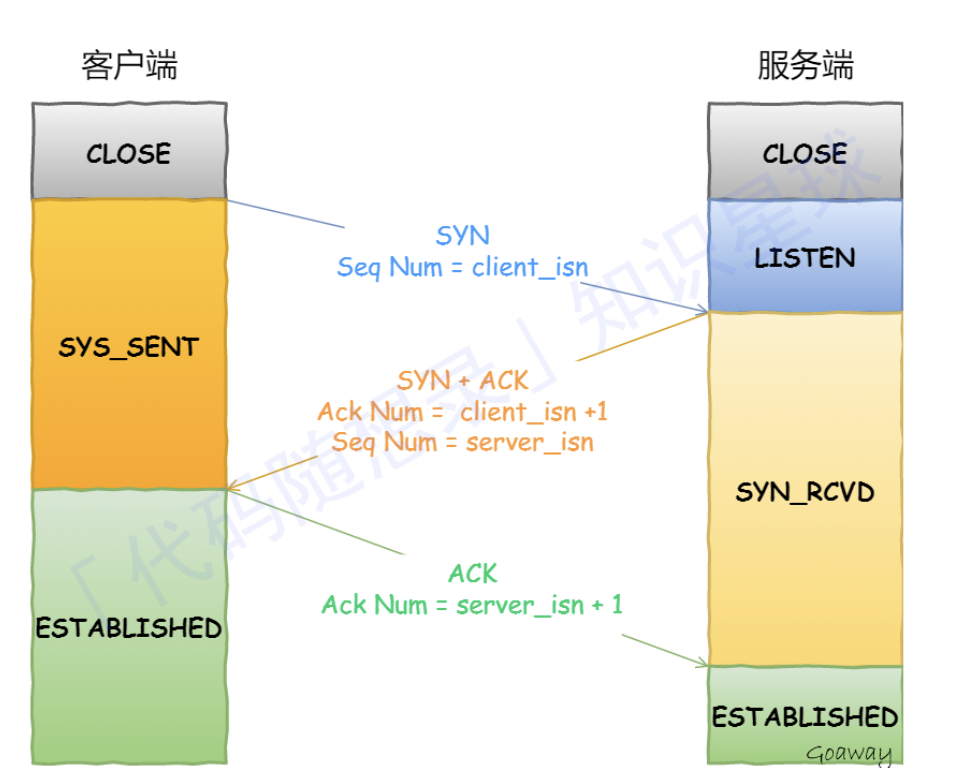
建立 TCP 连接的三次握手
抽象成通俗语言就是:
你能听到吗?
我能听到,你听得到吗?
我也能听到。
第一次握手:SYN 报文:客户端随机初始化序列号 client_isn,放进TCP⾸部序列号段,然后把SYN置1。把SYN报⽂发送给服务端,表示 发起连接,之后客户端处于 SYN-SENT状态。
第二次握手:SYN+ACK报⽂:服务端收到客户端的SYN报⽂之后,会把⾃⼰随机初始化的序号 server_isn放进TCP⾸部序列号段,「确认应答号」填⼊ client_isn + 1,把SYN和ACK标志位置为1。把SYN+ACK报⽂发送给客户端,然后进⼊ SYN-RCVD状态,表示服务器接受了客户端的请求,并希望建⽴连接。
第三次握手:ACK报文:客户端收到服务端报⽂后,还要向服务端回应最后⼀个应答报⽂。⾸先该应答报⽂ TCP ⾸部 ACK 标志位置为 1 ,其次确认应答号字段填⼊ server_isn + 1 ,最后把报⽂发送给服务端,这次报⽂可以。
服务器收到客户端的应答报⽂后,也进⼊ ESTABLISHED状态。
补充:
第三次握⼿是可以携带数据的,但是前两次握⼿是不可以携带数据的。
半连接(SYN队列):服务器第⼀次收到客户端的 SYN 之后,就会处于 SYN_RCVD状态,此时尚未建立连接,将此状态下的请求连接放在一个队列里。
全连接队列(Accept 队列):存放已经完成三次握手的连接。
SYN 攻击:攻击者发送⼤量伪造的 SYN 请求到⽬标服务器,但不完成后续的握⼿过程,从⽽让服务器⼀直等待确认,消耗服务器的资源(如半连接队列和系统资源);当半连接队列满了之后,后续再收到 SYN 报⽂就会丢弃,导致⽆法与客户端之间建⽴连接。
为什么一定是三次连接呢?
排除历史重复连接
TCP 连接使用三次握手的首要原因是:阻止历史的重复连接初始化造成的混乱问题,防止使用 TCP 协议通信的双方建立了错误的连接。
如果通信次数只有两次会怎么样呢?那么发送方一旦发出建立连接的请求之后,无法再撤回这一次请求。如果在网络状况复杂或者较差的网络中,发送方连续发送多次建立连接的请求,但接收方只能选择接受或者拒绝发送方发起的请求,它并不清楚这一次请求是不是由于网络拥堵而早早过期的连接。
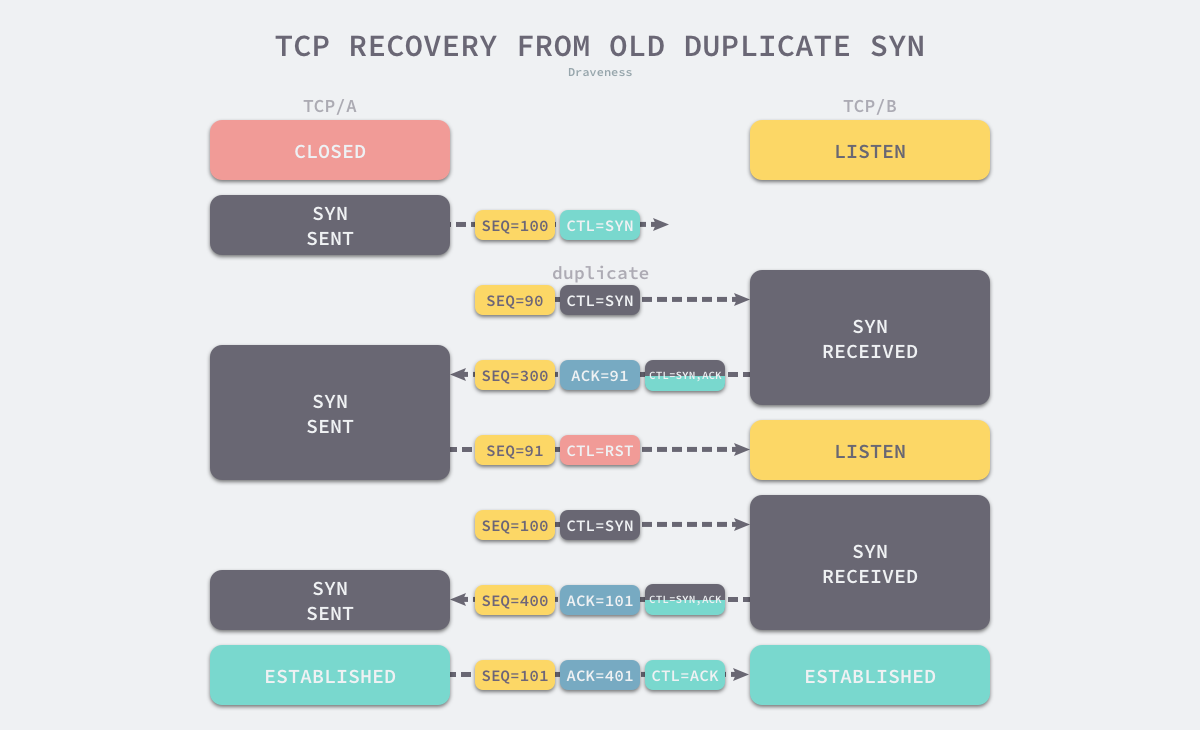
因此下图中,选择使用三次握手建立 TCP 连接,并引入 RST。第二次请求后发送方判断:
- 如果当前连接是历史连接(接收方返回的 ACK 报文中序列号不符合预期),即 Seq 过期或者超时:发送方就会直接发送 RST 控制消息中止这一次连接;
- 如果当前连接不是历史连接:发送方就会发送 ACK 控制消息,通信双方就会成功建立连接;
使用三次握手和 RST 控制消息将是否建立连接的最终控制权交给了发送方,因为只有发送方有足够的上下文来判断当前连接是否是错误的或者过期的。
同步双方的初始序列号
TCP 协议的通信双方,都必须维护一个序列号,以保证可靠传输,使得:
- 接收端可以去除重复数据;
- 发送端可以在对应数据包未被 ACK 时进行重复发送;
- 接收端可以根据数据包的序列号对它们进行重新排序。
它们都需要向对方发送 SYN 控制消息并携带自己期望的初始化序列号 SEQ,对方在收到 SYN 消息之后会通过 ACK 控制消息以及 SEQ+1 来进行确认。如下图: 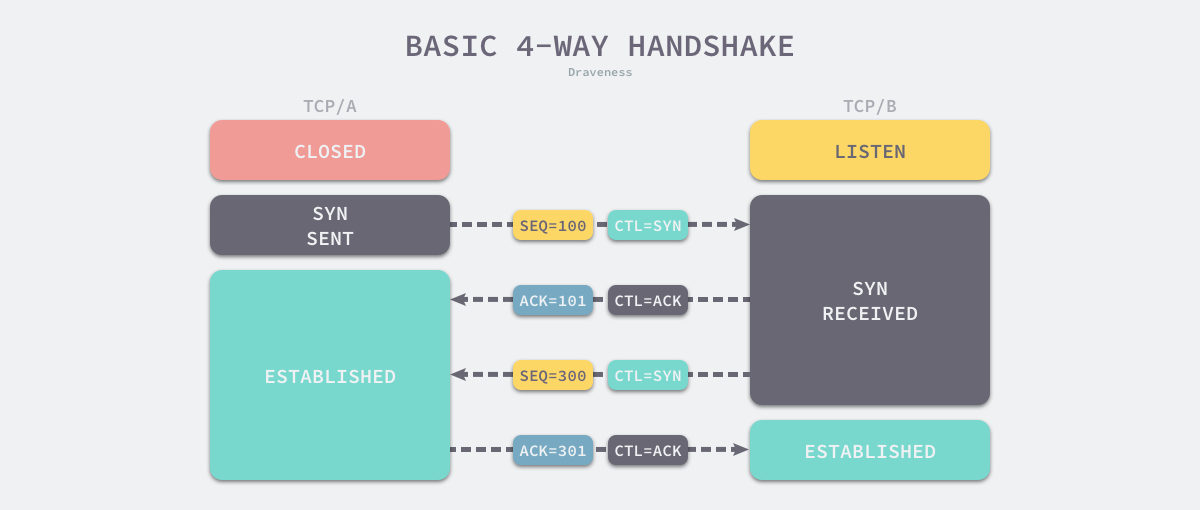 由于 TCP 消息头的设计,可以将中间的两次通信合成一个,TCP B 可以向 TCP A 同时发送 ACK 和 SYN 控制消息,帮助我们将四次通信减少至三次。
由于 TCP 消息头的设计,可以将中间的两次通信合成一个,TCP B 可以向 TCP A 同时发送 ACK 和 SYN 控制消息,帮助我们将四次通信减少至三次。
关闭 TCP 连接的四次挥手
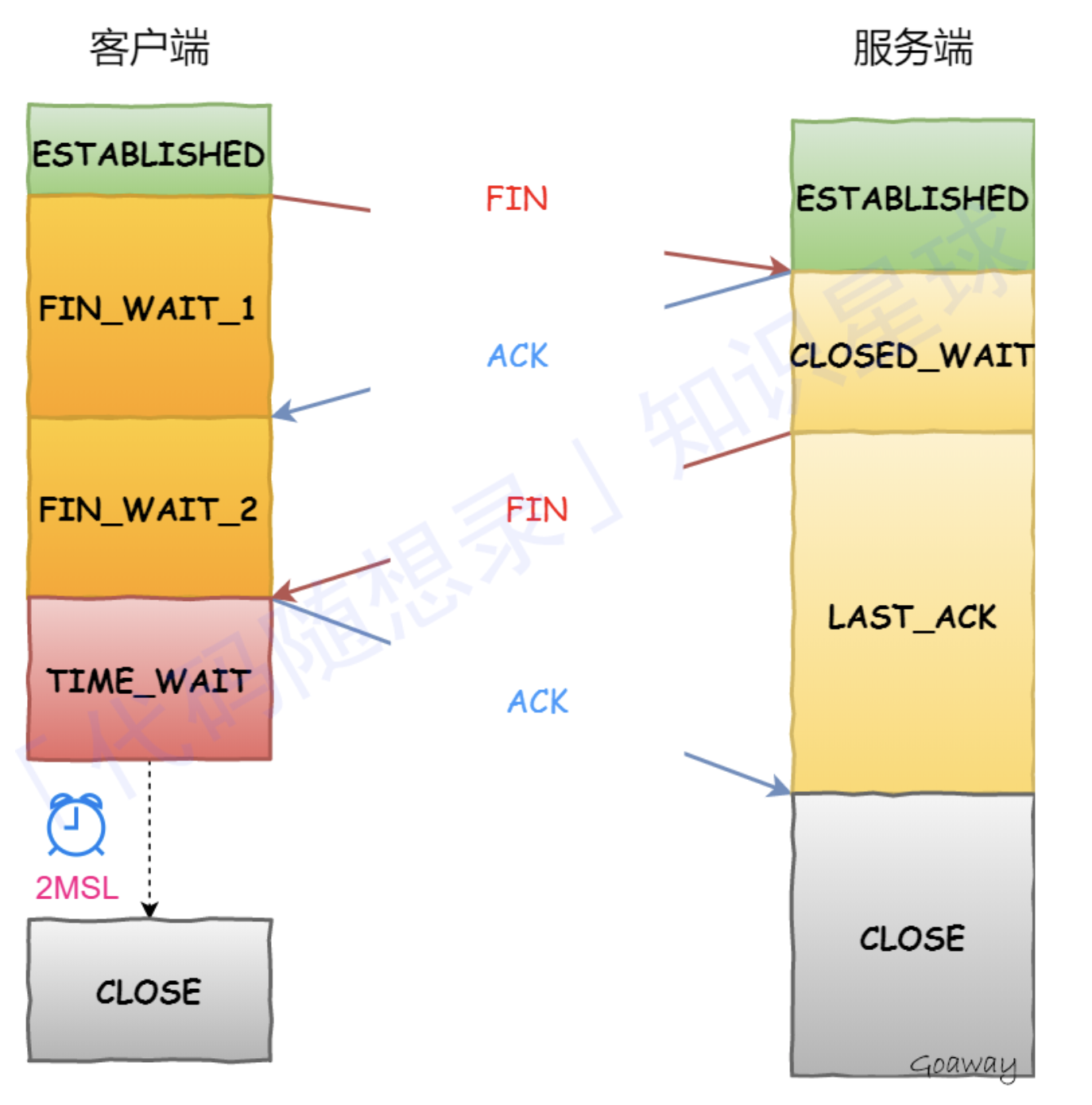 在挥⼿之前,客户端和服务器都处于 ESTABLISHED 状态。
在挥⼿之前,客户端和服务器都处于 ESTABLISHED 状态。
- 第一次挥手:FIN 报文:当客户端没有待发送的数据时,它会向服务端发送 FIN 消息,发送消息后会进入 FIN_WAIT_1 状态;
- 第二次挥手:ACK报文:服务端接收到客户端的 FIN 消息后,会进入 CLOSE_WAIT 状态并向客户端发送 ACK 消息,客户端接收到 ACK 消息时会进入 FIN_WAIT_2 状态;
- 第三次挥手:FIN 报文:待服务端处理完数据后,当服务端没有待发送的数据时,服务端会向客户端发送 FIN 消息,并进入 LAST_ACK 状态;
- 第四次挥手:ACK 报文:客户端接收到 FIN 消息后,会进入 TIME_WAIT 状态并向服务端发送 ACK 消息,服务端收到后会进入 CLOSED 状态;
- 客户端等待 2MSL 时间后,⾃动进⼊ CLOSE 状态,完成连接的关闭。
为什么需要 TIME_WAIT 状态呢?
可以发现被动断开连接的一方会直接进入 CLOSED 状态,TIME_WAIT 仅在主动断开连接的一方出现,。原因如下:
阻止延迟数据段被其他使用相同源地址、源端口、目的地址以及目的端口的 TCP 连接收到
每一个 TCP 数据段都包含唯一的序列号以保证 TCP 协议的可靠性和顺序性。因此需要保证新 TCP 连接的数据段不会与还在网络中传输的历史连接的数据段重复。 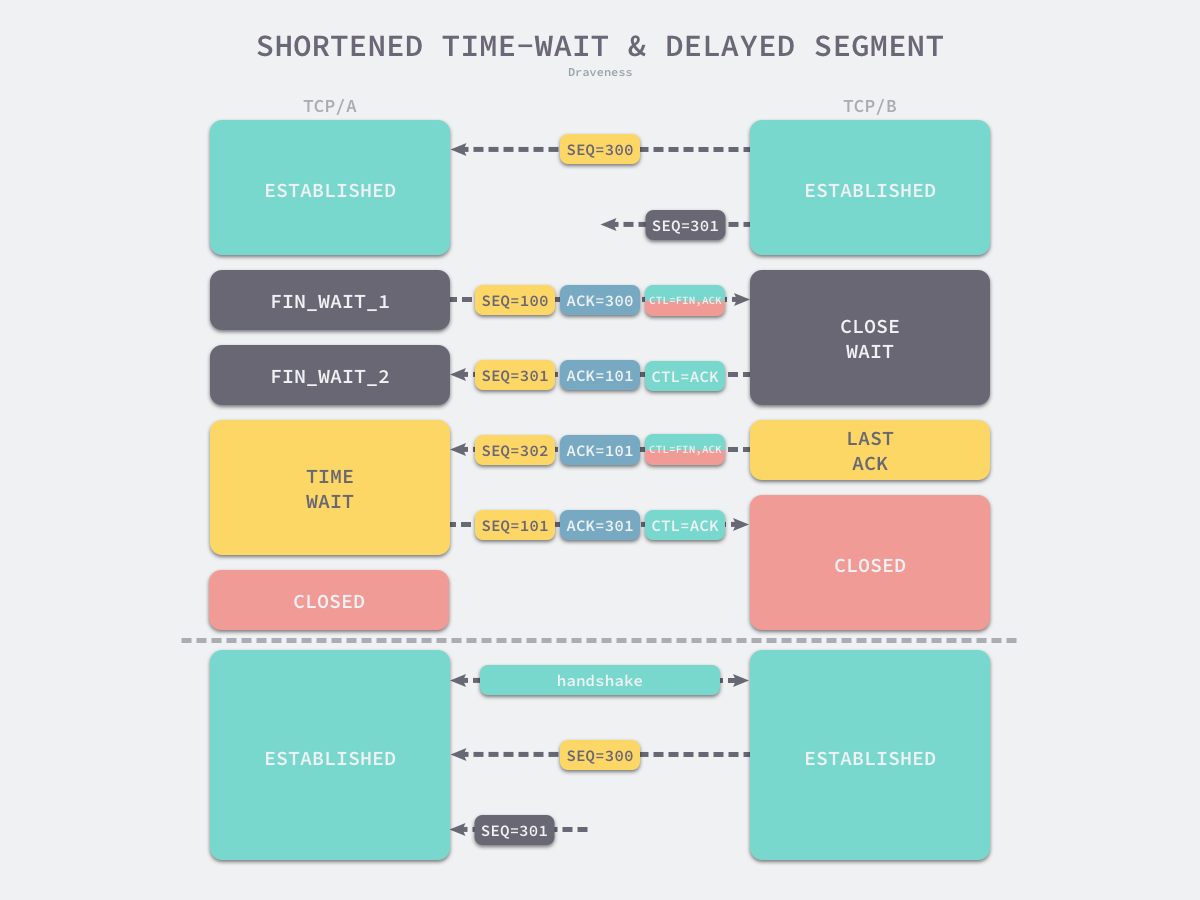
那么为什么是 2 倍 MSL 呢?一个合理解释是:网络中可能存在来自发起方的数据段,当这些发起方的数据段被服务端处理后又会向客户端发送响应,所以一来一回需要等待 2 倍的时间。
在 Linux 上,客户端的可以使用端口号 32,768 ~ 61,000,总共 28,232 个端口号与远程服务器建立连接,应用程序可以在将近 3 万的端口号中任意选择一个。
但是如果主机在过去一分钟时间内与目标主机的特定端口创建的 TCP 连接数超过 28,232,那么再创建新的 TCP 连接就会发生错误,也就是说如果我们不调整主机的配置,那么每秒能够建立的最大 TCP 连接数为 ~470。
保证连接关闭:确保被动关闭放收到其发出的终止连接消息 FIN 对应的 ACK
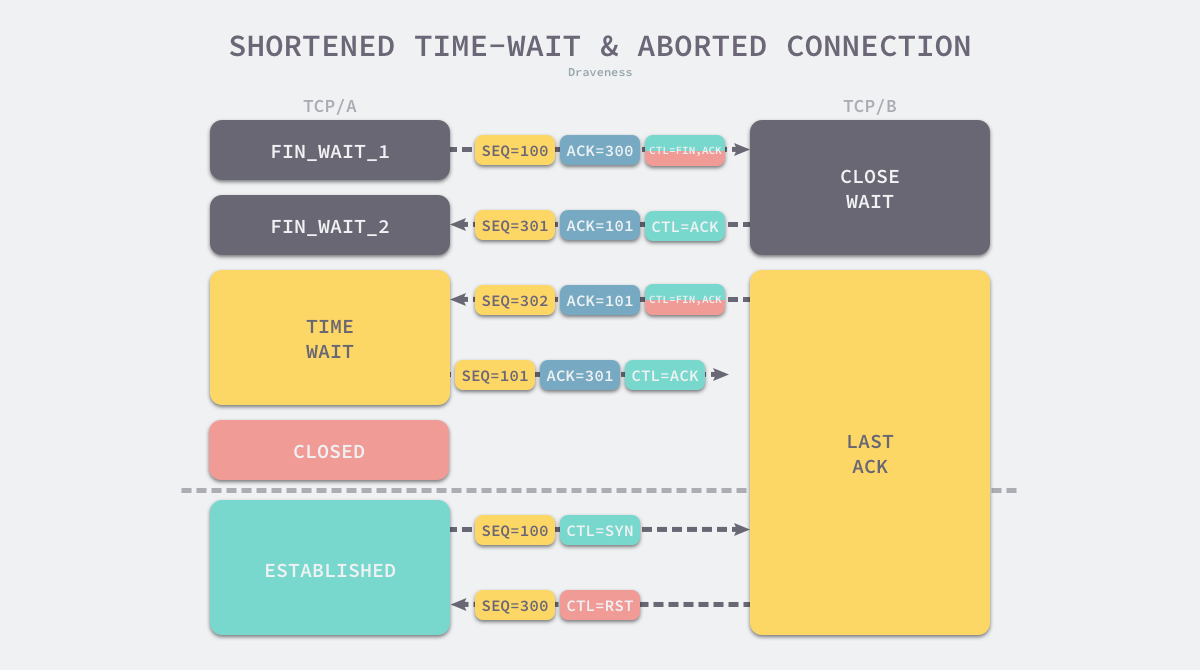 如果最后的⼀次ACK报⽂丢失(第四次挥⼿),客户端没有 TIME_WAIT 状态,直接进⼊ ClOSE。
如果最后的⼀次ACK报⽂丢失(第四次挥⼿),客户端没有 TIME_WAIT 状态,直接进⼊ ClOSE。
客户端重新与服务端建立 TCP 连接时,由于服务端没有收到 ACK 消息,所以仍然处于 LAST_ACK 状态,认为当前连接是合法的,客户端重新发送 SYN 消息请求握手时,会收到服务端的 RST 消息,连接建立的过程就会被终止。
为了解决这个问题,为什么等待的是2倍 MSL 时间呢?如果服务端没有收到 ACK,那么就会触发 TCP 重传机制,服务端会重新发送⼀个 FIN,这样⼀去⼀来刚好两个 MSL 的时间。
如果 TIME-WAIT 等待⾜够⻓的情况就会遇到两种情况:
- 服务端正常收到四次挥⼿的最后⼀个 ACK 报⽂,则服务端正常关闭连接。
- 服务端没有收到四次挥⼿的最后⼀个 ACK 报⽂时,则会重发 FIN 关闭连接报⽂并等待新的 ACK 报⽂。
在某些场景下,60 秒的等待销毁时间确实是难以接受的,例如:高并发的压力测试。当我们通过并发请求测试远程服务的吞吐量和延迟时,本地就可能产生大量处于 TIME_WAIT 状态的 TCP 连接。此时如何处理呢?
- 使用 SO_LINGER 选项并设置暂存时间 l_linger 为 0;在这时如果我们关闭 TCP 连接,内核就会直接丢弃缓冲区中的全部数据并向服务端发送 RST 消息直接终止当前的连接;
- 使用 net.ipv4.tcp_tw_reuse 选项,通过 TCP 的时间戳选项允许内核重用处于 TIME_WAIT 状态的 TCP 连接;
- 修改 net.ipv4.ip_local_port_range 选项中的可用端口范围,增加可同时存在的 TCP 连接数上限。
建立 TCP 连接的成本
梳理完三次握手和四次挥手的详细过程后可以发现:建立 TCP 连接具备一定的时间成本;其次,握手、挥手、发送数据都是从网卡发送出去和接收的,对于高并发系统,如果大量数据包都经历过这么上述程,CPU 资源成本较高;每个 socket 需要耗费系统缓存。
那么什么场景下应该采用怎样的 TCP 连接方式呢?
TCP 长连接和 TCP 短连接
长连接入服务同时支持客户端主动发起请求和服务器主动发起推送;短连接入服务则只支持客户端主动发起请求。
TCP 短连接
客户端与服务器建立连接开始通信,一次/指定次数通信结束之后就断开本次TCP连接;当下次再次通信时,再次建立TCP的链接。
优点:不长期占用服务器的内存,服务器能处理的连接数量是比较多的;
缺点:
- 因为等到要发送数据或者获取资源时,才去请求建立连接发送数据,因此服务器无法向客户端主动发送数据;需要等到客户端下一次请求数据时才发送。客户端需要采用轮询实时拉取信息。
TCP 长连接
客户端与服务器建立 TCP 连接之后一直保持连接状态,直到最后不再需要服务的时候才断开连接。
优点:传输数据快;服务器能够主动第一时间传输数据到客户端。
缺点:因为客户端与服务器一直保持这种连接,那么在高并发分布式集群系统中客户端数量会越来越多,占用大量系统资源;TCP本身是一种有状态的数据,在高并发分布式系统会导致后台设计比较复杂。
TCP 的 keepalive 机制
设计理念
- 客户端和服务器需要了解什么时候终止进程,或者与对方断开连接。
- 在另一些情况下,虽然应用进程之间无数据交换,但依然需要通过连接保持一个最小的数据流。
使用场景
服务端应用程序探测客户端是否离开:在建立 TCP 连接后,如果客户端没有关闭连接而是直接关闭主机(不发送 RST 取消连接),会在服务端留下一个半开放连接,服务器永久等待,占用系统资源。可以使用 keepalive 机制检测。
客户端通过 NAT 路由器连接并超时:NAT路由器,由于其硬件的限制(例如内存、CPU处理能力),无法保持所有连接,因此在必要的时候,会在连接池中选择一些不活跃的连接踢掉。需要在客户端离开时继续保持长连接时,可以使用 keepalive 机制,让连接每隔一小段时间就产生一些 ACK 包,降低被踢掉的风险。
实现
keepalive 功能在默认情况下关闭,可以由 TCP 连接的任何一端、或者两端打开。
- 如果在保活时间(keepalive time)内,连接处于非活跃状态,开启保活功能的一端向对方发送一个保活探测报文;
- 如果发送端没有收到 ACK 报文,经过一个保活时间间隔(keepalive internal),继续发送保活探测报文,直到发送次数达到保活探测数(keepalive probe);此时对方主机将被确认为不可达,连接中断。
保活探测报文:一个空报文段,序列号等于对方发送的 ACK 报文的最大序列号-1。探测和响应报文都不包含任何有效数据,丢失时不重传。
检测到的4种状态
开启 TCP 保活功能的一端发现对方处于以下4种状态之一:
- 对方主机正在工作,可以到达:收到 ACK 报文,请求端将保活计时器重置;每次有应用程序通过该连接传输数据时,再次重置。
- 对方主机已经崩溃,包括已经关闭或者正在重启:收不到 ACK 报文,一共发送保护探测数指定次数的探测报文,如果均未收到对应 ACK 报文,认为对方主机已经关闭,断开连接。
- 对方主机崩溃并已经重启:请求端收到一个 RST 报文,请求端断开连接。
- 对方主机正在工作,但由于某些原因不能到达请求端(例如网络传输问题):与状态2相同,无法区分。
如果对方主机正常关闭再重启(不同于主机崩溃):系统关机时,所有应用进程终止,会向请求端发送一个 FIN 报文以正常断开 TCP 连接。
第1种情况所有操作在 TCP 层完成,请求端的应用层无法察觉保活探测;第2,3,4种情况中,请求端的应用层将收到一个来自 TCP 层的差错报告。
TCP 层的实现
TCP 层心跳的开销较低,但检测精度相对较低,且受限于操作系统配置,可能无法满足所有应用需求;另外 TCP keepalive 与 TCP 协议绑定, 因此如果需要更换为 UDP 协议时, keepalive 机制会失效。
Linux 相关内核参数:
- tcp_keepalive_time:(单位:秒):发送探测报文之前的链接空闲时间,默认为7200;
- tcp_keepalive_intvl:(单位:秒):两次探测报文发送的时间间隔,默认为75; tcp_keepalive_probes::探测次数,默认为9。
应用层的实现:netty
源码:https://github.com/dongyusheng/csdn-code/tree/master/heartbeat
net/http
Go 语言实现了 HTTP/1.1 和 HTTP/2.0 协议:标准库通过net/http 包提供 HTTP 客户端和服务端实现。
HTTP 协议的协议头是文本数据,包含协议版本、状态码、响应头和负载:
1 | GET / HTTP/1.1 |
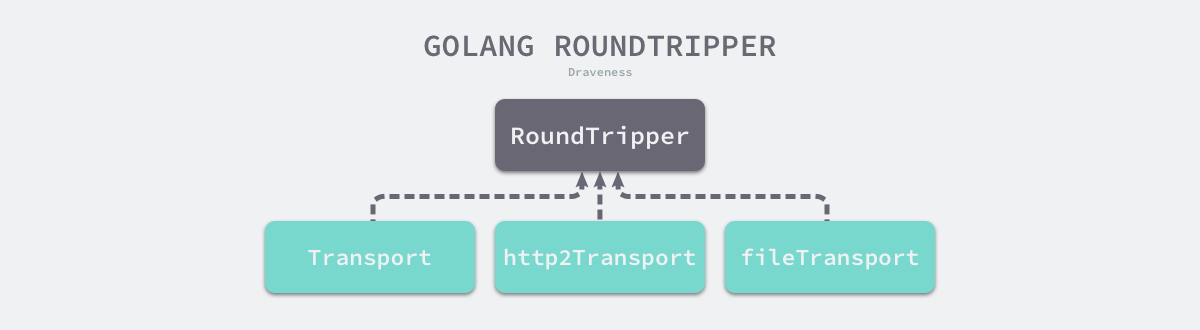
层级结构如下:
调用方实现
net/http.RoundTripper接口:向远程发出请求并获取响应。1
2
3type RoundTripper interface {
RoundTrip(*Request) (*Response, error)
}
接收方实现
net/http.Handler接口:处理 HTTP 请求,为客户端的 HTTP 请求提供不同的服务;处理过程中调用net/http.ResponseWriter接口的方法构造 HTTP 响应,它提供的三个接口 Header、Write 和 WriteHeader 分别会获取 HTTP 响应、将数据写入负载以及写入响应头:1
2
3
4
5
6
7
8
9type Handler interface {
ServeHTTP(ResponseWriter, *Request)
}
type ResponseWriter interface {
Header() Header
Write([]byte) (int, error)
WriteHeader(statusCode int)
}
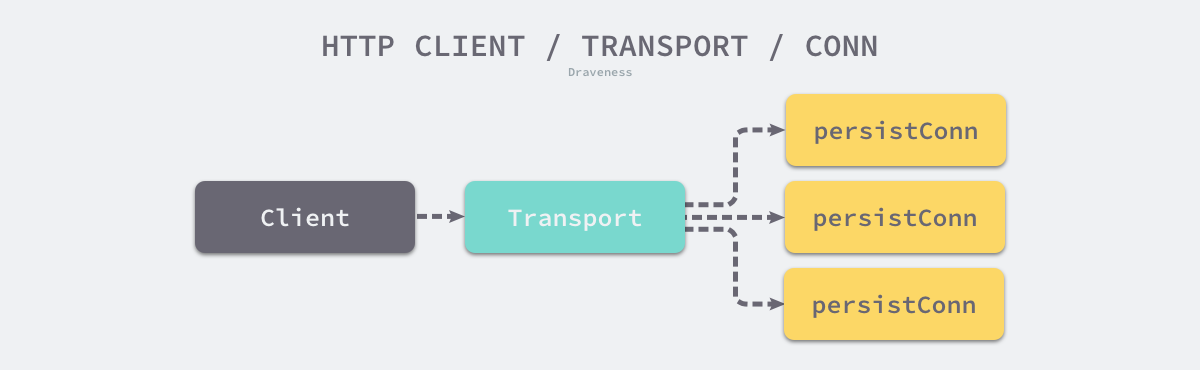
net/http.Client 是 HTTP 客户端(默认使用 net/http.DefaultTransport,没有超时时间):可发起 HTTP 请求。
- 尽量复用而非频繁创建:
Transport具备内部状态(缓存的 TCP 连接等),不方便频繁销毁和创建;Client是线程安全的,可以被多个 goroutine 并发使用。- 重定向时的头部处理规则:敏感头部("Authorization"、"WWW-Authenticate"、"Cookie")只有当重定向目标域是初始域的子域或完全匹配时才转发("foo.com" -> "foo.com" 或 "sub.foo.com":会转发敏感头部;"foo.com" -> "bar.com":不会转发敏感头部)
1 | type Client struct { |
对于高并发服务,如何管理若干个连接呢?Go 中实现了连接池,帮助完成连接的建立、复用、回收等工作。在设计与实现时,通常需要考虑以下几个问题:
- 连接池的最大连接数目是多少呢?
- 连接长时间未使用,如何设置触发回收的条件呢?
- 如果连接池无空闲连接,业务是否需要阻塞等待呢?
- 如果进行排队,那么队列的长度和排队时间分别是多少呢?
为了回答以上问题,先深入 Go 连接池的源码:
Transport 原理
net/http/transport.go中的Transport struct继承并实现 实现了http.RoundTripper接口,负责 http 的请求分发,以及对空闲连接的管理。
1 | type RoundTripper interface { |
Transport 结构体如下:
1 | type Transport struct { |
注意:MaxIdleConnsPerHost默认等于2,即当前客户端与目标主机最多只维护两个空闲连接。
Transport.roundTrip
Transport.roundTrip是主入口,传入一个request参数,选择一个合适的长连接来发送该 request 并返回 response。
1 | func (t *Transport) roundTrip(req *Request) (*Response, error){ |
getConn:为一个 HTTP 请求获取一个可用的底层 TCP/TLS 连接
getConn 优先尝试从空闲连接池中复用;如果没有则创建新连接,同时处理各种超时和取消逻辑。
1 | // getConn 拨号并创建一个新的 persistConn 到 connectMethod 指定的目标。 |
小结:
getConn为一个 HTTP 请求获取一个可用的底层 TCP/TLS 连接,优先复用空闲连接池中的连接。包含以下关键策略:
- 上下文分离:创建独立的 dialCtx,使拨号过程不受原始请求取消的影响,避免浪费已建立的连接;
- 连接获取策略:优先使用
queueForIdleConn尝试从空闲池获取可用连接;失败则使用queueForDial启动异步拨号;- 资源管理:妥善处理拨号创建但未被使用的连接,将其转入资源池,避免浪费。
这个方法完美体现了 Go 并发模型的优势:使用 Goroutine 进行异步操作,使用 Channel 进行通信和同步,使用 Select 进行多路事件监听,最终构建出一个高效且健壮的连接管理机制。
总结一下 transport 连接池流程:
transport 中维护了一个空闲连接池 idleConn map[connectMethodKey][]*persistConn,其中的每个成员都是一个persistConn对象(即一个具体的连接实例,包含了连接的上下文),会启动两个 groutine 分别执行readLoop和writeLoop;
每当transport调用roundTrip的时候:
从连接池中选择一个空闲的
persistConn,调用其roundTrip方法,将读写请求通过channel分别发送到readLoop和writeLoop中;select监听各个channel的信息,包括连接关闭、请求超时、writeLoop出错、readLoop返回读取结果等;在writeLoop中发送请求,在readLoop中获取 response 并通过 channel 返回给roundTrip;并再次将自己加入到idleConn中,等待下次请求到来。
Transport 连接池的使用
- 初始化客户端(可以自定义 client 和 transport 的参数):
1 | type Client struct { |
- 创建 HTTP 请求并发送
1 | // httpRequest http请求 |
为什么需要
httpResp.Body.Close()呢?如果返回值
httpResp.Body未关闭,client下层的RoundTripper接口(一般为Transport类型)可能无法重用httpResp.Body下层保持的 TCP 连接去执行之后的请求。所以它的作用就是用来确保 Body 读干净,释放出该连接。不这么做的危害是什么呢?
- 当前 TCP 连接未回收,无法复用;
readLoop和writeLoop两个 goroutine 在 写入请求并获取 response 返回后,并没有跳出 for 循环,而继续阻塞在下一次 for 循环的 select 语句里面,goroutine 一直无法被回收,cpu 和 memory 全部打满。发生 goroutine 内存泄漏; 对方关闭了连接(向客户端发送了FIN),如果不调用response.Body.Close(),那么与这个请求相关的 TCP 连接的状态一直处于CLOSE_WAIT状态,不会被系统回收,文件描述符不会被释放,出现资源泄漏。
注意 SSRF 漏洞:
使用"net/http"下的方法
http.Get(url)、http.Post(url, contentType, body)、http.Head(url)、http.PostForm(url, data)、http.Do(req)时,如变量值外部可控(指从参数中动态获取),应对请求目标进行严格的安全校验。一个栗子:来源于用户请求的 URL 路径
path := r.URL.Path是不可信输入(污点)。直接拼接targetURL := "http://" + address + path并用于构建请求newReq, err := http.NewRequest(r.Method, targetURL, bytes.NewBuffer(body))。攻击者可能构造恶意 path 实现 开放重定向 或 服务端请求伪造(SSRF)。
Go 长连接服务在高并发场景下的优化
先看一个服务端采用原生 net 库实现长连接服务访问的例子,包括以下关键步骤:
- 建立 TCP 连接:使用
net.Listen监听端口,接受客户端连接;每个连接在一个独立的 Goroutine 中处理。 - 维护连接状态:使用
sync.Map或map存储所有活跃的连接;定期检查连接状态,清理断开的连接。 - 处理数据读写:使用
bufio.Reader和bufio.Writer高效地读写数据;使用协议(如 JSON、Protobuf)序列化和反序列化数据。 - 实现心跳机制:客户端定期发送心跳包,服务器检测心跳以判断连接是否存活。
- 处理连接超时:使用
net.Conn的SetReadDeadline和SetWriteDeadline方法设置超时时间;如果超过指定时间没有读写操作,连接会自动关闭。
1 | package main |
Go 的 Net 库提供简单的非阻塞调用接口,网络模型采用一个连接一个协程(Goroutine-per-Connection)。普通场景下易用,但对于百万连接级别的高并发场景,为每个连接分配一个协程将消耗极大的内存,并且调度大量协程也将十分困难。因此必须打破一个连接一个协程模型,tRPC-Go 的高性能网络库 tnet 基于事件驱动(Reactor)的网络模型,能够提供百万连接的能力。
net:一个连接一个协程
在传统的一个连接一个协程模式下,服务端每 Accept 个新连接就会为该连接创建一个独立的协程。在这个协程中完成从连接读取数据、处理业务逻辑、向连接写入数据的完整流程。这种模式在连接数较少时工作良好,但在百万级长连接场景下存在严重问题。
百万连接场景中,虽然连接总数巨大,但活跃连接(有数据可读写的连接)通常只占少数,大部分连接处于空闲状态(无数据读写)。空闲连接的协程会阻塞在Read调用上,虽然不占用CPU调度资源,但每个协程仍然需要占用一定的内存资源。在百万连接规模下,这种内存消耗变得极其巨大,导致成本昂贵。
tnet:事件驱动模型
事件驱动模式是指利用多路复用(epoll / kqueue)监听 FD 的可读、可写等事件,该模型的核心是Poller结构,每个Poller运行在一个独立的协程中,Poller数量通常等于CPU核心数。
在这种架构下,采用单独的 Poller 监听 listener 端口的可读事件来 Accept 新连接;其他Poller负责监听所有连接的可读事件。当连接变得可读时,才为该连接分配协程进行处理:读取数据、处理业务、写入响应。这种设计确保只有活跃连接才会占用协程资源。
具体执行过程中,Poller检测到可读事件后,为每个可读连接分配处理协程。由于已知连接可读,Read操作不会阻塞,整个处理流程可以顺利执行;在 Write 阶段,向Poller注册可写事件后协程即可退出,由Poller在连接可写时完成数据发送,从而完成一轮完整的数据交互。
这种事件驱动模式在百万连接场景下显著降低了内存占用,通过只为活跃连接分配协程的方式实现了资源的高效利用,解决了传统模式的内存瓶颈问题。
适用场景
作为服务端使用 tnet,客户端发送请求使用多路复用的模式:可以充分发挥 tnet 批量收发包的能力,可以提高 QPS,降低 CPU 占用;
作为服务端使用 tnet:存在大量的不活跃连接的场景,可以通过减少协程数等逻辑降低内存占用;
作为客户端使用 tnet,开启多路复用模式:可以充分发挥 tnet 批量收发包的能力,可以提高 QPS。
参考
UNP编程:21---套接字选项之(套接字选项简介与接口:getsockopt、setsockopt)
工作了5年,你真的理解Netty以及为什么要用吗?(深度干货)
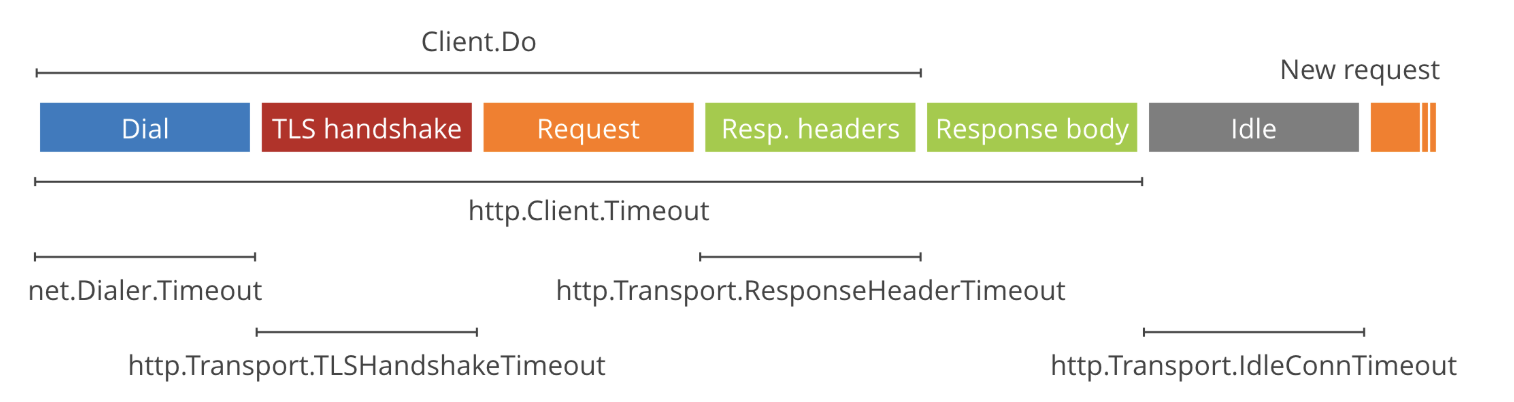
The complete guide to Go net/http timeouts
